访问量 次
访客数 人
Netty是一个高性能、异步的网络应用框架,用于开发高效的网络通信程序。它是Java NIO的一个抽象,简化了网络编程的复杂性,并提供了一系列高级功能,使网络编程变得更简单。
Netty是一个高效的网络框架,专注于处理大量并发连接。它通过异步IO处理来避免阻塞,这让它在处理高并发时表现出色。
Netty还利用了优化的内存管理和零拷贝技术,降低了性能开销。框架的灵活性也很高,开发者可以通过管道机制自定义数据处理流程,API和文档丰富,帮助简化网络编程。
不过,Netty的学习曲线可能较陡,对于不熟悉网络编程的开发者来说,理解和使用它可能需要一些时间。虽然框架提供了很多抽象,底层控制和调试可能会有一定的复杂性。
为了实现最佳性能,可能还需要对Netty的工作原理有深入了解。总的来说,Netty适合需要高性能和高并发的应用场景,如高性能HTTP服务器、实时消息系统、游戏服务器、代理服务器以及数据传输处理。
网络编程采用传统的阻塞IO模型。在这种模型中,每个IO操作会阻塞线程,直到操作完成。为了处理多个连接,通常需要为每个连接创建一个线程。 这个方式虽然简单,但在处理大量并发连接时效率低,因为线程的创建和销毁开销大,而且线程会在等待IO操作完成期间无法执行其他任务,导致资源利用不充分,系统扩展性差。
Reactor模型的出现是为了改进传统IO模型中的问题。通过引入事件驱动机制和非阻塞 IO,Reactor模型提高了处理并发IO操作的效率。
事件循环机制允许单个线程同时处理多个IO操作,而非阻塞IO避免了线程在等待数据时的阻塞状态。这种设计改进了资源利用率和系统响应速度,适应了高并发环境的需求。
Netty在Reactor模型的基础上进行了进一步的优化和扩展。它通过异步编程技术和管道机制提升了性能和开发效率。
Netty的事件循环机制经过优化,减少了线程和上下文切换的开销。管道机制将数据处理分解为多个阶段,使得网络应用的开发更加灵活和高效。
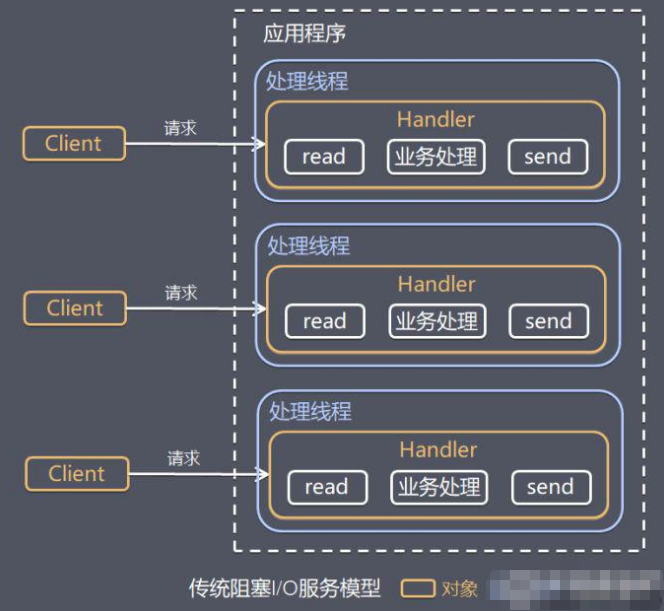
在阻塞IO模型中,线程在执行IO操作时会被阻塞,直到操作完成。例如,当一个线程发起读操作时,它会一直等待数据到达,无法处理其他任务。 这种模型简单易理解,但在高并发环境下,可能会导致大量的线程阻塞和上下文切换,从而降低系统的性能。
传统IO模型通常使用阻塞方式处理IO操作,其中每个IO请求都会分配一个线程,该线程在等待数据传输时会被阻塞。 这种方式简单易理解,但在高并发环境下,线程的创建、销毁和上下文切换开销较大,导致性能问题。每个线程的阻塞状态使得系统资源利用效率低,处理大量并发连接时表现不佳。
相比之下,Reactor IO模型采用非阻塞方式,通过事件循环和回调机制来处理IO操作。在这个模型中,单个或少量线程通过事件循环机制监听和分发IO事件,避免了线程的阻塞。
这样线程可以在等待IO操作的同时处理其他任务,大幅提高了系统的性能和资源利用效率。Reactor模型利用事件多路复用技术,能够在高并发环境下高效地管理大量连接和IO操作,适用于需要处理大量并发请求的应用场景。
Reactor模型是一种高效处理并发IO操作的设计模式,主要依赖事件驱动机制和非阻塞IO。
它基于IO复用模型,多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象等待,无需阻塞等待所有连接。 当某个连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
Netty主要基于主从Reactor多线程模型做了一定的改进。
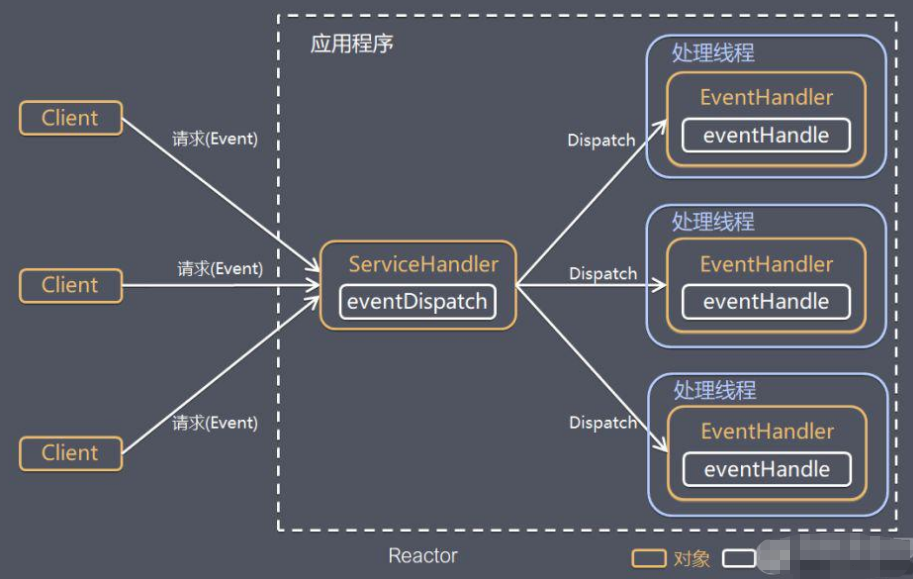
为了避免浪费创建了一个线程池,当客户端发起请求时,通过DispatcherHandler进行分发请求处理到线程池,线程池中在使用具体的线程进行事件处理。
服务器端程序处理传入的多个请求,并将它们同步分派到相应的处理线程,因此Reactor模式也叫Dispatcher模式。
Reactor模式使用IO复用监听事件,收到事件后,分发给某个线程,这点就是网络服务器高并发处理关键。
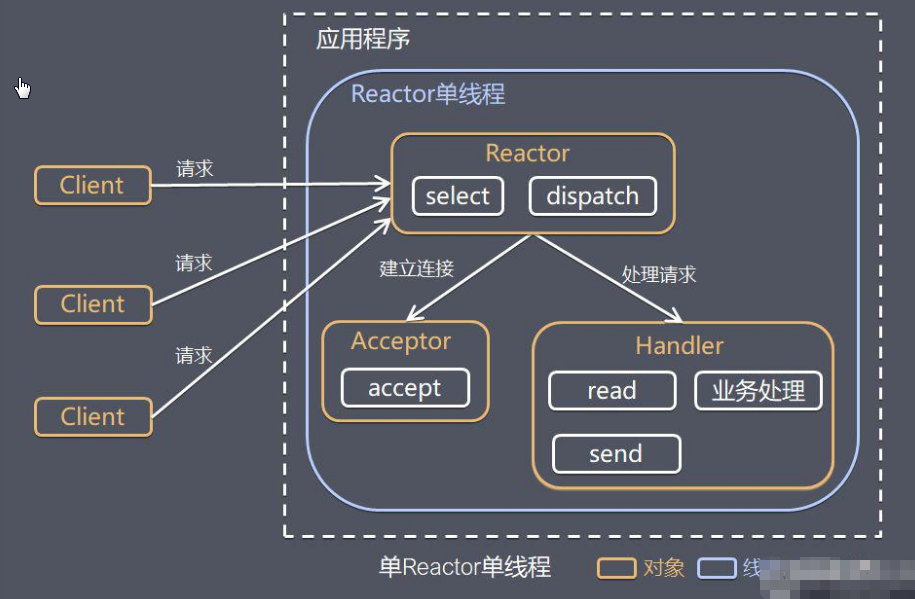
工作原理:
Reactor对象通过Select监控客户端请求事件,收到事件后通过Dispatch进行分发;Acceptor通过Accept处理连接请求,然后创建一个Handler对象处理连接完成后的后续业务处理;Reactor会分发调用连接对应的Handler来响应;Handler会完成 Read → 业务处理 → Send 的完整业务流程;单Reactor单线程模型的优点在于其简单性和高效的资源利用。由于只有一个线程负责处理所有的IO事件,这种模型避免了多线程管理的复杂性,减少了上下文切换和线程开销,使得系统资源消耗较少。
在低并发环境下,这种模型可以有效地处理IO操作,降低了系统的复杂性和开发难度。
这个模型的局限性包括处理能力的限制。在高并发场景中,单线程可能成为性能瓶颈,无法处理大量的并发请求。此外,如果某个IO操作发生阻塞,可能会影响到其他事件的处理,导致整体系统性能下降。
单Reactor单线程模型适用于连接数目较少、负载不高的应用场景,例如小型网络服务或低并发的应用。在处理高并发、大流量的应用时,可能需要使用多 Reactor 或多线程模型,以更好地满足性能需求。
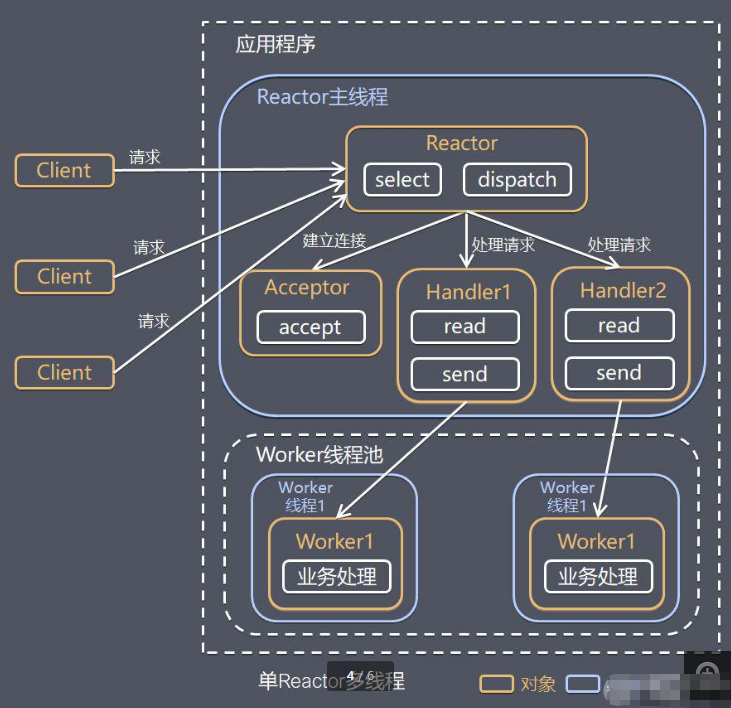
工作原理:
Reactor对象通过对select监听请求事件,收到请求事件后交给Dispatch进行转发;accept处理连接请求,然后创建一个handler对象处理完成连接后的事件;handler对象;handler只负责响应事件,不做具体的业务处理,通过read读取完后,分发给下面的 worker线程池中某个线程处理;worker 线程负责处理具体业务,处理完成后会将具体的结果返回给handler;handler线程通过send方法返回给客户端;单Reactor多线程模型通过引入多个工作线程来处理IO操作,能够更好地利用多核CPU的资源,提升了系统的并发处理能力和整体性能。
但是Reactor对象在处理所有事件的监听和响应都是单线程的,在高并发场景容易出现性能瓶颈。
Reactor主线程可以对应多个Reactor子线程,即MainRecator可以关联多个SubReactor,从而解决了Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈。
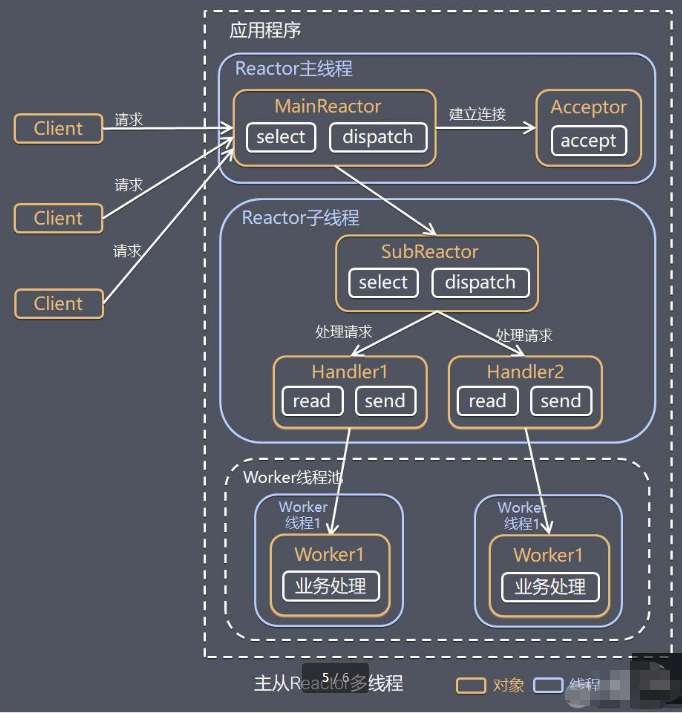
工作原理:
Reactor主线程MainReactor对象通过select监听连接事件,收到事件后,通过Acceptor处理连接事件;Acceptor处理连接事件后,MainReactor 将连接分配给SubReactor;SubReactor将连接加入到连接队列进行监听,并创建handler进行各种事件处理;SubReactor就会调用对应的handler处理;handler只负责响应事件,不做具体的业务处理,通过read读取完后,分发给下面的worker线程池中某个线程处理;worker线程负责处理具体业务,处理完成后会将具体的结果返回给handler;handler线程通过send方法返回给客户端;主从Reactor多线程模型在Reactor架构中进一步优化了性能和扩展性。在这种模型中,主Reactor线程负责监听和接收所有IO事件,而从Reactor线程池则处理具体的事件和业务逻辑。
通过将事件的监听和处理分离,主Reactor线程可以专注于高效地接受新的连接和事件,而从Reactor线程池则可以并行处理实际的IO操作。这种设计充分利用了多核CPU的资源,显著提升了系统的并发处理能力和响应速度。
这种模型在许多项目中广泛使用,包括 Nginx主从Reactor 多进程模型,Memcached主从多线程,Netty主从多线程模型的支持。
尽管该模型的实现复杂度增加,但它在处理大量并发请求时提供了卓越的性能和扩展性。
Netty的线程模型设计旨在高效处理大量并发连接,并最大限度地利用CPU资源。其核心思想是将IO操作和业务逻辑处理分开,通过线程池和事件循环机制实现异步处理。
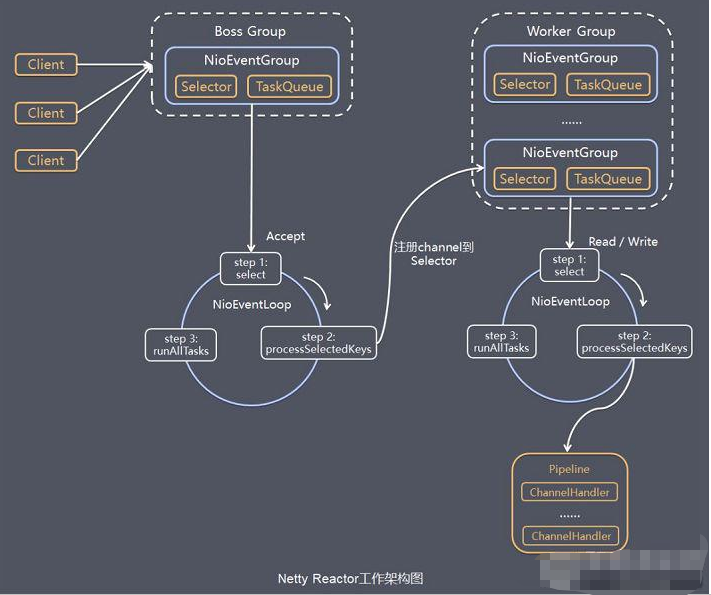
Netty的线程模型设计高效地支持大规模并发网络通信。核心包括两个主要类型的线程:
Boss Thread):主要负责监听和接受新的网络连接。Netty中的ServerBootstrap配置了一个或多个主事件循环线程,这些线程负责绑定网络端口并接收客户端的连接请求。当新的连接到达时,主线程会将这些连接注册到工作事件循环线程上进行进一步处理。Worker Thread):负责处理已经建立连接的IO操作,包括读取和写入数据。每个连接的IO操作由工作线程负责处理,这些线程通常以线程池的形式存在,可以并行处理多个连接的IO事件。Netty允许为工作线程配置多个线程组,从而能够高效地处理大量并发请求。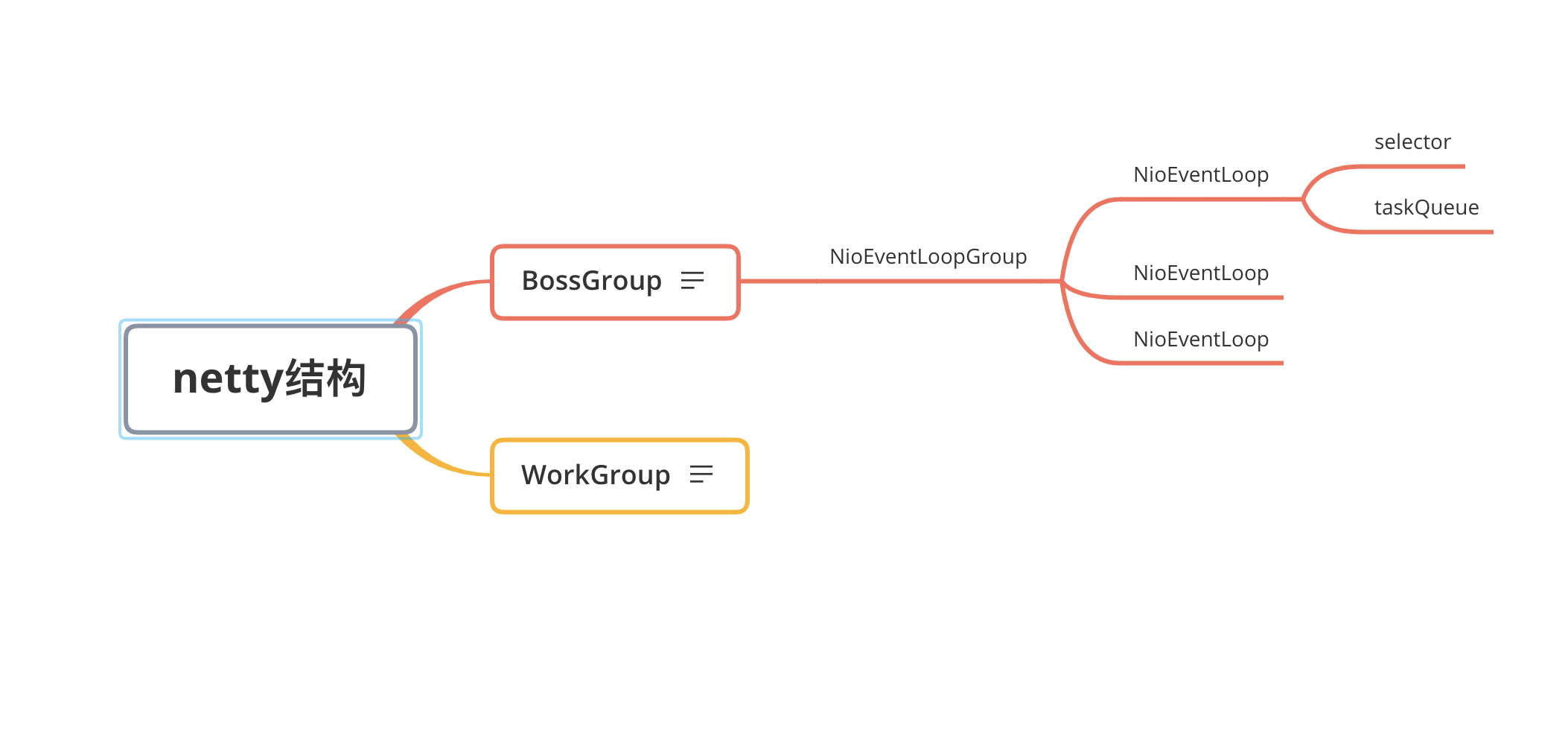
工作流程:
Netty抽象出两组线程池 BossGroup专门负责接收客户端的连接,WorkerGroup专门负责网络的读写;BossGroup和WorkerGroup类型都是NioEventLoopGroup;NioEventLoopGroup相当于一个事件循环组,这个组中含有多个事件循环,每一个事件循环是NioEventLoop,每个NioEventLoop都有一个Selector,用于监听绑定在其上的socket的网络通讯;NioEventLoopGroup可指定多个NioEventLoop;BossNioEventLoop循环执行的步骤:
