访问量 次
访客数 人
在单机程序中,我们常用ReetrantLock、synchronized保证线程安全。类似这样:
public class MainTest {
private static final ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
lock.lock();
try {
System.out.println("hello world");
}finally {
lock.unlock();
}
}
}
但是,当项目采用分布式部署方式之后,再使用ReetrantLock、synchronized就不能保证数据的准确性,可能会出现严重bug。
举个例子,项目采用分布式部署方式之后,当很多个请求过来的时候,会先经过Nginx,然后Nginx再根据算法分发请求,到哪些服务器的程序上。
此时商品的库存为一件,有两个请求,到达不同服务器上的不同程序的相同代码,先后执行了查询SQL,查出来的数据是相同的,然后依次执行库存减一操作,此时库存会变成-1件,这就造成了超卖问题。
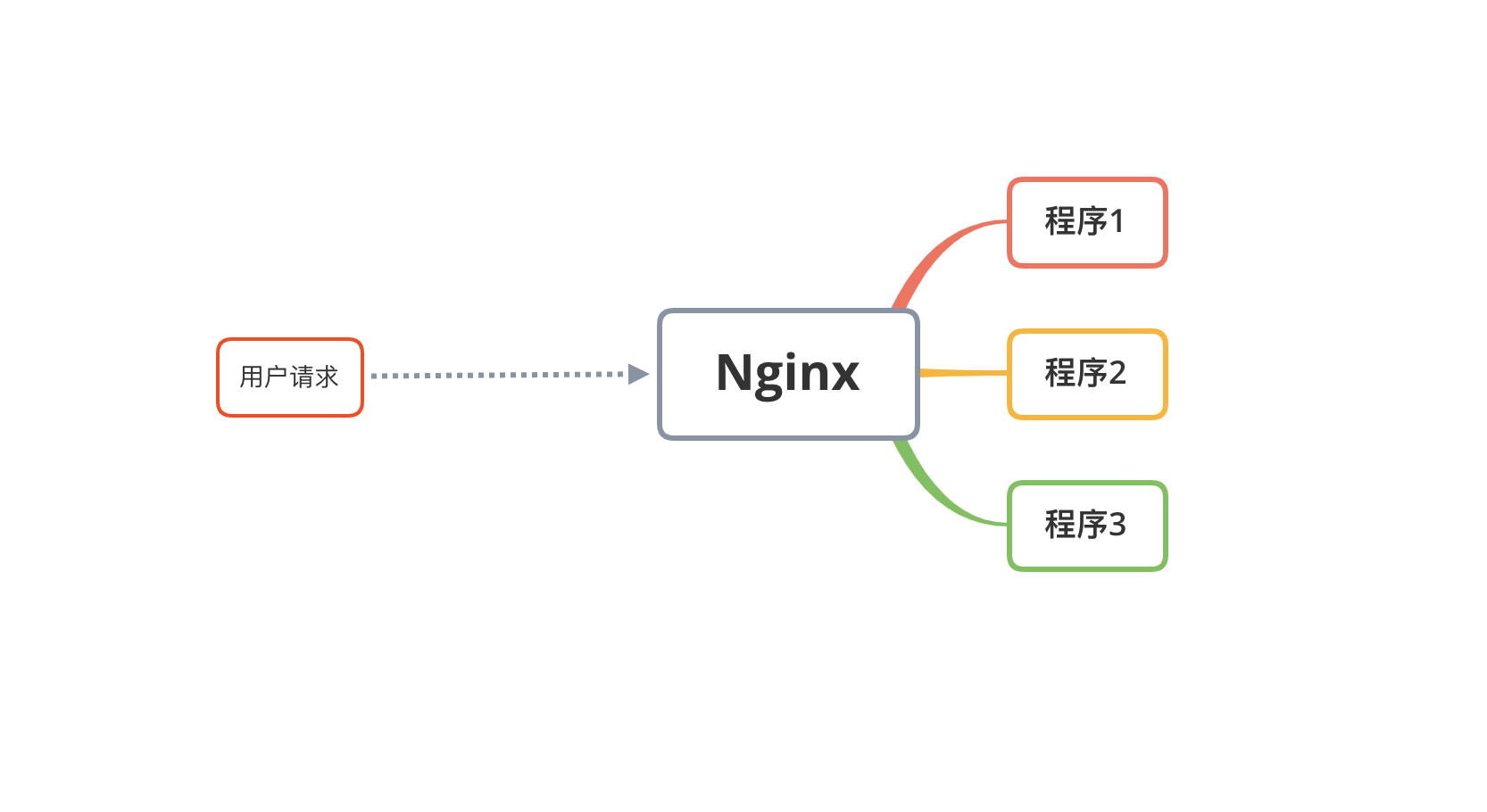
分布式锁就是用于解决在分布式系统中多节点对共享资源的访问冲突问题,确保同一时间只有一个节点可以访问或修改特定资源。 它管理数据一致性,防止多个节点同时修改相同数据,处理资源竞争,保障事务原子性,避免任务重复执行,同时协调和同步节点操作,减少死锁的可能性。
以下是常见的分布式锁:
| 实现方式 | 描述 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| 基于数据库的分布式锁 | 使用数据库表保存锁信息,插入记录表示锁定,删除记录表示释放 | 简单易用,快速实现 | 性能瓶颈,适用于负载不高的场景 | 小型应用、负载不高的系统 |
| 基于 Redis 的分布式锁 | 使用 Redis 的 SETNX 命令创建锁,设置过期时间 |
高性能,适合高并发场景,操作原子性 | 需要处理网络延迟和持久化问题,可能死锁 | 高并发应用,如限流、队列任务处理 |
| 基于 Zookeeper 的分布式锁 | 创建 Zookeeper 临时顺序节点,通过比较节点顺序实现锁 | 高可用,支持强一致性和协调 | 集群管理复杂,性能限制 | 配置管理、分布式协调,需要强一致性和可靠性场景 |
| 基于 Consul 的分布式锁 | 利用 Consul 的 KV 存储和租约机制实现锁 |
高可用,支持自动过期,适合服务发现和配置管理 | 需要额外的 Consul 集群,系统复杂度增加 | 服务发现、配置管理,需要高可用和自动过期机制 |
在实际开发中,基于Redis的分布式锁使用频率比较高。Redis的简单易用性和广泛支持使其成为分布式锁的首选。
创建一个专门的数据库表来存储锁信息。表通常包括锁的标识符,例如lock_key,和锁的持有状态,例如locked_by和locked_at。
节点在获取锁时,向数据库发送请求,比如插入记录或更新现有记录INSERT ... ON DUPLICATE KEY UPDATE或UPDATE ... WHERE。
插入成功表示锁已被获取,插入失败表示锁已经被其他节点持有。
当完成对共享资源的操作后,节点需要释放锁。通常通过删除记录或更新记录实现。在释放锁时,需要验证持有者信息是否匹配,以避免错误释放。 为了防止长时间占用锁,通常会设置锁的过期时间。例如,在表中记录锁的创建时间,并定期检查是否超时,如果超时则自动释放锁。
以下是使用Java和JDBC实现基于数据库的分布式锁的示例代码:
public class DatabaseDistributedLock {
private static final String DB_URL = "jdbc:mysql://localhost:3306/mydatabase";
private static final String USER = "root";
private static final String PASSWORD = "password";
public boolean acquireLock(String lockKey, String nodeId) {
try (Connection connection = DriverManager.getConnection(DB_URL, USER, PASSWORD)) {
