访问量 次
访客数 人
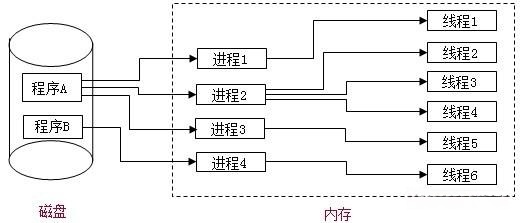
进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位。 一条线程指的是进程中的一个单一顺序的控制流,一个进程至少有一个线程,一个进程中可以并发多个线程,多个线程可共享数据,每条线程并行执行不同的任务。
Java程序是多线程程序,每启动一个Java程序,至少我们知道的都会包含一个主线程和一个垃圾回收线程。而且启动的时候,每条线程可以并行执行不同的任务。
| 单线程 | 多线程 | |
|---|---|---|
| 单CPU | 串行 | 并发 |
| 多CPU | 串行 | 并行 |
无论并行、并发,都可以有多个线程执行,如果是多个线程抢占一个CPU,交替执行,并且CPU通过时间片轮转等机制切换执行线程,这种情况下称为并发执行。 多个线程同时被多个CPU执行,并且各个线程之间不会互相抢占CPU资源,这种情况下称为并行执行。每个线程都在自己的CPU核心上独立执行,互不干扰。
对于单CPU的计算机来说,同一时间是只能干一件事儿的,如果是单线程就是串行,如果是多个线程就是并发。 而对于多CPU的计算机说,同一时间能干多个事,如果多个CPU同时执行多个线程就是并行,如果一个CPU同时执行多个线程就是并行。
并行与并发区别图解
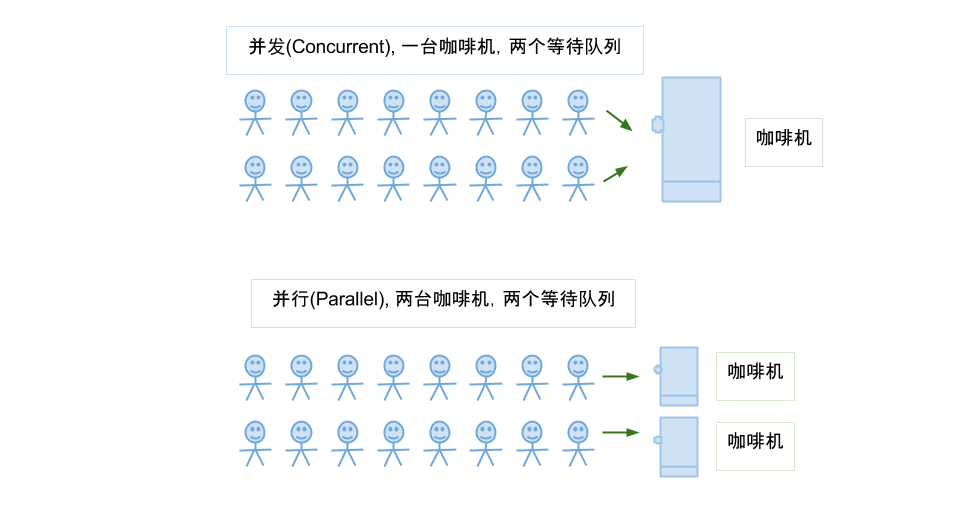
并发是两个队列交替使用一台咖啡机,并行是两个队列同时使用两台咖啡机; 如果串行,一个队列使用一台咖啡机,那么哪怕前面那个人便秘了去厕所呆半天,后面的人也只能死等着他回来才能去接咖啡,这种效率无疑是最低的。
synchronized或Lock接口可以实现多线程的同步,确保多个线程按照特定的顺序或条件执行。Future、CompletableFuture等方式实现。线程与同步异步关系:
| 单线程 | 多线程 | |
|---|---|---|
| 同步 | 只能同步执行,按照顺序执行任务 | 可以同步执行,多个线程按顺序执行任务 |
| 异步 | 不能直接异步执行,但可以通过事件循环或非阻塞IO模型实现类似异步效果 | 可以异步执行,通过多线程或者线程池来实现并行处理 |
守护线程是指为其他线程服务的线程。守护线程也称“服务线程”,在没有用户线程可服务时会自动离开。因为作用是服务其他线程,所以在程序中的优先级比较低。 在JVM中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。
举例,垃圾回收线程就是一个经典的守护线程,当我们的程序中不再有任何运行的线程,程序就不会再产生垃圾,垃圾回收器也就无事可做。 所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。 守护线程在程序中的操作演示:
public class MainTest {
public static void main(String[] args) {
int i = 0;
while (true) {
Thread daemon = new Thread(() -> {
System.out.println("启动线程--->" + Thread.currentThread().getName());
});
daemon.setDaemon(i==3);
daemon.start();
boolean isDaemon = daemon.isDaemon();
System.out.println("当前线程是否是守护线程:" + isDaemon);
if (isDaemon) {
break;
}
i++;
}
}
}
线程安全是指在多线程环境下,一个类、方法或代码块能够被多个线程安全地访问和修改,不会导致数据不一致性或产生不可预测的行为。线程安全通常通过同步机制实现,来确保多个线程不会同时访问或修改共享资源。
在多线程并发环境中,多个线程共同操作同一个数据,如果最终数据的值与预期不一致,就会出现线程不安全问题。 为了解决这个问题,Java中最常用的方法是加锁。当一个线程修改某个数据时,其他线程不能访问该数据,直到该线程操作结束并释放锁,其他线程才能继续操作该数据。
线程安全问题的根本原因:
public class Counter {
private int count = 0;
public void increment() {
count++; // 这个操作实际上分为三步:读取count值、增加1、写回count值
}
}
public class SharedData {
private boolean flag = false;
public void setFlag(boolean value) {
flag = value;
}
public boolean getFlag() {
return flag;
}
}
public class Example {
private int a = 0;
private boolean flag = false;
public void write() {
a = 1; // 1
flag = true; // 2
}
public void read() {
if (flag) { // 3
System.out.println(a); // 4
}
}
}
线程状态共包含6种,通过Thread.State枚举类表示的。6种状态又可以互相的转换,线程状态转换关系:
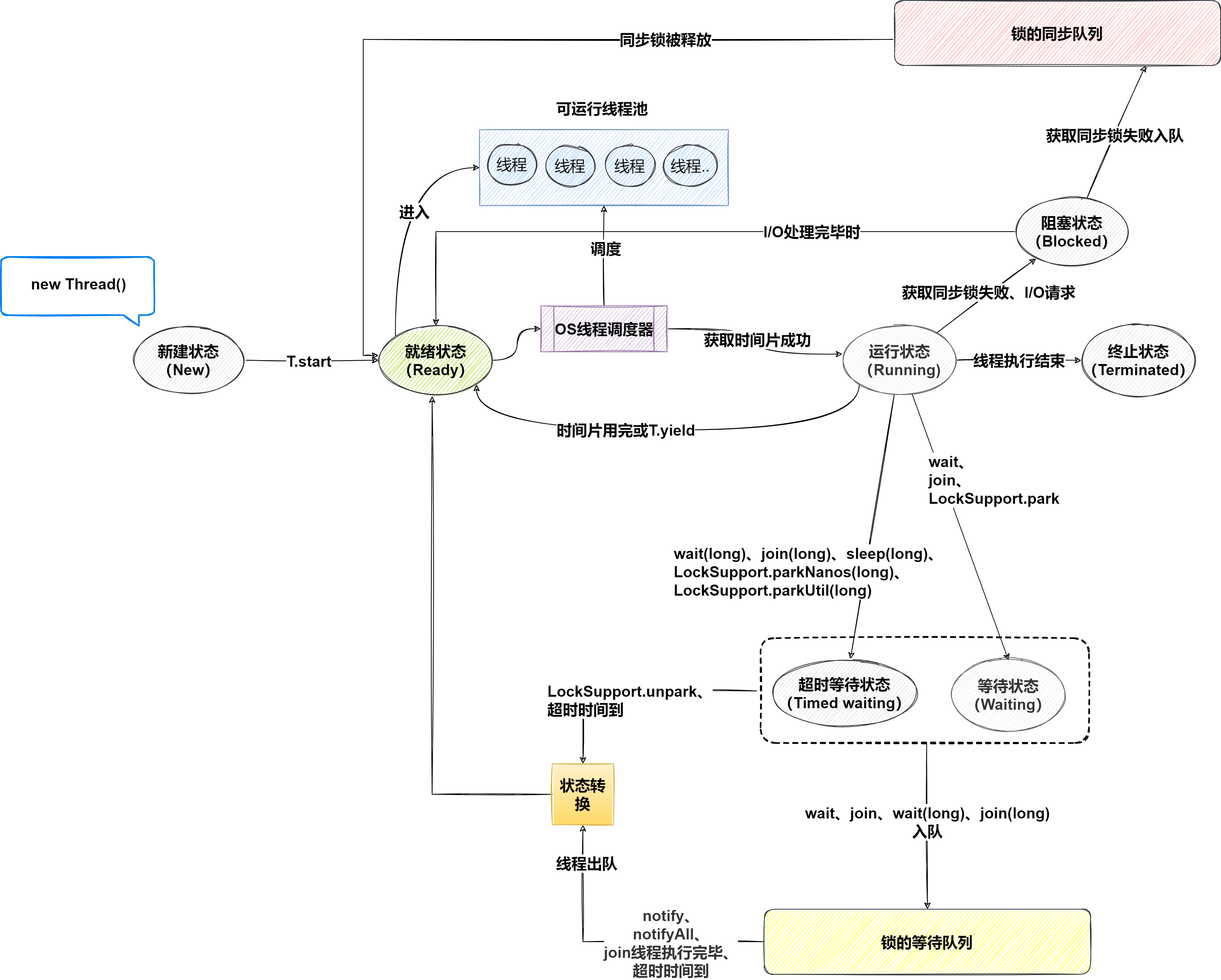
Thread t = new Thread(); 状态为NEW;调用线程对象的start()方法会使线程从NEW状态转变为RUNNABLE状态。Object.wait()、Thread.join()或LockSupport.park()方法时,它会进入WAITING状态,直到被其他线程显式唤醒。线程被唤醒后可以转变为RUNNABLE状态。sleep()、wait(timeout)、join(timeout)、LockSupport.parkNanos()或LockSupport.parkUntil()时,它会进入TIMED_WAITING状态,直到超时时间到达或被其他线程唤醒。
超时时间到达或被唤醒后可以转变为RUNNABLE状态。run()方法的执行或者因异常而终止时,会进入TERMINATED状态。一旦线程的run()方法执行完成或抛出未捕获的异常,线程将进入终止状态。阻塞和等待的区别在于,阻塞是被动的,它是在等待获取一个排它锁。而等待是主动的,通过调用Thread.sleep()和Object.wait()等方法进入等待。
start():启动一个新线程,调用线程的run()方法。
Thread t = new Thread(() -> {
System.out.println("Thread is running");
});
t.start();
run():运行线程中的代码。可以通过继承Thread类并重写run()方法,或通过实现Runnable接口并传递给Thread类的构造函数。
public class MyThread extends Thread {
public void run() {
System.out.println("Thread is running");
}
}
MyThread t = new MyThread();
t.start();
sleep(long millis):让当前线程休眠指定的毫秒数。
try {
Thread.sleep(1000); // 休眠1秒
} catch (InterruptedException e) {
e.printStackTrace();
}
join():当有新的线程加入时,主线程会进入等待状态,一直到调用join()方法的线程执行结束为止。join()方法的实现依赖于对象的wait()方法。
Thread t = new Thread(() -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
yield():用于让当前正在执行的线程暂时让出CPU的执行权,使其他线程有机会运行。它不会使线程进入阻塞或等待状态,只是让出当前的CPU时间片,让同等优先权的线程运行。
如果没有同等优先权的线程,那么yield()方法将不会起作用。
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(threadName + " is running, iteration: " + i);
// 暂时让出CPU执行权,给其他线程机会
Thread.yield();
}
System.out.println(threadName + " has finished execution.");
}
public static void main(String[] args) {
Thread thread1 = new Thread(new YieldExample("Thread 1"));
Thread thread2 = new Thread(new YieldExample("Thread 2"));
thread1.start();
thread2.start();
}
wait():使当前线程等待,直到另一个线程调用该对象的notify()或notifyAll()方法。wait()必须在同步synchronized块里使用。
synchronized (lock) {
lock.wait();
}
notify():唤醒一个正在等待该对象的wait()方法的线程。如果多个线程都在该对象的监视器上等待,则任意选择一个线程被唤醒。
notify()方法必须与wait()方法一起使用,否则会抛出IllegalMonitorStateException异常。notify()方法必须在同步代码块或同步方法中调用,因为它依赖于对象的监视器锁。
public synchronized void doWaitNotify() {
Thread waitingThread = new Thread(() -> {
try {
System.out.println("Thread is waiting...");
wait(); // 进入等待状态
System.out.println("Thread is notified and resumed.");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
waitingThread.start();
try {
Thread.sleep(1000); // 模拟一些操作延迟
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (this) {