accept事件;accept事件,与client建立连接,生成NioSocketChannel,并将其注册到某个workerNioEventLoop上的Selector;runAllTasks;WorkerNioEventLoop循环执行的步骤:
read,write事件;read,write事件,在对应NioSocketChannel处理;runAllTasks;WorkerNioEventLoop处理业务时,会使用pipeline,pipeline中包含了channel,即通过pipeline可以获取到对应通道,管道中维护了很多的处理器;
Bootstrap/ServerBootstrap: Bootstrap 用于客户端的启动配置,指定服务器地址、端口等参数。ServerBootstrap 用于服务端配置,处理客户端连接请求。这两个组件通过 EventLoopGroup 配置 IO 线程池,管理网络 IO 操作的线程资源。EventLoopGroup: 这个组件管理着多个 EventLoop 实例,每个 EventLoop 负责处理网络 IO 操作。EventLoopGroup 通过线程池分配线程给 EventLoop,使得网络事件的处理更加高效。启动工具通过 EventLoopGroup 配置和管理这些线程池。EventLoop: EventLoop 是一个单线程的组件,处理多个 Channel 的网络 IO 操作。每个 EventLoop 负责处理自己的 Channel 读写任务,减少了线程切换的开销,提升了 IO 操作的效率。Channel: Channel 代表一个网络连接,用于数据的发送和接收。每个 Channel 由一个 EventLoop 进行管理。Channel 使用 ChannelPipeline 处理数据流,负责实际的数据传输工作。ChannelPipeline: ChannelPipeline 是 Channel 内的数据处理链。它包含多个 ChannelHandler,按顺序处理传入和传出的数据。数据流通过 ChannelPipeline 进行一系列处理,执行编解码、业务逻辑等操作。ChannelHandler: ChannelHandler 是处理数据的组件,执行特定的逻辑,如编解码、业务处理等。它们被添加到 ChannelPipeline 中,并按顺序处理数据流。每个 ChannelHandler 处理完数据后,将结果传递给下一个 ChannelHandler。ByteBuf: ByteBuf 是用于高效存储和处理数据的缓冲区。与传统的 Java NIO 缓冲区相比,它支持动态扩展和更高效的内存管理。ByteBuf 用于存储和操作网络传输的数据,提升了数据处理的性能。ChannelFuture: ChannelFuture 表示一个异步操作的结果。它跟踪操作的状态,允许查询操作是否完成,并在操作完成后执行回调。ChannelFuture 提供了获取操作结果和处理异步操作的机制。ChannelPromise: ChannelPromise 是 ChannelFuture 的一个特定形式,表示异步操作的结果。与 ChannelFuture 类似,它允许设置操作的完成状态或异常,并通知其他组件操作的结果,用于异步操作完成后的结果通知。ByteBufAllocator: ByteBufAllocator 负责创建和管理 ByteBuf 实例。它提供了多种缓冲区分配方法,以满足不同性能需求。这个组件帮助高效管理 ByteBuf 的创建和释放,优化内存使用。FutureListener: FutureListener 是一个接口,用于监听 ChannelFuture 的完成状态。当异步操作完成时,FutureListener 执行特定的回调逻辑,处理操作结果或异常,提供了处理异步操作结果的机制。Callback Handler: Callback Handler 处理 FutureListener 的回调。当异步操作完成后,Callback Handler 接收回调通知,并执行相应的业务处理逻辑,确保操作结果能够被适当地处理。Bootstrap作为整个Netty客户端和服务端的程序入口,可以把Netty的核心组件像搭积木一样组装在一起。Netty服务端的启动过程大致分为三个步骤:
Netty 是采用 Reactor 模型进行开发的,可以非常容易切换三种 Reactor 模式:单线程模式、多线程模式、主从多线程模式。
Reactor单线程模型所有IO操作都由一个线程完成,所以只需要启动一个EventLoopGroup即可。
EventLoopGroup group = new NioEventLoopGroup(1);
ServerBootstrap b = new ServerBootstrap();
b.group(group)
Netty中使用Reactor多线程模型与单线程模型非常相似,区别是NioEventLoopGroup可以不需要任何参数,它默认会启动2倍CPU核数的线程。当然你也可以自己手动设置固定的线程数。
EventLoopGroup group = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(group)
Boss是主Reactor,Worker是从Reactor。它们分别使用不同的NioEventLoopGroup,主Reactor负责处理Accept,然后把Channel注册到从Reactor上,从Reactor主要负责Channel生命周期内的所有IO事件。
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
Channel初始化;
Channel类型:NIO模型是Netty中最成熟且被广泛使用的模型。因此,推荐Netty服务端采用NioServerSocketChannel作为Channel的类型,客户端采用NioSocketChannel。
b.channel(NioServerSocketChannel.class);
ChannelHandler:在Netty中可以通过ChannelPipeline去注册多个ChannelHandler,每个ChannelHandler各司其职,这样就可以实现最大化的代码复用。
b.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline()
.addLast("codec", new HttpServerCodec())
.addLast("compressor", new HttpContentCompressor())
.addLast("aggregator", new HttpObjectAggregator(65536))
.addLast("handler", new HttpServerHandler());
}
})
Channel初始化时都会绑定一个Pipeline,它主要用于服务编排。Pipeline管理了多个ChannelHandler。IO事件依次在ChannelHandler中传播,ChannelHandler负责业务逻辑处理。上述HTTP服务器示例中使用链式的方式加载了多个ChannelHandler,包含HTTP编解码处理器、HTTPContent压缩处理器、HTTP消息聚合处理器、自定义业务逻辑处理器。Channel参数:Netty提供了十分便捷的方法,用于设置Channel参数。关于Channel的参数数量非常多,如果每个参数都需要自己设置,那会非常繁琐。Netty提供了默认参数设置,实际场景下默认参数已经满足我们的需求,我们仅需要修改自己关系的参数即可。
b.option(ChannelOption.SO_KEEPALIVE, true);
ServerBootstrap设置Channel属性有option和childOption两个方法,option主要负责设置Boss线程组,而childOption对应的是Worker线程组。Netty的配置之后,bind方法会真正触发启动,sync方法则会阻塞,直至整个启动过程完成。
ChannelFuture f = b.bind().sync();
EventLoop这个概念其实并不是Netty独有的,它是一种事件等待和处理的程序模型,可以解决多线程资源消耗高的问题。
例如 Node.js就采用了EventLoop的运行机制,不仅占用资源低,而且能够支撑了大规模的流量访问。
在Netty中EventLoop是Netty Reactor线程模型的事件处理引擎。每个EventLoop线程都维护一个Selector选择器和任务队列taskQueue。它主要负责处理IO事件、普通任务和定时任务。
Netty中推荐使用NioEventLoop作为实现类,NioEventLoop最核心的run()方法源码如下:
protected void run() {
for (;;) {
try {
try {
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
case SelectStrategy.SELECT:
select(wakenUp.getAndSet(false)); // 轮询 IO 事件
if (wakenUp.get()) {
selector.wakeup();
}
default:
}
} catch (IOException e) {
rebuildSelector0();
handleLoopException(e);
continue;
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
try {
processSelectedKeys(); // 处理 IO 事件