String sql = "INSERT INTO distributed_locks (lock_key, locked_by, locked_at) " +
"VALUES (?, ?, NOW()) " +
"ON DUPLICATE KEY UPDATE locked_by = VALUES(locked_by), locked_at = VALUES(locked_at)";
try (PreparedStatement statement = connection.prepareStatement(sql)) {
statement.setString(1, lockKey);
statement.setString(2, nodeId);
int rowsAffected = statement.executeUpdate();
return rowsAffected > 0;
}
} catch (SQLException e) {
e.printStackTrace();
return false;
}
}
public boolean releaseLock(String lockKey, String nodeId) {
try (Connection connection = DriverManager.getConnection(DB_URL, USER, PASSWORD)) {
String sql = "DELETE FROM distributed_locks WHERE lock_key = ? AND locked_by = ?";
try (PreparedStatement statement = connection.prepareStatement(sql)) {
statement.setString(1, lockKey);
statement.setString(2, nodeId);
int rowsAffected = statement.executeUpdate();
return rowsAffected > 0;
}
} catch (SQLException e) {
e.printStackTrace();
return false;
}
}
}
它的优点是简单易用,可以利用现有的数据库系统,无需额外的中间件或工具。但是在高并发情况下,数据库锁操作可能成为性能瓶颈,影响数据库性能。 适用于负载较低的系统,数据库性能能够支持分布式锁的使用。在系统开发初期,利用数据库实现分布式锁可以快速搭建功能。
基于Redis的分布式锁,是利用Redis提供的原子操作和过期机制来管理分布式环境中的锁。
使用Redis的SETNX命令来设置锁。SETNX命令会尝试在 Redis中设置一个键值对,仅当该键不存在时才成功设置。成功设置的同时,锁被认为已经获取。
锁的键通常会设置一个值,例如节点ID,来标识持锁的节点。可以结合EX参数设置锁的过期时间,防止锁被长时间占用。
节点请求获取锁时,使用SET命令的NX选项和EX选项。
例如,SET lock_key node_id NX PX 30000将设置键lock_key的值为node_id,如果键不存在,并将键的过期时间设置为30000毫秒。
当释放锁时,节点会检查锁的持有者是否匹配,只有匹配的情况下才会删除锁。
例如,使用DEL命令删除锁键。在实际实现中,可能会结合Lua脚本来保证删除操作的原子性,防止其他节点同时删除锁。
使用Redis SETNX命令来设置锁,需要注意的是要对这个Key加一个过期时间,防止锁被长时间占用。
SETNX 是SET IF NOT EXISTS的简写.日常命令格式是SETNX key value,如果 key不存在,则SETNX成功返回1,如果这个key已经存在了,则返回0。
public class RedisDistributedLock {
@Autowired
private RedisTemplate redisTemplate;
// 保证value值唯一,这里是伪代码
final String value = "";
final String REDIS_LOCK = "redis_lock_demo";
public void context(){
try {
// 加锁
Boolean flag = redisTemplate.opsForValue().setIfAbsent(REDIS_LOCK,value);
// 设置过期时间,假设为10s
redisTemplate.expire(REDIS_LOCK,10, TimeUnit.SECONDS);