System.out.println("Notifying waiting thread...");
notify(); // 唤醒等待的线程
}
}
需要注意区分wait方法与sleep方法,很多人分不清。sleep和wait方法异同点:
sleep()属于Thread类,wait()属于Object类;sleep()和wait()都会抛出InterruptedException异常,这个异常属于checkedException是不可避免;sleep()不会释放锁,会使线程堵塞,而调用wait()会释放锁,让线程进入等待状态,用 notify()、notifyall()可以唤醒,或者等待时间到了;这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。wait()必须在同步synchronized块里使用,sleep()可以在任意地方使用;其中"wait()必须在同步synchronized块里使用",不止wait方法,notify、notifyAll也和wait方法一样,必须在synchronized块里使用,为什么呢?
是为了避免丢失唤醒问题。假设没有synchronized修饰,使用了wait方法而没有设置等待时间,也没有调用唤醒方法或者唤醒方法调用的时机不对,这个线程将会永远的堵塞下去。
wait、notify、notifyAll方法调用的时候要释放锁,你都没给它加锁,他怎么释放锁。所以如果没在synchronized块中调用wait()、notify、notifyAll方法是肯定抛异常的。
在Java中创建一个线程,有且仅有一种方式,创建一个Thread类实例,并调用它的start方法。
最经典也是最常见的方式是通过继承Thread类,重写run()方法来创建线程。适用于需要直接控制线程生命周期的情况。
public class MainTest {
public static void main(String[] args) {
ThreadDemo thread1 = new ThreadDemo();
thread1.start();
}
}
class ThreadDemo extends Thread {
@Override
public void run() {
System.out.printf("通过继承Thread类的方式创建线程,线程 %s 启动",Thread.currentThread().getName());
}
}
实现Runnale接口,将它作为target参数传递给Thread类构造函数的方式创建线程。
public class MainTest {
public static void main(String[] args) {
new Thread(() -> {
System.out.printf("通过实现Runnable接口的方式,重写run方法创建线程;线程 %s 启动",Thread.currentThread().getName());
}).start();
}
}
Callable接口与Runnable类似,但它可以返回结果,并且可以抛出异常,需要配合Future接口使用。通过实现Callable接口,来创建一个带有返回值的线程。
在Callable执行完之前的这段时间,主线程可以先去做一些其他的事情,事情都做完之后,再获取Callable的返回结果。可以通过isDone()来判断子线程是否执行完。
public class MainTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> futureTask = new FutureTask<>(() -> {
System.out.printf("通过实现Callable接口的方式,重写call方法创建线程;线程 %s 启动", Thread.currentThread().getName());
System.out.println();
Thread.sleep(10000);
return "我是call方法返回值";
});
new Thread(futureTask).start();
System.out.println("主线程工作中 ...");
String callRet = null;
while (callRet == null){
if(futureTask.isDone()){
callRet = futureTask.get();
}
System.out.println("主线程继续工作 ...");
}
System.out.println("获取call方法返回值:"+ callRet);
}
}
在实际开发中,通常使用异步编程工具,如CompletableFuture。
CompletableFuture是JDK8的新特性。CompletableFuture实现了CompletionStage接口和Future接口,前者是对后者的一个扩展,增加了异步会点、流式处理、多个Future组合处理的能力,使Java在处理多任务的协同工作时更加顺畅便利。
public class CompletableFutureRunAsyncExample {
public static void main(String[] args) {
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
// 异步执行的任务,没有返回值
System.out.println("Running asynchronously");
});
future.thenRun(() -> {
System.out.println("After running asynchronously");
});
future.join(); // 等待任务完成
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello")
.thenApply(result -> result + " CompletableFuture!");
}
}
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务。如果线程数量超过了最大数量超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。 线程池是一种用于管理和复用线程的机制,可以有效地提高应用程序的性能和资源利用率。它的主要特点为:线程复用,提高响应速度,管理线程。
在Java中,使用java.util.concurrent包中的Executor来创建和管理线程池。几种常见的线程池创建方式:
Executors.newSingleThreadExecutor():创建只有一个线程的线程池。Executors.newFixedThreadPool(int):创建固定线程的线程池。Executors.newCachedThreadPool():创建一个可缓存的线程池,线程数量随着处理业务数量变化。这三种常用创建线程池的方式,底层代码都是用ThreadPoolExecutor创建的。
使用Executors.newSingleThreadExecutor()创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。
newSingleThreadExecutor将corePoolSize和maximumPoolSize都设置为1,它使用的LinkedBlockingQueue。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public class MainTest {
public static void main(String[] args) {
ExecutorService executor1 = null;
try {
executor1 = Executors.newSingleThreadExecutor();
for (int i = 1; i <= 10; i++) {
executor1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
}
} finally {
executor1.shutdown();
}
}
}
使用Executors.newFixedThreadPool(int)创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newFixedThreadPool创建的线程池corePoolSize和maximumPoolSize值是相等的,它使用的LinkedBlockingQueue。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public class MainTest {
public static void main(String[] args) {
ExecutorService executor1 = null;
try {
executor1 = Executors.newFixedThreadPool(10);
for (int i = 1; i <= 10; i++) {
executor1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
}
} finally {
executor1.shutdown();
}
}
}
使用Executors.newCachedThreadPool()创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收则新建线程。
newCachedThreadPool将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,使用的 SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public class MainTest {
public static void main(String[] args) {
ExecutorService executor1 = null;
try {
executor1 = Executors.newCachedThreadPool();
for (int i = 1; i <= 10; i++) {
executor1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
}
} finally {
executor1.shutdown();
}
}
}
在实际开发中用哪个线程池?上面的三种一个都不用,我们生产上只能使用自定义的。Executors类中已经给你提供了,为什么不用?