} finally {
runAllTasks(); // 处理所有任务
}
} else {
final long ioStartTime = System.nanoTime();
try {
processSelectedKeys(); // 处理 IO 事件
} finally {
final long ioTime = System.nanoTime() - ioStartTime;
runAllTasks(ioTime * (100 - ioRatio) / ioRatio); // 处理完 IO 事件,再处理异步任务队列
}
}
} catch (Throwable t) {
handleLoopException(t);
}
try {
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
return;
}
}
} catch (Throwable t) {
handleLoopException(t);
}
}
}
NioEventLoop每次循环的处理流程都包含事件轮询select、事件处理processSelectedKeys、任务处理runAllTasks几个步骤,是典型的Reactor线程模型的运行机制。
而且Netty提供了一个参数ioRatio,可以调整IO事件处理和任务处理的时间比例。
NioEventLoop的事件处理机制采用的是无锁串行化的设计思路。
BossEventLoopGroup和WorkerEventLoopGroup包含一个或者多个NioEventLoop。BossEventLoopGroup负责监听客户端的Accept事件,当事件触发时,将事件注册至WorkerEventLoopGroup中的一个NioEventLoop上。每新建一个Channel, 只选择一个NioEventLoop与其绑定。所以说Channel生命周期的所有事件处理都是线程独立的,不同的NioEventLoop线程之间不会发生任何交集。NioEventLoop完成数据读取后,会调用绑定的ChannelPipeline进行事件传播,ChannelPipeline也是线程安全的,数据会被传递到ChannelPipeline的第一个ChannelHandler中。数据处理完成后,将加工完成的数据再传递给下一个ChannelHandler,整个过程是串行化执行,不会发生线程上下文切换的问题。NioEventLoop无锁串行化的设计不仅使系统吞吐量达到最大化,而且降低了用户开发业务逻辑的难度,不需要花太多精力关心线程安全问题。虽然单线程执行避免了线程切换,但是它的缺陷就是不能执行时间过长的IO操作,一旦某个IO事件发生阻塞,那么后续的所有IO事件都无法执行,甚至造成事件积压。在使用Netty进行程序开发时,要对ChannelHandler的实现逻辑有充分的风险意识。
NioEventLoop线程的可靠性至关重要,一旦NioEventLoop发生阻塞或者陷入空轮询,就会导致整个系统不可用。在 JDK中,Epoll的实现是存在漏洞的,即使Selector轮询的事件列表为空,NIO线程一样可以被唤醒,导致CPU100%占用。这就是臭名昭著的JDK epoll空轮询的Bug。
Netty采用了机制来检测线程是否可能陷入空轮询。在执行select()操作之前,记录当前时间。通过比较事件轮询的持续时间与预期的超时时间,Netty能够判断是否发生了空轮询。Netty引入了计数变量selectCnt,当selectCnt达到阈值时,会重建Selector对象。这种方法避免了JDK epoll的空轮询Bug。
NioEventLoop任务队列遵循FIFO规则,可以保证任务执行的公平性。NioEventLoop 处理的任务类型基本可以分为三类。
NioEventLoop的execute()方法向任务队列taskQueue中添加任务。例如Netty在写数据时会封装WriteAndFlushTask提交给taskQueue。taskQueue的实现类是多生产者单消费者队列MpscChunkedArrayQueue,在多线程并发添加任务时,可以保证线程安全。NioEventLoop的schedule()方法向定时任务队列scheduledTaskQueue添加一个定时任务,用于周期性执行该任务。例如,心跳消息发送等。定时任务队列 scheduledTaskQueue 采用优先队列PriorityQueue实现。tailTasks相比于普通任务队列优先级较低,在每次执行完taskQueue中任务后会去获取尾部队列中任务执行。尾部任务并不常用,主要用于做一些收尾工作,例如统计事件循环的执行时间、监控信息上报等。NioEventLoop处理任务的逻辑,源码实现如下:
protected boolean runAllTasks(long timeoutNanos) {
// 1. 合并定时任务到普通任务队列
fetchFromScheduledTaskQueue();
// 2. 从普通任务队列中取出任务
Runnable task = pollTask();
if (task == null) {
afterRunningAllTasks();
return false;
}
// 3. 计算任务处理的超时时间
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
// 4. 安全执行任务
safeExecute(task);
runTasks++;
// 5. 每执行 64 个任务检查一下是否超时
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
// 6. 收尾工作
afterRunningAllTasks();
this.lastExecutionTime = lastExecutionTime;
return true;
}
可以分为6个步骤:
fetchFromScheduledTaskQueue函数:将定时任务从scheduledTaskQueue中取出,聚合放入普通任务队列taskQueue中,只有定时任务的截止时间小于当前时间才可以被合并。taskQueue中取出任务。safeExecute函数:安全执行任务,实际直接调用Runnable的run()方法。Netty是一个高性能的网络通信框架,广泛应用于需要高并发和高吞吐量的场景。它适用于构建各种类型的网络服务,包括但不限于高性能的TCP服务器、实时的WebSocket应用、轻量级的UDP服务和高效的HTTP/HTTPS 服务。
Netty的异步非阻塞IO模型使其特别适合处理大量并发连接和高负载情况,广泛用于金融系统、在线游戏、实时聊天、流媒体传输、分布式系统和微服务架构等领域。凭借其灵活的架构和高效的性能,Netty能够满足对延迟敏感的应用需求,并且支持复杂的协议和自定义业务逻辑。
Netty依赖。
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.36.Final</version>
</dependency>
ServerBootstrap类来引导服务器端。配置主要包括设置主事件循环线程和工作事件循环线程的线程池,以及处理各种连接和IO事件的处理器。
/**
* netty 服务端测试
*/
public class MainTestServer {
public static void main(String[] args) {
// 启动器, 负责组装netty组件 启动服务器
new ServerBootstrap()
// BossEventLoop WorkEventLoop 每个 EventLoop 就是 一个选择器 + 一个线程
.group(new NioEventLoopGroup())
// 选择服务器 ServerSocketChannel 具体实现
.channel(NioServerSocketChannel.class)
// 决定了 workEventLoop 能做那些操作
.childHandler(
// 建立连接后会被调用; 作用: 初始化 + 添加其他的 handler
new ChannelInitializer<NioSocketChannel>() {
// 当客户端请求发过来时 才会调用
@Override
protected void initChannel(NioSocketChannel channel) throws Exception {
channel.pipeline().addLast(new StringDecoder());
// 自定义handler
channel.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("服务器端接收数据:" + msg);
}
});
}
})
// 绑定监听端口
.bind(8090);
}
}
Bootstrap类来引导客户端,配置包括事件循环线程池、处理器等。
/**
* netty 客户端测试
*/
public class MainTestClient {
public static void main(String[] args) throws InterruptedException {
new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
// 初始化 在与服务器建立链接的时候 调用
@Override
protected void initChannel(NioSocketChannel channel) throws Exception {
// 添加编码器 只有当向服务端发送请求数据时 才会执行
channel.pipeline().addLast(new StringEncoder());