if (!flag) {
System.out.println("抢锁失败!");
}
String redisKey = redisTemplate.opsForvalue().get("redis_key");
int num0 = redisKey == null ? 0 : Integer.parseInt(redisKey);
if (num0 <= 0){
System.out.println("商品已售完!");
return;
}
// 卖出商品,存入Redis中
int num1 = num0 - 1;
redisTemplate.opsForvalue().set("redis_key",num1);
}finally {
redisTemplate.delete(REDIS_LOCK);
}
}
}
实际开发中经常使用Redisson来实现基于Redis的分布式锁。Redisson是一个Redis客户端库,提供了许多高级功能,包括分布式锁。
public class RedisDistributedLock {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private RedissonClient redisson;
final String REDIS_LOCK = "redis_lock_demo";
// 保证value值唯一,这里是伪代码
final String value = "";
public void context(){
RLock lock = redisson.getLock(REDIS_LOCK);
try {
lock.lock(REDIS_LOCK);
String redisKey = redisTemplate.opsForvalue().get("redis_key");
int num0 = redisKey == null ? 0 : Integer.parseInt(redisKey);
if (num0 <= 0){
System.out.println("商品已售完!");
return;
}
// 卖出商品,存入Redis中
int num1 = num0 - 1;
redisTemplate.opsForvalue().set("redis_key",num1);
}finally {
// 查询当前线程是否持有此锁
if (lock.isLocked() && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
如果你项目中引用了Redis,那么可以直接通过Redis的简单命令可以实现分布式锁,无需复杂的配置或额外中间件。而且Redis内存数据库,操作速度很快,适合高并发场景。
但Redis的网络延迟可能影响锁的获取和释放速度。
基于Zookeeper的分布式锁利用Zookeeper的节点和临时节点特性来管理分布式环境中的锁。Zookeeper是一个分布式协调服务,适用于高可靠性和高可用性的应用场景。
创建一个锁的根节点,例如/locks。在这个根节点下,Zookeeper的客户端会创建一个临时顺序节点来表示锁。每个临时节点有一个唯一的序号,如/locks/lock-00000001。
当节点请求获取锁时,它会在/locks下创建一个临时顺序节点。Zookeeper确保节点的顺序唯一,按照节点的序号排序。
节点会检查自己创建的临时节点是否是最小的序号节点。如果是,它就持有锁。如果不是,它会监听比自己序号小的节点的删除事件。 只有在比自己序号小的节点被删除后,才会再次检查自己是否成为最小的节点,进而获取锁。
释放锁时,节点会删除自己创建的临时节点。Zookeeper的临时节点在客户端断开连接时会自动删除,这样可以确保锁的释放。
实际项目中,推荐使用Curator来实现ZooKeeper分布式锁。
Curator是Netflix公司开源的一套ZooKeeperJava客户端框架,相比于ZooKeeper自带的客户端ZooKeeper来说,Curator的封装更加完善,各种API 都可以比较方便地使用。
public class CuratorDistributedLock {
private static final String LOCK_PATH = "/locks";
private CuratorFramework client;
private InterProcessMutex lock;