摘自《阿里巴巴开发手册》 【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。 说明:线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。 如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors返回的线程池对象的弊端如下: 1)FixedThreadPool和SingleThreadPool: 允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。 2)CachedThreadPool: 允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
自定义线程池代码演示:
public class MainTest {
public static void main(String[] args) {
ExecutorService executor1 = null;
try {
executor1 = new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 1; i <= 20; i++) {
executor1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
}
} finally {
executor1.shutdown();
}
}
}
SpringBoot异步配置,自定义线程池代码演示:
@EnableAsync
@Configuration
public class AsyncConfig {
/**
* 线程空闲存活的时间 单位: TimeUnit.SECONDS
*/
public static final int KEEP_ALIVE_TIME = 60 * 60;
/**
* CPU 核心数量
*/
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
/**
* 核心线程数量
*/
public static final int CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 4));
/**
* 线程池最大容纳线程数量
* IO密集型:即存在大量堵塞; 公式: CPU核心数量 / 1- 阻塞系数 (阻塞系统在 0.8~0.9 之间)
* CPU密集型: 需要大量运算,没有堵塞或很少有; 公式:CPU核心数量 + 1
*/
public static final int IO_MAXIMUM_POOL_SIZE = (int) (CPU_COUNT / (1 - 0.9));
public static final int CPU_MAXIMUM_POOL_SIZE = CPU_COUNT + 2;
/**
* 执行写入请求时的线程池
*
* @return 线程池
*/
@Bean(name = "iSaveTaskThreadPool")
public Executor iSaveTaskThreadPool() {
return getThreadPoolTaskExecutor("iSaveTaskThreadPool-",IO_MAXIMUM_POOL_SIZE,100000,new ThreadPoolExecutor.CallerRunsPolicy());
}
/**
* 执行读请求时的线程池
*
* @return 线程池
*/
@Bean(name = "iQueryThreadPool")
public Executor iQueryThreadPool() {
return getThreadPoolTaskExecutor("iQueryThreadPool-",CPU_MAXIMUM_POOL_SIZE,10000,new ThreadPoolExecutor.CallerRunsPolicy());
}
/**
* 创建一个线程池对象
* @param threadNamePrefix 线程名称
* @param queueCapacity 堵塞队列长度
* @param refusePolicy 拒绝策略
*/
private ThreadPoolTaskExecutor getThreadPoolTaskExecutor(String threadNamePrefix,int maxPoolSize,int queueCapacity,ThreadPoolExecutor.CallerRunsPolicy refusePolicy) {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(CORE_POOL_SIZE);
taskExecutor.setMaxPoolSize(maxPoolSize);
taskExecutor.setKeepAliveSeconds(KEEP_ALIVE_TIME);
taskExecutor.setThreadNamePrefix(threadNamePrefix);
// 拒绝策略; 既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量
taskExecutor.setRejectedExecutionHandler(refusePolicy);
// 阻塞队列 长度
taskExecutor.setQueueCapacity(queueCapacity);
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
taskExecutor.initialize();
return taskExecutor;
}
}
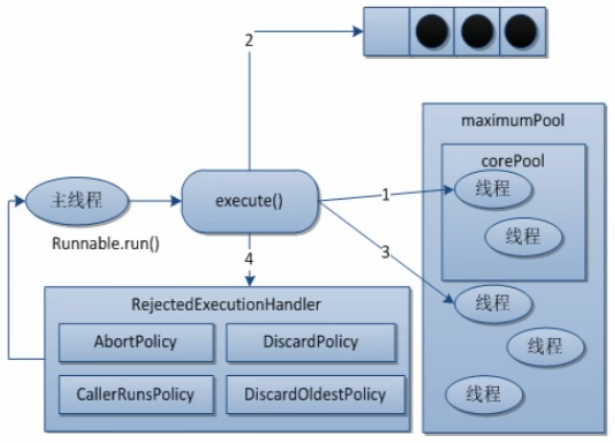
在创建了线程池后,等待提交过来的任务请求,当调用execute方法添加一个请求任务时,线程池会做如下判断:
corePoolSize,那么马上创建线程运行该任务。corePoolSize,那么该任务会被放入任务队列。maximumPoolSize,那么要创建非核心线程立刻运行这个任务扩容。maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。corePoolSize,那么这个线程就被停掉,所以线程池的所有任务完成后它最终会收缩到corePoolSize的大小。阻塞队列,顾名思义,首先它是一个队列,一个阻塞队列在数据结构中所起的作用:
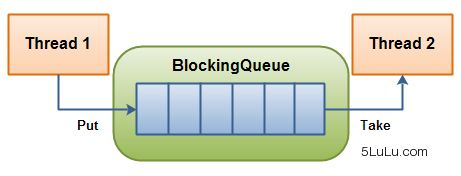
在多线程编程中,阻塞队列扮演着重要角色,特别适用于生产者-消费者模式,确保线程之间的同步和有序执行。阻塞队列的本质是一种数据结构,用于存储待执行的任务。 当任务提交给线程池时,如果核心线程已满或任务队列达到容量上限,新任务将被放入阻塞队列中,等待执行条件的满足。
阻塞在多线程领域指的是线程因某些条件而暂停执行,一旦条件满足,线程会被自动唤醒继续执行。这种机制保证了线程池的任务按照预期顺序执行,有效地管理并发任务的执行流程。
在Java中,常见的线程池阻塞队列包括:
ArrayBlockingQueue: 由数组结构组成的有界阻塞队列。它按照 FIFO(先进先出)的顺序对元素进行排序。LinkedBlockingQueue: 由链表结构组成的有界(默认大小为 Integer.MAX_VALUE,大约21亿)阻塞队列。同样按照 FIFO 的顺序对元素进行排序。PriorityBlockingQueue: 支持优先级排序的无界阻塞队列。元素按照它们的优先级顺序被处理,具有最高优先级的元素总是被队列中的下一个要处理的元素。DelayQueue: 使用优先级队列实现的延迟无界阻塞队列。队列中的元素只有在其指定的延迟时间到达时才能被取出。SynchronousQueue: 不存储元素的阻塞队列,每个插入操作必须等待一个对应的移除操作。用于直接传递任务的场景。LinkedTransferQueue: 由链表结构组成的无界阻塞队列,支持生产者-消费者的传输机制。与其他队列不同,它支持优先级传输。LinkedBlockingDeque: 由链表结构组成的双向阻塞队列。它支持在队列的两端进行插入和移除操作,是一种双端队列。当你自定义线程池时,选择合适的阻塞队列是非常重要的。阻塞队列就像一个存放任务的“箱子”,线程池中的任务先放到这里,然后线程池的线程再从这里取出来执行。
如果你的系统可能会有很多任务一起提交,可以考虑用能存很多任务的队列,比如LinkedBlockingQueue。这样即使任务多了,也不会丢失。
如果你的任务有优先级,比如有些任务比其他的更重要,那就选PriorityBlockingQueue。它会按照任务的优先级来决定哪个任务先执行。
如果应用程序需要限制内存使用,并希望在达到容量限制时阻塞新任务提交,可以选择ArrayBlockingQueue。
在Java中,线程池的创建和管理通过java.util.concurrent.ThreadPoolExecutor类完成。理解这个类构造函数的参数可以帮助我们更好地配置和优化线程池的运行效果。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// ...