}
})
.connect(new InetSocketAddress("127.0.0.1", 8090))
//阻塞方法,直到与服务器端连接建立
.sync()
.channel()
// 向服务器端发送数据
.writeAndFlush("hello word");
}
}
Netty依赖。
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.36.Final</version>
</dependency>
Netty服务器。在此类中,配置ServerBootstrap来设置服务器的基本属性,并绑定端口以开始监听请求。
public class NettyHttpServer {
private final int port;
public NettyHttpServer(int port) {
this.port = port;
}
public void start() throws Exception {
// Event loop groups for handling IO operations
final NioEventLoopGroup bossGroup = new NioEventLoopGroup();
final NioEventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new HttpServerCodec());
ch.pipeline().addLast(new HttpObjectAggregator(65536));
ch.pipeline().addLast(new HttpContentCompressor());
ch.pipeline().addLast(new HttpContentDecompressor());
ch.pipeline().addLast(new SimpleHttpHandler());
}
})
.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.SO_KEEPALIVE, true);
// Bind and start to accept incoming connections
ChannelFuture f = bootstrap.bind(port).sync();
f.channel().closeFuture().sync();
} finally {
// Shut down all event loops to terminate all threads
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
public static void main(String[] args) throws Exception {
new NettyHttpServer(8080).start();
}
}
SimpleHttpHandler处理 HTTP 请求和响应。这个处理器将负责处理客户端的请求并生成响应。
public class SimpleHttpHandler extends SimpleChannelInboundHandler<FullHttpRequest> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, FullHttpRequest req) throws Exception {
// Create a simple HTTP response
String content = "Hello, Netty!";
FullHttpResponse response = new DefaultFullHttpResponse(
HttpVersion.HTTP_1_1, HttpResponseStatus.OK,
Unpooled.copiedBuffer(content, CharsetUtil.UTF_8));
response.headers().set(HttpHeaders.Names.CONTENT_TYPE, "text/plain; charset=UTF-8");
response.headers().set(HttpHeaders.Names.CONTENT_LENGTH, response.content().readableBytes());
// Write the response and close the connection
ctx.writeAndFlush(response).addListener(ChannelFutureListener.CLOSE);
}
}
public static void main(String[] args) throws Exception {
new NettyHttpServer(8080).start();
}
http://localhost:8080来测试服务是否正常工作。如果一切正常,应该会看到 “Hello, Netty!” 的响应。
curl http://localhost:8080
TCP是面向连接的,面向流的,提供高可靠性服务。客户端和服务器端都要有成对的Socket,因此发送端为了将多个发给接收端的包,更有效的发给对方,使用了优化算法,将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。
这样做虽然提高了效率,但是接收端就难于分辨出完整的数据包了,由于TCP无消息保护边界,需要在接收端处理消息边界问题,也就是我们所说的粘包、拆包问题。
粘包就是多个数据包被合并成一个包进行发送。在接收端,数据包无法区分它们的边界,导致接收到的数据流是混合的。 拆包是一个数据包被拆分成多个包进行发送。在接收端,可能会将多个数据包的内容错误地合并为一个包。
对于粘包的情况,要对粘在一起的包进行拆包。对于拆包的情况,要对被拆开的包进行粘包,即将一个被拆开的完整应用包再组合成一个完整包。 比较通用的做法就是每次发送一个应用数据包前在前面加上四个字节的包长度值,指明这个应用包的真实长度。
在每个数据包的开头添加一个固定长度的字段,用于指明整个包的长度。这样,接收端可以根据这个长度信息正确地拆分和组装数据包,从而解决粘包和拆包问题。数据包格式:
| Length (4 bytes) | Data Body |
服务端代码
public class TcpServer {
public static void main(String[] args) {
try {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new java.net.InetSocketAddress(8080));
System.out.println("服务器启动,监听端口8080");
while (true) {
SocketChannel clientChannel = serverSocketChannel.accept();
System.out.println("客户端已连接");
// 使用线程处理客户端请求
new Thread(() -> handleClient(clientChannel)).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static void handleClient(SocketChannel channel) {
try {
while (true) {
byte[] data = receiveMessage(channel);
if (data == null) break; // 连接关闭
String message = new String(data);
System.out.println("收到消息: " + message);
// 回显消息给客户端
sendMessage(channel, data);
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static void sendMessage(SocketChannel channel, byte[] data) throws IOException {
ByteBuffer lengthBuffer = ByteBuffer.allocate(4);
lengthBuffer.putInt(data.length + 4); // 包含长度字段的总长度
lengthBuffer.flip();
ByteBuffer dataBuffer = ByteBuffer.wrap(data);
channel.write(lengthBuffer);
channel.write(dataBuffer);
}
private static byte[] receiveMessage(SocketChannel channel) throws IOException {
ByteBuffer lengthBuffer = ByteBuffer.allocate(4);
int bytesRead = channel.read(lengthBuffer);
if (bytesRead == -1) return null; // 读取结束
lengthBuffer.flip();
int length = lengthBuffer.getInt();
ByteBuffer dataBuffer = ByteBuffer.allocate(length - 4);
channel.read(dataBuffer);
dataBuffer.flip();