public CuratorDistributedLock(String zkConnectString) {
client = CuratorFrameworkFactory.builder()
.connectString(zkConnectString)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
lock = new InterProcessMutex(client, LOCK_PATH);
}
public boolean acquireLock() {
try {
lock.acquire();
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
public void releaseLock() {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Zookeeper提供了强一致性和高可用性,确保了锁的可靠性。利用顺序节点实现锁的公平性,保证了锁的获取顺序。
但Zookeeper的节点操作会有一定的性能开销,特别是在高并发情况下。
在实际开发中,通常情况下,基于Redis和ZooKeeper实现分布式锁,这两种使用频率是比较高的。用Redis实现分布式锁性能较高,ZooKeeper实现分布式锁可靠性更高。
如果对性能要求比较高的话,建议使用Redis实现分布式锁,优先选择Redisson提供的现成的分布式锁,而不是自己实现。
如果对可靠性要求比较高的话,建议使用ZooKeeper实现分布式锁,推荐基于Curator框架实现。不过,现在很多项目都不会用到ZooKeeper,如果单纯是因为分布式锁而引入ZooKeeper的话,那是不太可取的,不建议这样做,为了一个小小的功能增加了系统的复杂度。
Consul是一个服务发现和配置管理工具,它也提供了分布式锁的功能。基于Consul的分布式锁利用Consul的KV存储和锁机制来管理分布式环境中的锁。
使用Consul的KV存储来表示锁。通常,锁是通过在Consul中创建一个唯一的键来表示的。键的值可以是锁的持有者标识或其他相关信息。
锁的获取是通过原子操作来设置这个键值对。键值对的设置带有TTL,以防锁被持有者意外丢失或程序故障。
当节点请求获取锁时,它会尝试在Consul中设置一个键,设置操作只有在键不存在时才会成功,类似于Redis的SETNX操作。
锁的设置带有TTL,TTL到期后,Consul会自动删除这个键,这样可以防止锁被永久占用。
释放锁时,节点会删除它在Consul中设置的键。键的删除操作也是原子的,可以保证锁可以被正确释放。
public class ConsulDistributedLock {
private static final String LOCK_KEY = "lock_key";
private KeyValueClient kvClient;
public ConsulDistributedLock(String consulHost) {
Consul consul = Consul.builder().withUrl("http://" + consulHost).build();
kvClient = consul.keyValueClient();
}
public boolean acquireLock(String nodeId, long ttlSeconds) {
try {
String value = nodeId;
boolean success = kvClient.putValue(LOCK_KEY, value, ttlSeconds, TimeUnit.SECONDS);
return success;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
public void releaseLock() {
try {
kvClient.deleteValue(LOCK_KEY);
} catch (Exception e) {
e.printStackTrace();
}
}
}
在实际开发中,Consul被广泛用于服务发现、配置管理和服务治理等场景。它的健康检查、负载均衡和动态配置功能使其在现代分布式系统中非常有用。
虽然通过Consul的KV存储API实现分布式锁,API 简单易用。但是基于Consul的分布式锁,需要额外的Consul服务部署和管理。
如果单纯是因为分布式锁而引入Consul,那是不太可取的,不建议这样做。