}
corePoolSize: 核心线程数。当提交一个新任务时,如果当前运行的线程少于corePoolSize,则即使有空闲的工作线程,也会创建一个新线程来执行任务。
核心线程在ThreadPoolExecutor的生命周期内始终存活,除非设置了allowCoreThreadTimeOut。maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1。当任务队列满时,如果当前运行的线程数少于maximumPoolSize,则会创建新的线程来执行任务。threadFactory:线程工厂,一般用默认的即可。用于创建新线程,通常用来给线程设置名称、设置为守护线程等。workQueue:任务队列,用于保存等待执行任务的队列。随着业务量的增多,线程开始慢慢处理不过来,这时候需要放到任务队列中去等待线程处理。rejectedExecutionHandler:拒绝策略。如果业务越来越多,线程池首先会扩容,扩容后发现还是处理不过来,任务队列已经满了,处理被拒绝任务的策略。
AbortPolicy: 默认拒绝策略;直接抛出java.util.concurrent.RejectedExecutionException异常,阻止系统的正常运行;CallerRunsPolicy:调用这运行,一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量;DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入到队列中;DiscardPolicy:直接丢弃任务,不给予任何处理也不会抛出异常;如果允许任务丢失,这是一种最好的解决方案;keepAliveTime:多余的空闲线程的存活时间。如果线程池扩容后,能处理过来,而且数据量并没有那么大,用最初的线程数量就能处理过来,剩下的线程被叫做空闲线程。
keepAliveTime指的是当线程数超过corePoolSize时,多余的空闲线程在等待新任务到来之前可以存活的最长时间。如果设置为0,则超出核心线程数的空闲线程会立即终止。unit:keepAliveTime参数的时间单位,可以是TimeUnit.SECONDS、TimeUnit.MILLISECONDS等。合理配置线程池参数,可以分为以下两种情况:
参考公式:(CPU核数+1)CPU核数/ (1-阻塞系数) 阻塞系数在0.8~0.9之间public class MainTest {
public static void main(String[] args) {
ExecutorService executor1 = null;
try {
// 获取CPU核心数
int coreNum = Runtime.getRuntime().availableProcessors();
/*
* 1. IO密集型: CPU核数/ (1-阻塞系数) 阻塞系数在0.8~0.9之间
* 2. CPU密集型: CPU核数+1
*/
// int maximumPoolSize = coreNum + 1;
int maximumPoolSize = (int) (coreNum / (1 - 0.9));
System.out.println("当前线程池最大允许存放:" + maximumPoolSize + "个线程");
executor1 = new ThreadPoolExecutor(
2,
maximumPoolSize,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 1; i <= 20; i++) {
executor1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
}
} finally {
executor1.shutdown();
}
}
}
在Java中根据锁的特性来划分可以分为很多,锁的主要作用是确保多线程环境下的数据安全,从而保证程序的正确执行。
在Java中具体"锁"的实现,通常可以归纳为三种,使用synchronized关键字、调用juc.locks包下相关接口、使用CAS思想。
| 锁的类型与概念 | 描述 |
|---|---|
| 公平锁 | 线程按照请求的顺序获取锁。 |
| 非公平锁 | 线程获取锁的顺序不受控制,有可能插队。 |
| 可重入锁 | 允许同一个线程多次获取同一把锁,避免死锁。 |
| 不可重入锁 | 不允许同一个线程多次获取同一把锁。 |
| 共享锁 | 多个线程可以同时获取同一把锁。 |
| 独占锁 | 同一时间只允许一个线程获取该锁。 |
| 悲观锁 | 假设会有并发冲突,每次操作时都加锁。 |
| 乐观锁 | 假设不会有并发冲突,操作时不加锁,提交时检查是否冲突。 |
| 偏向锁 | 当只有一个线程访问同步块时,为该线程加锁,减少获取锁的操作成本。 |
| 轻量级锁 | 针对竞争不激烈的情况下进行优化,通过CAS操作来避免互斥。 |
| 重量级锁 | 竞争激烈时,锁的持有和释放会导致线程阻塞和唤醒。 |
| 可中断锁 | 允许在等待锁的过程中可以响应中断信号。 |
| 互斥锁 | 控制对共享资源的访问,同一时间只有一个线程可以获取锁。 |
| 死锁 | 几个线程因互相持有对方所需的资源而无法继续执行的状态。 |
根据线程获取锁的顺序来划分可分为公平锁和非公平锁。
ReentrantLock fairLock = new ReentrantLock(true); // true 表示使用公平锁
ReentrantLock nonfairLock = new ReentrantLock(false); // false 表示使用非公平锁(默认)
通常情况下,如果不特别需要公平性,非公平锁能够提供更高的性能。但是在某些需要严格控制线程执行顺序的场景下,公平锁可能更为适合。
在Java中公平锁和非公平锁的实现为ReentrantLock、synchronized。
其中synchronized是非公平锁,ReentrantLock默认是非公平锁,但是可以指定ReentrantLock的构造函数创建公平锁。
/**
* Creates an instance of {@code ReentrantLock}.
* This is equivalent to using {@code ReentrantLock(false)}.
*/
public ReentrantLock() {
sync = new NonfairSync();
}
/**
* Creates an instance of {@code ReentrantLock} with the
* given fairness policy.
*
* @param fair {@code true} if this lock should use a fair ordering policy
*/
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
根据一个线程是否可以多次获得同一把锁来划分,可分为可重入锁和不可重入锁。
举个例子,当你进入你家时门外会有锁,进入房间后厨房卫生间都可以随便进出,这个叫可重入锁。当你进入房间时,发现厨房、卫生间都上锁而且你拿不到钥匙,这个叫不可重入锁。
在Java中ReentrantLock和synchronized都是可重入锁。
public class ReentrantExample {
public synchronized void outerMethod() {
System.out.println("Outer method");
innerMethod();
}
public synchronized void innerMethod() {
System.out.println("Inner method");
}
public static void main(String[] args) {
ReentrantExample example = new ReentrantExample();
example.outerMethod();
}
}
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void outerMethod() {
lock.lock();
try {
System.out.println("Outer method");
innerMethod();
} finally {
lock.unlock();
}
}
public void innerMethod() {
lock.lock();
try {
System.out.println("Inner method");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ReentrantLockExample example = new ReentrantLockExample();
example.outerMethod();
}
}
根据锁的访问权限可划分为共享锁和独占锁。
在Java中,对于ReentrantLock和synchronized都是独占锁。对于ReentrantReadWriteLock其读锁是共享锁而写锁是独占锁,读锁的共享可保证并发读是非常高效的。
public class SharedLockExample {
private final ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.ReadLock readLock = rwLock.readLock();
private final ReentrantReadWriteLock.WriteLock writeLock = rwLock.writeLock();
public void readMethod() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + " acquired the read lock");
// Read-only critical section
} finally {
readLock.unlock();
System.out.println(Thread.currentThread().getName() + " released the read lock");
}
}
public void writeMethod() {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + " acquired the write lock");
// Write critical section
} finally {
writeLock.unlock();
System.out.println(Thread.currentThread().getName() + " released the write lock");
}
}
public static void main(String[] args) {
SharedLockExample example = new SharedLockExample();
Runnable readTask = () -> {
for (int i = 0; i < 3; i++) {
example.readMethod();
}
};
Runnable writeTask = () -> {
for (int i = 0; i < 3; i++) {
example.writeMethod();
}
};
Thread t1 = new Thread(readTask);
Thread t2 = new Thread(readTask);
Thread t3 = new Thread(writeTask);
t1.start();
t2.start();
t3.start();
}
}
根据对数据并发访问来划分,可分为悲观锁和乐观锁。乐观锁与悲观锁是一种广义上的概念,可以理解为一种标准类似于Java中的接口。
在Java中悲观锁的实现有,synchronized、Lock实现类,乐观锁的实现有CAS。
public class SynchronizedExample {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
public static void main(String[] args) {
SynchronizedExample example = new SynchronizedExample();