byte[] data = new byte[dataBuffer.remaining()];
dataBuffer.get(data);
return data;
}
}
客户端代码
public class TcpClient {
public static void main(String[] args) {
try {
SocketChannel socketChannel = SocketChannel.open(new java.net.InetSocketAddress("localhost", 8080));
System.out.println("连接到服务器");
// 发送消息到服务器
String message = "Hello, Server!";
sendMessage(socketChannel, message.getBytes());
// 接收服务器的响应
byte[] response = receiveMessage(socketChannel);
System.out.println("收到来自服务器的消息: " + new String(response));
socketChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void sendMessage(SocketChannel channel, byte[] data) throws IOException {
ByteBuffer lengthBuffer = ByteBuffer.allocate(4);
lengthBuffer.putInt(data.length + 4); // 包含长度字段的总长度
lengthBuffer.flip();
ByteBuffer dataBuffer = ByteBuffer.wrap(data);
channel.write(lengthBuffer);
channel.write(dataBuffer);
}
private static byte[] receiveMessage(SocketChannel channel) throws IOException {
ByteBuffer lengthBuffer = ByteBuffer.allocate(4);
channel.read(lengthBuffer);
lengthBuffer.flip();
int length = lengthBuffer.getInt();
ByteBuffer dataBuffer = ByteBuffer.allocate(length - 4);
channel.read(dataBuffer);
dataBuffer.flip();
byte[] data = new byte[dataBuffer.remaining()];
dataBuffer.get(data);
return data;
}
}
目前市面上已经有不少通用的协议,例如 HTTP、HTTPS、JSON-RPC、FTP、IMAP、Protobuf 等。通用协议兼容性好,易于维护,各种异构系统之间可以实现无缝对接。如果在满足业务场景以及性能需求的前提下,推荐采用通用协议的方案。相比通用协议,自定义协议主要有以下优点。
一个完备的网络协议需要具备的基本要素:
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
在Netty中,需要实现ByteToMessageDecoder和MessageToByteEncoder类来处理编解码操作。
ByteToMessageDecoder:将接收到的字节流解码为协议消息对象。MessageToByteEncoder:将协议消息对象编码为字节流发送出去。在Netty中自定义协议步骤:
public class MyProtocolConstants {
public static final int MAGIC_NUMBER = 0xABCD; // 魔数
public static final byte PROTOCOL_VERSION = 1; // 协议版本号
public static final byte SERIALIZATION_TYPE = 1; // 序列化算法
public static final byte MESSAGE_TYPE = 1; // 报文类型
public static final int HEADER_LENGTH = 13; // 消息头长度
}
public class MyProtocolMessage {
private final int magicNumber;
private final byte version;
private final byte serializationType;
private final byte messageType;
private final byte status;
private final byte[] reserved;
private final int dataLength;
private final byte[] data;
public MyProtocolMessage(int magicNumber, byte version, byte serializationType, byte messageType,
byte status, byte[] reserved, int dataLength, byte[] data) {
this.magicNumber = magicNumber;
this.version = version;
this.serializationType = serializationType;
this.messageType = messageType;
this.status = status;
this.reserved = reserved;
this.dataLength = dataLength;
this.data = data;
}
// Getter methods...
}
ByteToMessageDecoder。
public class MyProtocolDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if (in.readableBytes() < MyProtocolConstants.HEADER_LENGTH) {
return;
}
in.markReaderIndex();
int magicNumber = in.readInt();
byte version = in.readByte();
byte serializationType = in.readByte();
byte messageType = in.readByte();
byte status = in.readByte();
byte[] reserved = new byte[4];
in.readBytes(reserved);
int dataLength = in.readInt();
if (in.readableBytes() < dataLength) {
in.resetReaderIndex();
return;
}
byte[] data = new byte[dataLength];
in.readBytes(data);
MyProtocolMessage message = new MyProtocolMessage(magicNumber, version, serializationType, messageType,
status, reserved, dataLength, data);
out.add(message);
}
}
MessageToByteEncoder。
public class MyProtocolEncoder extends MessageToByteEncoder<MyProtocolMessage> {
@Override
protected void encode(ChannelHandlerContext ctx, MyProtocolMessage msg, ByteBuf out) throws Exception {
out.writeInt(msg.getMagicNumber());
out.writeByte(msg.getVersion());
out.writeByte(msg.getSerializationType());
out.writeByte(msg.getMessageType());
out.writeByte(msg.getStatus());
out.writeBytes(msg.getReserved());
out.writeInt(msg.getDataLength());
out.writeBytes(msg.getData());
}
}
SimpleChannelInboundHandler。
public class MyProtocolHandler extends SimpleChannelInboundHandler<MyProtocolMessage> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, MyProtocolMessage msg) throws Exception {
// 处理消息
System.out.println("Received message with magic number: " + msg.getMagicNumber());
// 进一步处理消息...
}
}
ChannelInitializer中配置自定义的编解码器。
public class MyChannelInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new MyProtocolDecoder());
pipeline.addLast(new MyProtocolEncoder());
pipeline.addLast(new MyProtocolHandler());
}
}
Netty服务器并绑定到指定端口。
public class MyNettyServer {
public static void main(String[] args) throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new MyChannelInitializer());
ChannelFuture f = b.bind(8080).sync();
f.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
PooledByteBufAllocator是Netty提供的内存池实现。它用于分配和管理ByteBuf对象,减少频繁的内存分配和释放操作,提高性能。
内存池将内存分为不同大小的块,每个大小对应一个内存池。内存池中的块被分为多个层级,包括Chunk、Page、Subpage。
Chunk是Netty向操作系统申请内存的单位,所有的内存分配操作也是基于Chunk完成的,Chunk可以理解为Page的集合,每个Chunk默认大小为16M。
Page是Chunk用于管理内存的单位,Netty中的Page的大小为8K,不要与Linux中的内存页Page混淆了。假如我们需要分配64K的内存,需要在Chunk中选取8个Page进行分配。
Subpage负责Page内的内存分配,假如我们分配的内存大小远小于Page,直接分配一个Page会造成严重的内存浪费,所以需要将Page划分为多个相同的子块进行分配,这里的子块就相当于Subpage。
按照Tiny和Small两种内存规格,SubPage的大小也会分为两种情况。在Tiny场景下,最小的划分单位为16B,按16B依次递增,16B、32B、48B …… 496B;在Small场景下,总共可以划分为512B、1024B、2048B、4096B四种情况。
Subpage没有固定的大小,需要根据用户分配的缓冲区大小决定,例如分配1K的内存时,Netty会把一个Page等分为8个1K的Subpage。
PoolArena是PooledByteBufAllocator内部用于实际管理内存块的组件。
PoolArena的数据结构包含两个PoolSubpage数组和六个PoolChunkList,两个PoolSubpage数组分别存放Tiny和Small类型的内存块,六个PoolChunkList 分别存储不同利用率的Chunk,构成一个双向循环链表。
其中PoolSubpage用于分配小于8K的内存,PoolChunkList用于分配大于8K的内存。
PoolSubpage也是按照Tiny和Small两种内存规格,设计了tinySubpagePools和smallSubpagePools两个数组,在Tiny场景下,内存单位最小为16B,按16B依次递增,共32种情况,Small场景下共分为512B、1024B、2048B、4096B四种情况,分别对应两个数组的长度大小,每种粒度的内存单位都由一个PoolSubpage进行管理。
假如我们分配20B大小的内存空间,也会向上取整找到32B的PoolSubpage节点进行分配。
PoolChunkList用于Chunk场景下的内存分配,PoolArena中初始化了六个PoolChunkList,分别为qInit、q000、q025、q050、q075、q100,它们分别代表不同的内存使用率。
qInit,内存使用率为0 ~ 25%的Chunk。q000,内存使用率为1 ~ 50%的Chunk。q025,内存使用率为25% ~ 75% 的Chunk。q050,内存使用率为50% ~ 100%的Chunk。q075,内存使用率为75% ~ 100%的Chunk。q100,内存使用率为100% 的Chunk。六种类型的PoolChunkList除了qInit,它们之间形成了双向链表。
qInit用于存储初始分配的PoolChunk,因为在第一次内存分配时,PoolChunkList中并没有可用的PoolChunk,所以需要新创建一个PoolChunk 并添加到qInit列表中。
qInit中的PoolChunk即使内存被完全释放也不会被回收,避免PoolChunk的重复初始化工作。
其余类型的PoolChunkList中的PoolChunk当内存被完全释放后,PoolChunk从链表中移除,对应分配的内存也会被回收。
在使用PoolChunkList分配内存时,也就是分配大于8K的内存,其链表的访问顺序是q050->q025->q000->qInit->q075,遍历检查PoolChunkList中是否有PoolChunk可以用于内存分配。
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
return;
}
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
boolean success = c.allocate(buf, reqCapacity, normCapacity);
assert success;
qInit.add(c);
}
这是一个折中的选择,在频繁分配内存的场景下,如果从q000开始,会有大部分的PoolChunk面临频繁的创建和销毁,造成内存分配的性能降低。
如果从q050开始,会使PoolChunk的使用率范围保持在中间水平,降低了PoolChunk被回收的概率,从而兼顾了性能。
PoolChunkList负责管理多个PoolChunk的生命周期,同一个PoolChunkList中存放内存使用率相近的PoolChunk,这些PoolChunk同样以双向链表的形式连接在一起。
因为PoolChunk经常要从PoolChunkList中删除,并且需要在不同的PoolChunkList中移动,所以双向链表是管理PoolChunk时间复杂度较低的数据结构。
每个PoolChunkList都有内存使用率的上下限,minUsage和maxUsage,当PoolChunk进行内存分配后,如果使用率超过maxUsage,那么PoolChunk会从当前PoolChunkList移除,并移动到下一个PoolChunkList。
同理,PoolChunk中的内存发生释放后,如果使用率小于minUsage,那么PoolChunk会从当前PoolChunkList移除,并移动到前一个PoolChunkList。
Netty内存的分配和回收都是基于PoolChunk完成的,PoolChunk是真正存储内存数据的地方,每个PoolChunk的默认大小为16M。
final class PoolChunk<T> implements PoolChunkMetric {
final PoolArena<T> arena;
final T memory; // 存储的数据
private final byte[] memoryMap; // 满二叉树中的节点是否被分配,数组大小为 4096
private final byte[] depthMap; // 满二叉树中的节点高度,数组大小为 4096
private final PoolSubpage<T>[] subpages; // PoolChunk 中管理的 2048 个 8K 内存块
private int freeBytes; // 剩余的内存大小
PoolChunkList<T> parent;
PoolChunk<T> prev;
PoolChunk<T> next;
// 省略其他代码
}
PoolChunk可以理解为Page的集合,Page只是一种抽象的概念,实际在Netty中Page所指的是PoolChunk所管理的子内存块,每个子内存块采用PoolSubpage表示。
Netty会使用伙伴算法将PoolChunk分配成2048个Page,最终形成一颗满二叉树,二叉树中所有子节点的内存都属于其父节点管理。
它的主要作用是管理内存池中的小内存块,在分配的内存大小小于一个8K时,会使用PoolSubpage进行管理。
final class PoolSubpage<T> implements PoolSubpageMetric {
final PoolChunk<T> chunk;
private final int memoryMapIdx; // 对应满二叉树节点的下标
private final int runOffset; // PoolSubpage 在 PoolChunk 中 memory 的偏移量
private final long[] bitmap; // 记录每个小内存块的状态
// 与 PoolArena 中 tinySubpagePools 或 smallSubpagePools 中元素连接成双向链表
PoolSubpage<T> prev;
PoolSubpage<T> next;
int elemSize; // 每个小内存块的大小
private int maxNumElems; // 最多可以存放多少小内存块:8K/elemSize
private int numAvail; // 可用于分配的内存块个数
// 省略其他代码
}
PoolSubpage通过管理小于PageSize的内存块来优化内存分配。它从PoolChunk中预留一块连续内存区域,并将其划分为多个小块。每个PoolSubpage内部维护一个空闲块链表。当需要分配内存时,PoolSubpage会检查其内存区域中的空闲块,并从中选择一个可用的块进行分配。
这样通过细化管理和复用小块内存,PoolSubpage能够高效地处理小块内存的分配请求,减少内存碎片化并提高性能。
PoolThreadCache是本地线程缓存,内存分配时,首先尝试从线程本地缓存PoolThreadCache中获取内存块,如果缓存中没有,才会从全局内存池中获取。
每个线程有自己的PoolThreadCache,可以快速分配和回收内存块,减少对全局内存池的争用。
PoolThreadCache缓存Tiny、Small、Normal三种类型的数据,而且根据堆内和堆外内存的类型进行了区分:
final class PoolThreadCache {
final PoolArena<byte[]> heapArena;
final PoolArena<ByteBuffer> directArena;
private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches;
private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches;
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
private final MemoryRegionCache<byte[]>[] normalHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
// 省略其他代码
}
PoolThreadCache中有一个重要的数据结构,MemoryRegionCache。MemoryRegionCache有三个重要的属性,分别为queue,sizeClass和size。
MemoryRegionCache实际就是一个队列,当内存释放时,将内存块加入队列当中,下次再分配同样规格的内存时,直接从队列中取出空闲的内存块。
PoolThreadCache将不同规格大小的内存都使用单独的MemoryRegionCache维护。
Netty的内存分配流程首先从PoolThreadCache中尝试分配内存。对于小于8K的内存请求,Netty首先检查本地线程缓存。
如果缓存中没有足够的内存块,则会向PoolArena请求。对于大于8K的内存请求,Netty直接向PoolArena请求内存,不经过本地线程缓存。PoolArena使用PoolChunk来管理较大的内存块,通过伙伴算法和二叉树结构进行内存分配。
对于小内存请求,PoolArena使用PoolSubpage来管理,按位图记录内存块的使用情况。释放的内存块会被缓存到PoolThreadCache中,定期进行整理,并在线程退出时释放。
具体来说:
Netty首先检查是否可以从 PoolThreadCache中获得所需的内存块。PoolThreadCache 是Netty为每个线程维护的缓存,它用于存储和管理小块内存。
这种缓存机制目的是提高内存分配的速度,减少线程间的竞争。PoolThreadCache 中有足够的空闲内存块,Netty将直接从缓存中分配内存。这种方式比从全局内存池中分配内存要快,因为它避免了对全局内存池的访问和管理开销。线程缓存的使用可以显著减少内存分配和释放的延迟。PoolArena:当线程缓存中的内存不足以满足请求时,Netty将向PoolArena请求内存。PoolArena 负责管理整个内存池中的内存块,它会根据内存块的大小选择适当的管理策略。PoolArena内存分配:PoolArena 处理内存分配时,会根据内存块的大小选择不同的管理策略。对于较小的内存块,PoolArena 使用 PoolSubpage 进行内存分配。PoolSubpage 使用位图来跟踪和管理内存块的使用状态,来减少内存碎片。
对于较大的内存块,PoolArena 使用 PoolChunk,PoolChunk通过伙伴算法或其他内存管理策略来处理大块内存。PoolChunk 负责分配较大的内存区域,能够应对不同的内存请求。PoolArena的PoolSubpage或PoolChunk中分配后,会被返回给应用程序使用。释放内存时,内存块将被归还到相应的内存管理区域。根据内存块的大小和当前的缓存状态,内存块可能会被归还到线程缓存中,或者直接归还到 PoolArena 中进行进一步管理。PoolThreadCache 中的内存块进行整理。这一过程可以减少内存碎片,提高内存使用效率。
当线程结束时,与该线程相关的线程缓存内存也会被释放和整理。零拷贝是计算机的一种技术,目的是减少数据在内存和存储设备之间的拷贝操作。这种技术优化了数据的传输过程,通过减少数据拷贝的次数来提高性能并降低资源消耗。
假设我们有一个大文件,需要将其内容发送到客户端。传统的文件传输流程如下:
在这个过程中,文件内容被拷贝了两次,这会消耗CPU和内存资源,特别是对于大文件和高频率传输的情况。
在零拷贝的优化下,减少了内存拷贝操作。以下是使用Netty的零拷贝进行文件传输的流程:
Netty使用DirectByteBuf创建直接内存缓冲区,该缓冲区不在Java堆内存中,而是在操作系统的内存中。允许Netty直接操作内核空间的缓冲区。FileRegion直接传输文件内容:Netty提供了FileRegion接口和DefaultFileRegion实现,可以直接将文件内容从磁盘传输到网络通道。
FileRegion可以通过FileChannel的transferTo方法实现数据的零拷贝传输,不需要将文件内容加载到内存中。数据从直接内存缓冲区通过网络传输到客户端,避免了额外的内存拷贝操作。
public class FileServerHandler extends SimpleChannelInboundHandler<String> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, String fileName) throws Exception {
// 打开文件
RandomAccessFile file = new RandomAccessFile(fileName, "r");
FileChannel fileChannel = file.getChannel();
// 创建 FileRegion,用于零拷贝文件传输
FileRegion fileRegion = new DefaultFileRegion(fileChannel, 0, fileChannel.size());
// 将文件内容写入到客户端
ctx.writeAndFlush(fileRegion).addListener(ChannelFutureListener.CLOSE);
}
}
Netty的零拷贝实现可以从两个方面来说:
Netty的零拷贝实现依赖于底层操作系统对零拷贝的支持。例如,在UNIX和Linux系统中,Netty使用sendfile()系统调用,将数据直接从内核缓冲区传输到套接字缓冲区,而不经过用户空间的拷贝。Netty可以减少内存拷贝,提升数据传输效率。FileRegion和DirectByteBuf等类使得数据可以高效地在网络通道和文件系统之间传输。Netty的零拷贝实现首先依赖于底层操作系统对零拷贝的支持。在UNIX和Linux系统中,这种支持主要体现在sendfile()方法的调用上。
当Netty调用sendfile()时,数据从文件系统的内核缓冲区直接被传输到网络接口的内核缓冲区。这个过程完全在内核空间完成,不涉及用户空间,从而减少了内存拷贝和 CPU 的使用。
Netty使用DirectByteBuf类来创建直接内存缓冲区。这些缓冲区分配在操作系统的直接内存中,而不是Java堆内存中。
数据在网络通道和直接内存缓冲区之间传输,避免了数据在堆内存和直接内存之间的拷贝。
ByteBuf buffer = Unpooled.directBuffer(1024); // 创建一个直接内存缓冲区
buffer.writeBytes(data); // 直接写入数据到内存
Netty 用高性能数据结构的主要目的是为了提高网络通信的效率和系统的整体性能。
所谓的高性能数据结构是指,那些在特定场景下优化了性能和效率的数据结构,通常能够提供更快的操作速度、更低的内存消耗或更高的并发处理能力。
| 数据结构 | 原因 | 好处 |
|---|---|---|
| FastThreadLocal | ThreadLocal 在高并发场景中性能较低且容易造成内存泄漏。 |
更快的访问速度,优化线程本地存储;避免内存泄漏,提供更安全的内存管理。 |
| HashedWheelTimer | 传统定时任务调度效率低,在高负载环境中成为性能瓶颈。 | 高效调度,时间轮算法优化任务组织;减少资源消耗,通过批量处理任务。 |
| MpscLinkedQueue | 传统队列实现性能瓶颈,需要无锁队列支持多个生产者。 | 提高并发性,支持多个线程同时添加任务;高效任务处理,减少锁竞争。 |
FastThreadLocal是Netty针对高并发场景优化的线程本地存储解决方案,通过减少内存占用、锁竞争和性能开销,提供了比ThreadLocal更高效的线程本地存储能力。
在Netty中,FastThreadLocal被广泛使用于处理网络事件和任务调度。主要包括:
EventLoop: Netty的EventLoop组件使用FastThreadLocal来存储和管理线程本地的数据,如Channel处理上下文、任务调度信息等。FastThreadLocal用于优化线程池中的线程本地存储,来提高任务处理的效率。FastThreadLocal对比ThreadLocal优势主要在快速的定位数据和更高的安全性。FastThreadLocal的设计是为了在高性能需求场景下提供优化的性能表现。
快速定位数据具体体现在,当调用ThreadLocal.set()添加Entry对象时,ThreadLocal是使用线性探测法解决Hash冲突的。
线性探测法是一种用于解决哈希表中冲突的开放地址法。它的基本思路是在哈希表中发生冲突时,线性地探测哈希表中的下一个位置来寻找空闲的存储位置。
当两个或更多的元素被哈希到相同的槽位时,会发生冲突。当发生冲突时,探测下一个位置。如果下一个位置也被占用,则继续探测下一个位置,直到找到一个空闲的位置。
为了便于理解,我们采用一组简单的数据模拟ThreadLocal.set()的过程是如何解决Hash冲突的。
threadLocalHashCode = 4,threadLocalHashCode & 15 = 4;此时数据应该放在数组下标为4的位置。下标4的位置正好没有数据,可以存放。threadLocalHashCode = 19,threadLocalHashCode & 15 = 4;但是下标4的位置已经有数据了,如果当前需要添加的Entry与下标4位置已存在的Entry两者的key相同,那么该位置Entry的value将被覆盖为新的值。我们假设key都是不相同的,所以此时需要向后移动一位,下标5的位置没有冲突,可以存放。threadLocalHashCode = 33,threadLocalHashCode & 15 = 3;下标3的位置已经有数据,向后移一位,下标4位置还是有数据,继续向后查找,发现下标6没有数据,可以存放。ThreadLocal.get()的过程也是类似的,也是根据threadLocalHashCode的值定位到数组下标,然后判断当前位置Entry对象与待查询Entry对象的key是否相同,如果不同,继续向下查找。
由此可见,ThreadLocal.set()/get()方法在数据密集时很容易出现Hash冲突,需要O(n)时间复杂度解决冲突问题,效率较低。
FastThreadLocal在定位数据的时候可以直接根据数组下标index获取,时间复杂度O(1)。
此外,FastThreadLocal相比ThreadLocal数据扩容更加简单高效,FastThreadLocal以index为基准向上取整到2的次幂作为扩容后容量,然后把原数据拷贝到新数组。而ThreadLocal由于采用的哈希表,所以在扩容后需要再做一轮rehash。
安全性体现在,ThreadLocal使用不当可能造成内存泄漏,只能等待线程销毁。在使用线程池的场景下,ThreadLocal只能通过主动检测的方式防止内存泄漏,从而造成了一定的开销。
然而FastThreadLocal不仅提供了remove()主动清除对象的方法,而且在线程池场景中Netty还封装了FastThreadLocalRunnable,FastThreadLocalRunnable最后会执行FastThreadLocal.removeAll()将Set集合中所有FastThreadLocal对象都清理掉。
FastThreadLocal使用示例:
public class FastThreadLocalExample {
private static final FastThreadLocal<String> threadLocal = new FastThreadLocal<String>() {
@Override
protected String initialValue() {
return "Initial Value";
}
};
public static void main(String[] args) {
// 创建并启动两个线程
FastThreadLocalThread thread1 = new FastThreadLocalThread(() -> {
String value = threadLocal.get();
System.out.println("Thread1 initial value: " + value);
threadLocal.set("Thread1 Value");
System.out.println("Thread1 new value: " + threadLocal.get());
});
FastThreadLocalThread thread2 = new FastThreadLocalThread(() -> {
String value = threadLocal.get();
System.out.println("Thread2 initial value: " + value);
threadLocal.set("Thread2 Value");
System.out.println("Thread2 new value: " + threadLocal.get());
});
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
为了实现高性能的定时任务调度,Netty引入了时间轮算法驱动定时任务的执行。它通过将定时任务分配到轮盘上的不同槽位来避免高频率的任务调度开销,这种设计主要用于处理大量的定时任务。
在Netty中,HashedWheelTimer主要用于处理任务的延迟执行,例如定时任务、超时处理等。
HashedWheelTimer是一种基于时间轮算法的定时任务调度器,主要用于高效地管理和执行大量定时任务。时间轮算法将时间分割成一个个固定大小的时间片,并将任务安排到相应的时间片上,从而优化了定时任务的管理。
时间轮可以理解为一种环形结构,像钟表一样被分为多个slot槽位。每个slot代表一个时间段,每个slot中可以存放多个任务,使用的是链表结构保存该时间段到期的所有任务。
时间轮通过一个时针随着时间一个个slot转动,并执行slot中的所有到期任务。