example.increment();
System.out.println("Count: " + example.getCount());
}
}
public class CASExample {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
while (true) {
int existingValue = count.get();
int newValue = existingValue + 1;
if (count.compareAndSet(existingValue, newValue)) {
break;
}
}
}
public int getCount() {
return count.get();
}
public static void main(String[] args) {
CASExample example = new CASExample();
example.increment();
System.out.println("Count: " + example.getCount());
}
}
自旋锁是一种特殊的锁,它不会让线程立即阻塞。 当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态,直到获取到某个锁超过一定的自旋次数后才会阻塞线程。 自旋锁本身是有缺点的,它不能代替阻塞。如果锁被占用的时间很长,那么自旋的线程只会白白浪费处理器资源,带来性能上的浪费,所以使用自旋锁时需要根据具体的应用场景来权衡其利弊。
在Java中,可以使用java.util.concurrent.atomic包下的原子类来实现自旋锁,其中AtomicInteger常被用来实现简单的自旋锁。
public class SpinLock {
private volatile boolean locked = false;
public void lock() {
// 自旋等待获取锁
while (locked);
// 获取到锁后,将 locked 设置为 true
locked = true;
}
public void unlock() {
// 释放锁
locked = false;
}
public static void main(String[] args) {
SpinLock spinLock = new SpinLock();
// 线程1
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 1 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
// 线程2
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 2 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
}
}
为什么要使用自旋锁?在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。
简单来说就是,避免切换线程带来的开销。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。
反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
自旋锁在JDK 1.4中引入,默认关闭,但是可以使用
-XX:+UseSpinning开启。在JDK1.6中默认开启,同时自旋的默认次数为10次,可以通过参数-XX:PreBlockSpin来调整。
如果通过参数-XX:PreBlockSpin来调整自旋锁的自旋次数会带来诸多不便。假如将参数调整为10,但是系统很多线程都是等你刚刚退出的时候就释放了锁,假如多自旋一两次就可以获取锁。于是JDK1.6引入适应性自旋锁。
适应性自旋锁是对自旋的升级、优化,自旋的时间不再固定,它根据当前锁的使用情况动态调整自旋等待时间。 如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。 如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
public class AdaptiveSpinLock {
private static final int MIN_SPIN_COUNT = 10;
private static final int MAX_SPIN_COUNT = 1000;
private AtomicBoolean locked = new AtomicBoolean(false);
private int spinCount = MIN_SPIN_COUNT; // 初始自旋等待次数设定为最小值
public void lock() {
int spins = spinCount; // 获取当前自旋次数
while (!locked.compareAndSet(false, true)) {
if (spins < MAX_SPIN_COUNT) {
spins++; // 自旋次数递增
}
// 在真实场景中,可能需要添加短暂的延时,避免过多占用CPU资源
for (int i = 0; i < spins; i++) {
Thread.onSpinWait(); // 在Java 9及以上版本中,可以使用Thread.onSpinWait()来优化自旋等待
}
}
spinCount = spins; // 更新自旋次数
}
public void unlock() {
locked.set(false);
}
public static void main(String[] args) {
AdaptiveSpinLock spinLock = new AdaptiveSpinLock();
// 线程1
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 1 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
// 线程2
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 2 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
}
}
偏向锁是Java中针对加锁操作进行的一种优化机制,主要针对只有一个线程访问同步块的场景。它的设计初衷是在无竞争的情况下,减少不必要的同步原语的性能消耗。
《深入理解Java虚拟机》对偏向锁的解释:
Hotspot的作者经过以往的研究发现大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。 当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程 ID,以后该线程在进入和退出同步块时不需要花费CAS操作来加锁和解锁,而只需简单的测试一下对象头的MarkWord里是否存储着指向当前线程的偏向锁,如果测试成功,表示线程已经获得了锁,如果测试失败,则需要再测试下MarkWord中偏向锁的标识是否设置成 1(表示当前是偏向锁),如果没有设置,则使用 CAS 竞争锁,如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
之所以叫偏向锁是因为偏向于第一个获取到他的线程,如果在程序执行中该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。 但是如果线程间存在锁竞争,偏向锁会失效,此时会涉及到锁的撤销,将锁状态升级为适合多线程竞争的轻量级锁或者重量级锁,这个过程可能会引入额外的开销,影响性能。
当一个线程访问同步块时,首先会尝试获取偏向锁。如果同步块之前没有被其他线程锁定,当前线程会尝试获取偏向锁,并将对象头的标记位设置为偏向锁。 如果其他线程尝试访问该同步块,会检测到该同步块已经被偏向锁定,会尝试撤销偏向锁,升级为轻量级锁或者重量级锁。 如果偏向线程已经不再访问该同步块,那么该对象头的标记位会被设置成无锁状态,接着是无锁状态。
根据锁的竞争情况来划分可以分为重量级锁和轻量级锁。
在Java中轻量级锁的经典实现是CAS中的自旋锁。优点是竞争的线程不会阻塞,提高了程序的响应速度;缺点是如果始终得不到锁竞争的线程,使用自旋会消耗CPU。所以轻量级锁适合,追求响应时间,同步块执行速度非常快的场景。 重量级锁依赖于操作系统提供的底层同步机制。优点是线程竞争不使用自旋,不会消耗CPU;缺点是当多个线程竞争同一个锁时,会直接阻塞等待,直到获取到锁的线程释放锁资源。适合追求吞吐量、同步块执行时间较长也就是线程竞争激烈的场景。
轻量级锁不是在任何情况下都比重量级锁快的,要看同步块执行期间有没有多个线程抢占资源的情况。如果有,那么轻量级线程要承担CAS+互斥锁的性能消耗,就会比重量锁执行的更慢。
可中断锁顾名思义,就是可以中断的锁。 如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
在Java中synchronized就是不可中断锁,Lock是可中断锁。
public class SynchronizedExample {
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
try {
Thread.sleep(5000); // 模拟线程持有锁的操作
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "Thread-1");
Thread thread2 = new Thread(() -> {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
}
}, "Thread-2");
thread1.start();
Thread.sleep(1000); // 让Thread-1先获取锁
thread2.start();
// 等待线程执行完成
thread1.join();
thread2.join();
}
}
public class LockExample {
private static final Lock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
Thread.sleep(5000); // 模拟线程持有锁的操作
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "Thread-1");
Thread thread2 = new Thread(() -> {
try {
if (lock.tryLock()) { // 可中断地尝试获取锁
try {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
} finally {
lock.unlock();
}
} else {
System.out.println(Thread.currentThread().getName() + " unable to acquire the lock");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "Thread-2");
thread1.start();
Thread.sleep(1000); // 让Thread-1先获取锁
thread2.start();
// 等待线程执行完成
thread1.join();
thread2.join();
}
}
互斥锁是一种用于多线程编程中的同步原语,用于确保在任何时刻,只有一个线程可以访问共享资源,从而避免数据竞争和并发访问的冲突。 在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为"互斥锁"的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
互斥锁在访问共享资源之前对对象进行加锁操作,在访问完成之后进行解锁操作。加锁后,任何其他试图再次加锁的线程会被阻塞,直到当前线程解锁其他线程才能访问公共资源。 如果在解锁时有多个线程在等待获取锁,一旦锁被释放,它们将竞争重新获取锁。只有第一个竞争到锁的线程会变为就绪状态并开始执行,其他线程将继续等待。