时间轮有点类似HashMap,如果多个任务如果对应同一个slot,处理冲突的方法采用的是拉链法。在任务数量比较多的场景下,适当增加时间轮的slot数量,可以减少时针转动时遍历的任务个数。
时间轮定时器最大的优势就是,任务的新增和取消都是O(1)时间复杂度,而且只需要一个线程就可以驱动时间轮进行工作。
时间轮是以时间作为刻度组成的一个环形队列,所以叫做时间轮。这个环形队列采用数组来实现HashedWheelBucket[],数组的每个元素称为槽,每个槽可以存放一个定时任务列表,叫HashedWheelBucket,它是一个双向链表,链表的每个节点表示一个定时任务项(HashedWheelTimeout),其中封装了真正的定时任务TimerTask。
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration,
TimeUnit unit,
int ticksPerWheel,
boolean leakDetection,
long maxPendingTimeouts) {
// 省略其他代码
wheel = createWheel(ticksPerWheel); // 创建时间轮的环形数组结构
mask = wheel.length - 1; // 用于快速取模的掩码
long duration = unit.toNanos(tickDuration); // 转换成纳秒处理
// 省略其他代码
workerThread = threadFactory.newThread(worker); // 创建工作线程
leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null; // 是否开启内存泄漏检测
this.maxPendingTimeouts = maxPendingTimeouts; // 最大允许等待任务数,HashedWheelTimer 中任务超出该阈值时会抛出异常
// 如果 HashedWheelTimer 的实例数超过 64,会打印错误日志
if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&
WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {
reportTooManyInstances();
}
}
HashedWheelTimer的核心组件:
HashedWheelTimeout,任务的封装类,包含任务的到期时间、需要经历的圈数remainingRounds等属性。HashedWheelBucket,相当于时间轮的每个slot,内部采用双向链表保存了当前需要执行的HashedWheelTimeout列表。Worker,HashedWheelTimer的核心工作引擎,负责处理定时任务。HashedWheelTimer的工作流程:
HashedWheelTimeout对象,并插入到对应的HashedWheelBucket中。
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
// 计算任务的到期时间
long deadline = System.nanoTime() + unit.toNanos(delay);
// 计算任务应插入的槽位
int tick = (int) ((deadline / tickDurationNanos) & mask);
// 创建 HashedWheelTimeout 对象
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline, tick);
// 将任务添加到相应的 HashedWheelBucket 中
wheel[tick].add(timeout);
return timeout;
}
HashedWheelTimer 使用 Worker 线程来周期性地推进时间轮。Worker线程每隔一个刻度时间推进时间轮一个槽位。每次推进时,它检查当前槽位中的所有任务。
对于到期的任务,Worker线程将其从槽位中移除并执行。任务执行后,HashedWheelTimeout 对象会被标记为已完成,执行相关的回调方法。
private final class Worker implements Runnable {
@Override
public void run() {
while (workerState == WORKER_STATE_STARTED) {
try {
Thread.sleep(tickDuration);
advanceClock(); // 推进时间轮
processTimeouts(); // 执行到期任务
} catch (InterruptedException e) {
// 处理异常
}
}
}
private void advanceClock() {
// 更新当前时间轮的槽位
}
private void processTimeouts() {
// 遍历当前槽位,执行到期任务
}
}
Timeout对象的cancel方法。取消任务会从槽位中移除相应的HashedWheelTimeout对象,确保它不会被执行。
public boolean cancel() {
boolean removed = bucket.remove(this); // 从槽位中移除
if (removed) {
// 执行取消回调等操作
}
return removed;
}
HashedWheelTimer时,stop方法会被调用。使用CAS操作将Worker线程的状态更新为SHUTDOWN,确保不会再有新的任务被添加。
中断Worker线程并等待其停止。处理线程中断异常,确保线程被完全停止。关闭内存泄漏检测器并减少实例计数,返回所有未处理的任务。public Set<Timeout> stop() {
// 如果当前线程是 workerThread,则抛出异常
if (Thread.currentThread() == workerThread) {
throw new IllegalStateException(
HashedWheelTimer.class.getSimpleName() +
".stop() cannot be called from " +
TimerTask.class.getSimpleName());
}
// 尝试通过 CAS 操作将工作线程的状态更新为 SHUTDOWN
if (!WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_STARTED, WORKER_STATE_SHUTDOWN)) {
if (WORKER_STATE_UPDATER.getAndSet(this, WORKER_STATE_SHUTDOWN) != WORKER_STATE_SHUTDOWN) {
INSTANCE_COUNTER.decrementAndGet();
if (leak != null) {
boolean closed = leak.close(this);
assert closed;
}
return Collections.emptySet();
}
}
try {
boolean interrupted = false;
// 中断 workerThread 并等待其停止
while (workerThread.isAlive()) {
workerThread.interrupt(); // 中断工作线程
try {
workerThread.join(100); // 等待工作线程停止
} catch (InterruptedException ignored) {
interrupted = true;
}
}
if (interrupted) {
Thread.currentThread().interrupt();
}
} finally {
INSTANCE_COUNTER.decrementAndGet(); // 减少实例计数
if (leak != null) {
boolean closed = leak.close(this);
assert closed;
}
}
return worker.unprocessedTimeouts(); // 返回未处理的任务
}
以下是HashedWheelTimer使用示例,展示了如何创建定时器、添加定时任务、执行任务以及停止定时器:
public class HashedWheelTimerExample {
public static void main(String[] args) {
// 创建 HashedWheelTimer 实例,刻度为1秒,时间轮槽的数量为512
HashedWheelTimer timer = new HashedWheelTimer(1, TimeUnit.SECONDS, 512);
// 定义一个定时任务
TimerTask task = new TimerTask() {
@Override
public void run(Timeout timeout) {
System.out.println("定时任务执行时间: " + System.currentTimeMillis());
}
};
// 添加定时任务到时间轮,设置任务延迟5秒执行
timer.newTimeout(task, 5, TimeUnit.SECONDS);
// 等待10秒,让定时任务有机会执行
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 停止时间轮定时器,并返回未处理的定时任务数量
Set<Timeout> unprocessedTimeouts = timer.stop();
System.out.println("未处理的定时任务数量: " + unprocessedTimeouts.size());
}
}
Mpsc的全称是Multi Producer Single Consumer,多生产者单消费者。Mpsc Queue可以保证多个生产者同时访问队列是线程安全的,而且同一时刻只允许一个消费者从队列中读取数据。
Netty Reactor线程中任务队列必须满足多个生产者可以同时提交任务,所以Mpsc Queue非常适合Netty Reactor线程模型。
在Netty中,EventLoopGroup负责管理和调度处理网络事件的线程。EventLoopGroup的实现使用了无锁队列来维护待处理的任务和事件。具体来说是SingleThreadEventLoop和NioEventLoop这两个类使用无锁队列来存储任务和事件。
这些队列是Mpsc类型的无锁队列,允许多个线程同时提交任务,而由单个事件循环线程处理这些任务。无锁队列的使用有效地提高了并发性能,减少了锁竞争的开销,使得事件处理更加高效。
在传统的锁机制下,当多个线程尝试同时访问共享数据结构时,会产生竞争,从而导致性能下降。使用无锁队列可以避免使用锁,减少线程间的竞争和上下文切换,提高并发性能。 它的核心在于利用原子操作来保证线程安全。原子操作是指在执行过程中不会被其他线程打断的操作,保证数据的一致性。 通常实现是使用链表结构,其中每个节点包含数据和指向下一个节点的引用。队列的头节点和尾节点通过原子操作来维护,插入和删除操作通过调整节点的链接来完成。
public class MpscQueue<E> {
private final Node<E> head;
private final AtomicReference<Node<E>> tail;
public MpscQueue() {
head = new Node<>(null);
tail = new AtomicReference<>(head);
}
public void offer(E item) {
Node<E> newTail = new Node<>(item);
Node<E> oldTail = tail.getAndSet(newTail);
oldTail.next = newTail;
}
public E poll() {
Node<E> headNode = head.next;
if (headNode == null) {
return null; // 队列为空
}
head.next = headNode.next;
return headNode.item;
}
private static class Node<E> {
private final E item;
private Node<E> next;
Node(E item) {
this.item = item;
}
}
}