在Java里最基本的互斥手段就是使用synchronized关键字、ReentrantLock。
public class SynchronizedMutexExample {
private static int counter = 0;
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Runnable task = () -> {
synchronized (lock) {
for (int i = 0; i < 10000; i++) {
counter++;
}
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Counter: " + counter);
}
}
死锁并不是Java程序中通俗意义上的"锁",而是程序中出现的一种问题。之所以放到“锁”这个标题下是为了方便类比,就类似谐音梗吧。
死锁是指两个或多个线程在执行过程中,由于竞争资源或者互相等待释放资源而造成的一种僵局,使得所有参与的线程无法继续执行。 举个例子,当线程A持有锁a并尝试获取锁b,线程B持有锁b并尝试获取锁a时,就会出现死锁。简单来说,死锁问题的产生是由两个或者以上线程并行执行的时候,争夺资源而互相等待造成的。
public class MainTest {
public static void main(String[] args) {
String lockA = "lockA";
String lockB = "lockB";
new Thread(new ThreadHolderLock(lockA,lockB),"线程AAA").start();
new Thread(new ThreadHolderLock(lockB,lockA),"线程BBB").start();
}
}
class ThreadHolderLock implements Runnable{
private String lockA;
private String lockB;
public ThreadHolderLock(String lockA, String lockB){
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
synchronized (lockA){
System.out.println(Thread.currentThread().getName() + "\t 持有锁 "+ lockA+", 尝试获得"+ lockB);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lockB){
System.out.println(Thread.currentThread().getName() + "\t 持有锁 "+ lockB+", 尝试获得"+ lockA);
}
}
}
}
想要如何避免死锁,就要弄清楚死锁出现的原因,造成死锁必须达成的4个条件:
避免死锁的产生就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破循环等待条件。 资源有序分配法指的是,线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。 给资源分配一个全局的唯一编号,进程必须按资源编号的顺序请求资源。这种方法可以避免循环等待,从而防止死锁。
class Resource {
private final int id;
public Resource(int id) {
this.id = id;
}
public int getId() {
return id;
}
}
class Process extends Thread {
private final int id;
private final Resource[] resources;
public Process(int id, Resource[] resources) {
this.id = id;
this.resources = resources;
}
@Override
public void run() {
try {
acquireResources();
// 模拟处理
Thread.sleep((int) (Math.random() * 1000));
releaseResources();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void acquireResources() throws InterruptedException {
for (Resource resource : resources) {
synchronized (resource) {
System.out.println("Process " + id + " acquired Resource " + resource.getId());
}
}
}
private void releaseResources() {
for (Resource resource : resources) {
synchronized (resource) {
System.out.println("Process " + id + " released Resource " + resource.getId());
}
}
}
}
public class ResourceOrderingExample {
public static void main(String[] args) {
Resource resource1 = new Resource(1);
Resource resource2 = new Resource(2);
Resource resource3 = new Resource(3);
Process process1 = new Process(1, new Resource[]{resource1, resource2});
Process process2 = new Process(2, new Resource[]{resource2, resource3});
Process process3 = new Process(3, new Resource[]{resource3, resource1});
process1.start();
process2.start();
process3.start();
}
}
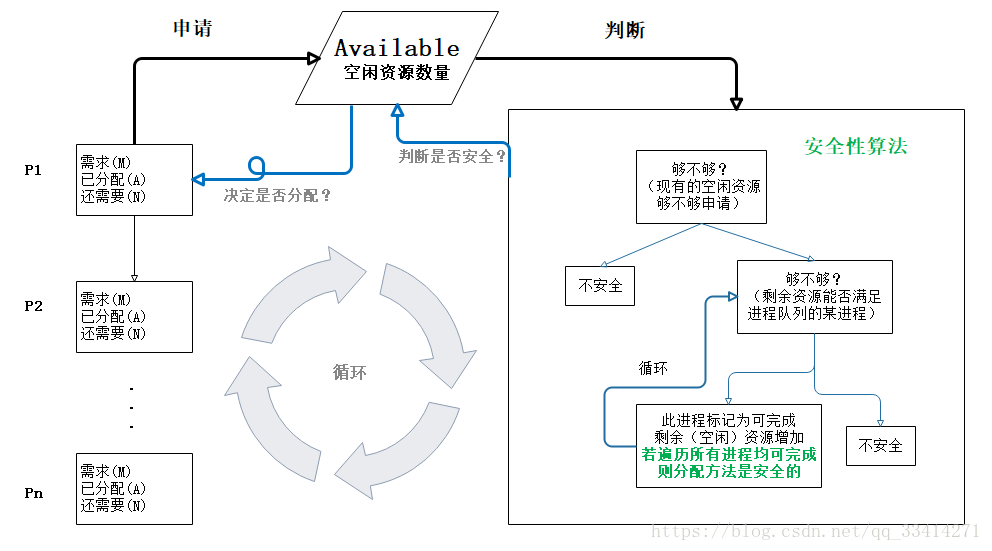
银行家算法:一个避免死锁的著名算法,是由艾兹格·迪杰斯特拉在1965年为T.H.E系统设计的一种避免死锁产生的算法。它以银行借贷系统的分配策略为基础,判断并保证系统的安全运行。
在银行中,客户申请贷款的数量是有限的,每个客户在第一次申请贷款时要声明完成该项目所需的最大资金量,在满足所有贷款要求时,客户应及时归还。银行家在客户申请的贷款数量不超过自己拥有的最大值时,都应尽量满足客户的需要。通过判断借贷是否安全,然后决定借不借。 举例,现有公司B、公司A、公司T,想要从银行分别贷款70亿、40亿、50亿,假设银行只有100亿供放贷,如果借不到企业最大需求的钱,钱将不会归还,怎么才能合理的放贷?
| 公司 | 最大需求 | 已借走 | 最多还借 |
|---|---|---|---|
| B | 70 | 20 | 50 |
| A | 40 | 10 | 30 |
| T | 50 | 30 | 20 |
此时公司B、A、T已经从银行借走60亿,银行还剩40亿。此时银行可放贷金额组合:
class Banker {
private int[] available; // 系统可用资源
private int[][] maximum; // 每个进程的最大资源需求
private int[][] allocation; // 每个进程当前已分配的资源
private int[][] need; // 每个进程剩余的资源需求
public Banker(int[] available, int[][] maximum) {
this.available = available;
this.maximum = maximum;
int numProcesses = maximum.length;
int numResources = available.length;
allocation = new int[numProcesses][numResources];
need = new int[numProcesses][numResources];
for (int i = 0; i < numProcesses; i++) {
for (int j = 0; j < numResources; j++) {
need[i][j] = maximum[i][j]; // 初始时,Need等于Maximum
}
}
}
// 请求资源的方法
public synchronized boolean requestResources(int processId, int[] request) {
if (!isRequestValid(processId, request)) {
return false; // 请求不合法,拒绝请求
}
// 试探性分配
for (int i = 0; i < available.length; i++) {
available[i] -= request[i];
allocation[processId][i] += request[i];
need[processId][i] -= request[i];
}
// 安全性检查
boolean safe = isSafeState();
if (!safe) {
// 如果不安全,恢复试探性分配前的状态
for (int i = 0; i < available.length; i++) {
available[i] += request[i];
allocation[processId][i] -= request[i];
need[processId][i] += request[i];
}
}
return safe;
}
private boolean isRequestValid(int processId, int[] request) {
for (int i = 0; i < request.length; i++) {
if (request[i] > need[processId][i] || request[i] > available[i]) {
return false; // 请求超出需求或可用资源
}
}
return true;
}
private boolean isSafeState() {
int[] work = available.clone();
boolean[] finish = new boolean[allocation.length];
while (true) {
boolean found = false;
for (int i = 0; i < allocation.length; i++) {
if (!finish[i]) {
boolean canProceed = true;
for (int j = 0; j < work.length; j++) {
if (need[i][j] > work[j]) {
canProceed = false;
break;
}
}
if (canProceed) {
for (int j = 0; j < work.length; j++) {
work[j] += allocation[i][j];
}
finish[i] = true;
found = true;
}
}
}
if (!found) {
break;
}
}
for (boolean f : finish) {
if (!f) {
return false; // 存在未完成的进程,系统不安全
}
}
return true; // 所有进程都完成,系统安全
}
}
public class BankerExample {
public static void main(String[] args) {
int[] available = {3, 3, 2};
int[][] maximum = {
{7, 5, 3},
{3, 2, 2},
{9, 0, 2},
{2, 2, 2},
{4, 3, 3}
};
Banker banker = new Banker(available, maximum);
int[] request1 = {1, 0, 2};
boolean granted1 = banker.requestResources(1, request1);
System.out.println("Request 1 granted: " + granted1);
int[] request2 = {3, 3, 0};
boolean granted2 = banker.requestResources(4, request2);
System.out.println("Request 2 granted: " + granted2);
int[] request3 = {2, 0, 0};
boolean granted3 = banker.requestResources(0, request3);
System.out.println("Request 3 granted: " + granted3);
}
}
使用 java.util.concurrent.locks.ReentrantLock 的 tryLock方法可以尝试获取锁,并设置超时时间,避免长时间等待造成的死锁。
class Process extends Thread {
private final int id;
private final Lock lock1;
private final Lock lock2;
public Process(int id, Lock lock1, Lock lock2) {
this.id = id;
this.lock1 = lock1;
this.lock2 = lock2;
}
@Override
public void run() {
try {
while (true) {
if (lock1.tryLock(50, TimeUnit.MILLISECONDS)) {
try {
if (lock2.tryLock(50, TimeUnit.MILLISECONDS)) {
try {
System.out.println("Process " + id + " acquired both locks");
// 模拟处理
Thread.sleep((int) (Math.random() * 1000));
return;
} finally {
lock2.unlock();
}
}
} finally {
lock1.unlock();
}
}
// 等待一段时间再重试
Thread.sleep((int) (Math.random() * 50));
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class TryLockExample {
public static void main(String[] args) {
Lock lock1 = new ReentrantLock();
Lock lock2 = new ReentrantLock();
Process process1 = new Process(1, lock1, lock2);
Process process2 = new Process(2, lock2, lock1);
process1.start();
process2.start();
}
}
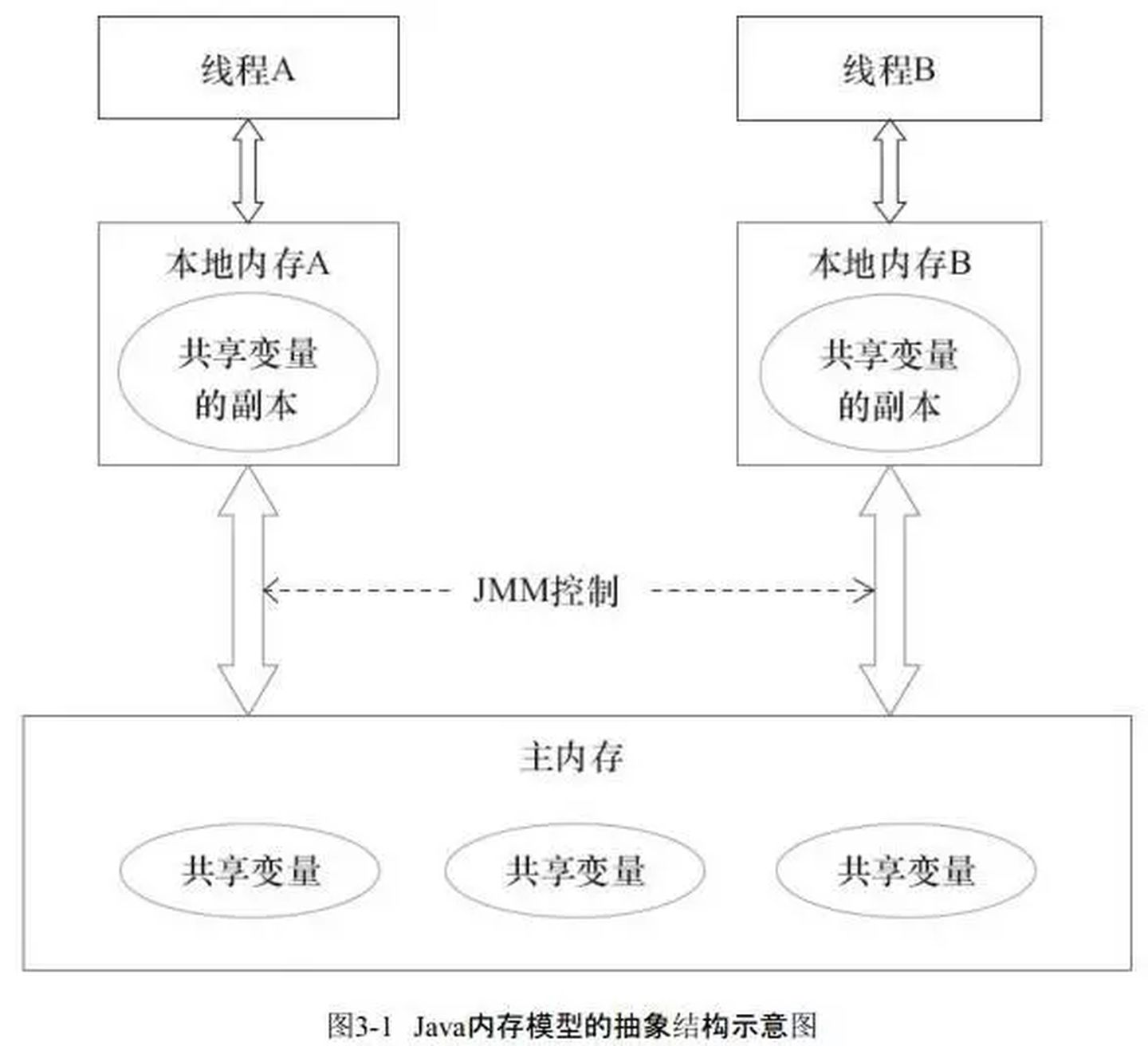
Java内存模型,即JMM(Java Memory Model)本身是一种抽象的概念,并不真实存在。 它定义了Java程序中多线程间如何通过内存进行交互的规则和规范。屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。 JMM规定了变量的读取和写入如何在主内存和各线程的工作内存之间进行,保证了并发编程的原子性、可见性及有序性。 内存模型解决并发问题主要采用两种方式,限制处理器优化和使用内存屏障。
原子性指的是一个操作或一组操作在执行时不可被中断,即这些操作要么全部完成,要么全部不完成。
在Java中,为了保证原子性,提供了两个高级的字节码指令 monitorenter 和 monitorexit。对应的就是Java中的关键字 synchronized,在Java中只要被synchronized修饰就能保证原子性。
public synchronized void increment() {
count++;
}
可见性指的是一个线程对共享变量的修改,能够及时被其他线程看到。Java提供了volatile关键字和synchronized关键字来保证变量的可见性。
public class SharedData {
private volatile boolean flag = false;
public void setFlag(boolean value) {
flag = value;
}
public boolean getFlag() {
return flag;
}
}
有序性指的是程序的执行顺序按照代码的顺序执行,编译器和处理器可能会进行优化,但这些优化不会影响单线程的语义。
在Java中,可以使用synchronized和volatile来保证多线程之间操作的有序性。其中volatile 关键字会禁止编译器指令重排,来保证。
synchronized 关键字保证同一时刻只允许一条线程操作,而不能禁止指令重排,指令重排并不会影响单线程的顺序,它影响的是多线程并发执行的顺序性,从而保证了有序性。
public class Example {
private int a = 0;
private boolean flag = false;
public synchronized void write() {
a = 1; // 1
flag = true; // 2
}
public synchronized void read() {
if (flag) { // 3
System.out.println(a); // 4
}
}
}
在多线程环境下,Java语句可能会不按照顺序执行,所以要注意数据的依赖性。计算机在执行程序时,为了提高性能,编译器和处理器常常会做指令重排,一把分为以下两种:
处理器和编译器为了提高执行效率,会对指令进行优化重排序。虽然这种优化不会影响单线程程序的执行结果,但在多线程环境下可能导致意外的行为。 Java 内存模型通过以下方式限制处理器和编译器的优化:
volatile关键字:声明为volatile的变量会被直接写入主内存,并且在读取时直接从主内存中读取。volatile 禁止了指令重排序,保证了变量的可见性和有序性。
private volatile boolean flag = true;
synchronized 关键字:进入同步块时,会触发获取锁的操作,这会刷新线程的工作内存,从主内存中读取最新值;退出同步块时,会触发释放锁的操作,这会将工作内存中的值写回主内存。
synchronized 也禁止了指令重排序,保证了变量的原子性和可见性。
public synchronized void increment() {
count++;
}
内存屏障,也称为内存栅栏,是一种用于防止处理器和编译器对内存操作进行重排序的指令。 内存屏障通过插入特殊的指令来强制某些操作的顺序执行,从而确保多线程环境下的正确性。Java内存模型在底层实现中使用了内存屏障来保证内存操作的有序性和可见性。
内存屏障主要分为四种类型,在Java中内存屏障被隐式地应用于某些关键字和类中,用来确保线程安全和内存可见性。
LoadLoad屏障:确保在该屏障之前的所有 load 操作都完成后,才能执行该屏障后面的 load 操作。这种屏障保证了前面的 load 操作对后面的 load 操作的可见性。
SharedData data = ...; // 获取共享对象的引用
while (!data.flag) {
// 使用 LoadLoad 屏障保证可见性
// 在这里插入 LoadLoad 屏障确保读取到最新的 flag 值
}
// 使用 LoadLoad 屏障保证可见性
int result = data.x; // 3. Load 操作
StoreStore屏障:保证在该屏障之前的所有 store 操作都完成后,才能执行该屏障后面的 store 操作。这确保了前面的 store 操作对后面的 store 操作的可见性。
data.x = 42; // 1. Store 操作
// 使用 StoreStore 屏障确保顺序性
data.flag = true; // 2. Store 操作
LoadStore屏障:确保在该屏障之前的所有 load 操作都完成后,才能执行该屏障后面的 store 操作。这种屏障保证了前面的 load 操作对后面的 store 操作的可见性。
while (!data.flag) {
// Spin until flag is true
}
// 使用 LoadStore 屏障保证顺序性
int result = data.x; // 3. Load 操作
StoreLoad屏障:保证在该屏障之前的所有 store 操作都完成后,才能执行该屏障后面的 load 操作。这确保了前面的 store 操作对后面的 load 操作的可见性。
data.x = 42; // 1. Store 操作
// 使用 StoreLoad 屏障保证可见性
data.flag = true; // 2. Store 操作
// 在另一个线程 B 中
while (!data.flag) {
// Spin until flag is true
}
int result = data.x; // 3. Load 操作
“Happens-Before"原则是Java内存模型中的一个核心概念,用来定义多个线程之间操作的执行顺序和内存可见性。 如果一个操作A在另一个操作B之前,那么在内存模型中,A的所有操作结果对于B是可见的,并且A的执行顺序在B之前。
public class ProgramOrderExample {
public void example() {
int a = 1; // 1. Happens-Before
int b = a + 1; // 2. Happens-Before
}
}
需要注意的是两个操作之间存在Happens-Before关系,并不意味着Java的具体实现必须要按照Happens-Before关系指定的顺序来执行。 如果重排序之后的执行结果,与按Happens-Before关系来执行的结果一致,那么JMM允许这种重排序。JMM只要求在最终的执行结果上保持与Happens-Before关系一致的语义。
public class HappensBeforeExample {
private static int x = 0;
private static boolean flag = false;
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
x = 1; // Statement 1
flag = true; // Statement 2
});
Thread thread2 = new Thread(() -> {
if (flag) { // Statement 3
System.out.println("x = " + x); // Statement 4
} else {
System.out.println("flag is false");
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
}
}
根据Happens-Before规则:
x = 1 的操作 Happens-Before flag = true 的操作。flag = true 的操作 Happens-Before if (flag) 的操作。如果thread2观察到flag的值为true,则说明 Happens-Before 原则保证了在此之前的操作结果对于其他线程是可见的。但是只要不改变程序的最终执行结果和Happens-Before关系,Java内存模型允许编译器和处理器进行指令重排序。
thread1可能会将flag设置 true之后才设置 x 的值为1。这种情况下,thread2在检查flag之后,可能会观察到 x = 1。
这种情况仍然满足Happens-Before关系,尽管发生了重排序。
“Happens-Before"原则在Java内存模型中包含8条具体的规则:
int a = 1; // 1. Happens-Before
int b = 2; // 2. Happens-Before
synchronized(lock) {
// 操作 A
}
// 锁的释放 Happens-Before 后续的加锁
synchronized(lock) {
// 操作 B
}
volatile变量规则。对一个 volatile 变量的写操作,一定早于随后对这个变量的读操作。
volatile boolean flag = false;
flag = true; // 写操作 Happens-Before
if (flag) { // 读操作
// flag 的写操作 Happens-Before flag 的读操作
}
Thread t = new Thread(() -> {
// 操作 B
});
t.start(); // 启动操作 Happens-Before
Thread t = new Thread(() -> {
// 操作 A
});
t.start();
t.join(); // A Happens-Before join 返回
Thread t = new Thread(() -> {
// 检测中断
if (Thread.interrupted()) {
// 中断事件发生
}
});
t.start();
t.interrupt(); // Happens-Before 检测中断
class MyObject {
@Override
protected void finalize() {
// 构造函数 Happens-Before finalize 方法
}
}
Thread t1 = new Thread(() -> {
// 操作 A
});
Thread t2 = new Thread(() -> {
// 操作 B
});
t1.start();
t1.join(); // A Happens-Before join 返回
t2.start();
t2.join(); // join 返回 Happens-Before B
为了提高并行度,优化程序性能,编译器和处理器会对代码进行指令重排序。但为了不改变程序的执行结果,尽可能地提高程序执行的并行度,编译器、必须遵守as-if-serial语义。
“as-if-serial"最初来自于计算机科学领域中的编译优化和程序行为的讨论。 这个概念的核心思想是,编译器和计算机系统在进行优化时,可以重新排列和改变指令的执行顺序,只要最终程序的执行结果与按照程序顺序执行时的结果一致即可。 这个原则确保了编译器和硬件系统在优化时不会改变程序的语义和行为。就是不管怎么重排序,单线程程序的执行结果不能被改变。
编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。
int a=1;
int b=2;
int c=a+b;
a和c之间存在数据依赖关系,同时b和c之间也存在数据依赖关系。因此在最终执行的指令序列中,c不能被重排序到A和B的前面,c如果排到a和b的前面,程序的结果将会被改变。 a和b之间没有数据依赖关系,编译器和处理器可以重排序a和b之间的执行顺序。
volatile通常被比喻成轻量级的锁,是Java并发编程中比较重要的一个关键字。volatile作用:
volatile 变量的值,新的值对于其他线程是立即可见的。这避免了其他线程读取到旧的缓存值。volatile 变量的读写操作不会被重排序。所有对 volatile 变量的写操作在内存中会按照程序的顺序执行,同时在一个线程中的操作不会重排序到 volatile 变量的读写操作之后。注意volatile不保证原子性,也就是线程不安全。
在Java中volatile是一个变量修饰符,只能用来修饰变量。volatile典型的使用就是单例模式中的双重检查锁实现。
/**
多线程下的单例模式 DCL(double check lock)
**/
class SingletonDemo {
// volatile 此处作用 禁止指令重排
public static volatile SingletonDemo singleton = null;
private SingletonDemo() {
}
public static SingletonDemo getInstance() {
if (singleton == null) {
synchronized (SingletonDemo.class) {
if (singleton == null) {
singleton = new SingletonDemo();
}
}
}
return singleton;
}
}
为什么在此处要使用volatile修饰singleton?
多线程下的DCL单例模式,如果不加volatile修饰不是绝对安全的,因为在创建对象的时候JVM底层会进行三个步骤:
其中步骤2和步骤3是没有数据依赖关系的,而且无论重排前还是重排后的程序执行结果在单线程中并没有改变,因此这种重排优化是允许的。
所以有可能先执行步骤3在执行步骤2,导致分配的对象不为null,但对象没有被初始化。所以当一个线程获取对象不为null时,由于对象未必已经完成初始化,会存在线程不安全的风险。
各个线程对主内存中共享变量的操作,都是各个线程各自拷贝到自己的工作内存操作后再写回主内存中的。 这就可能存在一个线程AAA修改了共享变量X的值还未写回主内存中时 ,另外一个线程BBB又对内存中的一个共享变量X进行操作,但此时A线程工作内存中的共享比那里X对线程B来说并不不可见。 这种工作内存与主内存同步延迟现象就造成了可见性问题。
这种变量的可见性问题可以用volatile来解决。volatile的作用简单来说就是当一个线程修改了数据,并且写回主物理内存,其他线程都会得到通知获取最新的数据。
public class MainTest {
public static void main(String[] args) {
A a = new A();
// thread1
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " is come in");
try {
// 模拟执行其他业务
Thread.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 用该线程改变A类中 number 变量的值
a.numberTo100();
}, "thread1").start();
// 如果number 等于0,则其他线程会一直等待 则证明 volatile 没有保证变量的可见性;相反则保证了变量的可见性
while (a.number == 0) {
}
System.out.println(Thread.currentThread().getName() + " thread is over");
}
}
class A {
// 注意: 此时变量要加 volatile 关键字修饰; 可以去掉 volatile 来进行对比测试
volatile int number = 0;
public void numberTo100() {
System.out.println(Thread.currentThread().getName() + " update number");
this.number = 100;
}
}
为什么volatile能确保变量的可见性?
将上面单例模式DCL实现用命令javap -v SingletonDemo.class >test.txt命令执行,将反编译后的字节码指令写入到test文件中,可以看到ACC_VOLATILE。
public static volatile content.posts.rookie.SingletonDemo singleton;
descriptor: Lcontent/posts/rookie/SingletonDemo;
flags: ACC_PUBLIC, ACC_STATIC, ACC_VOLATILE
volatile在字节码层面,就是使用访问标志ACC_VOLATILE来表示,供后续操作此变量时判断访问标志是否为ACC_VOLATILE,来决定是否遵循volatile的语义处理。
可以从openjdk8中找到对应的源码文件:
openjdk8/hotspot/src/share/vm/interpreter/bytecodeInterpreter.cpp
重点是cache->is_volatile()方法,调用栈如下:
bytecodeInterpreter.cpp>is_volatile()
==> accessFlags.hpp>is_volatile
==> bytecodeInterpreter.cpprelease_byte_field_put
==> oop.inline.hpp>(oopDesc::byte_field_acquire、oopDesc::release_byte_field_put)
==> orderAccess.hpp
>> orderAccess_linux_x86.inline.hpp.OrderAccess::release_store
最终调用了OrderAccess::release_store。
inline void OrderAccess::release_store(volatile jbyte* p, jbyte v) { *p = v; }
inline void OrderAccess::release_store(volatile jshort* p, jshort v) { *p = v; }
可以从上面看到C++的实现层面,又使用C++中的volatile关键字,用来修饰变量,通常用于建立语言级别的内存屏障memory barrier。
在《C++ Programming Language》一书中对volatile修饰词的解释:
A volatile specifier is a hint to a compiler that an object may change its value in ways not specified by the language so that aggressive optimizations must be avoided.
volatile修饰的类型变量表示可以被某些编译器未知的因素更改。volatile 变量时,避免激进的优化。系统总是重新从内存读取数据,即使它前面的指令刚从内存中读取被缓存,防止出现未知更改和主内存中不一致。其在64位系统的实现orderAccess_linux_x86.inline.hpp.OrderAccess::release_store。
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
其中代码lock; addl $0,0(%%rsp)就是常说的lock前缀。
lock前缀,会保证某个处理器对共享内存的独占使用。它将本处理器缓存写入内存,该写入操作会引起其他处理器或内核对应的缓存失效。通过独占内存、使其他处理器缓存失效,达到了“指令重排序无法越过内存屏障”的作用。
对于 volatile修饰的变量,当对 volatile 修饰的变量进行写操作的时候,JVM会向处理器发送一条带有lock前缀的指令,将这个缓存中的变量回写到系统主存中。
但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议。
缓存一致性协议: 每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
为了提高CPU处理器的执行速度,在处理器和内存之间增加了多级缓存来提升。但是由于引入了多级缓存,就存在缓存数据不一致问题。
所以如果一个变量被volatile所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。
而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个volatile在并发编程中,其值在多个缓存中是可见的。
有序性指的就是代码按照顺序执行,是对比指令重排来说的。计算机在执行程序时,为了提高性能,编译器和处理器常常会做指令重排。 在上面的使用案例中的代码,单例模式DCL就是一个使用禁止指令重排的案例。
volatile禁止指令重排的原因是什么?volatile 关键字通过在读写操作前后插入内存屏障来禁止指令重排序,从而确保了内存可见性和操作的有序性。
volatile变量时:StoreStore 屏障,确保在写入 volatile 变量之前的所有普通写操作都已经完成。StoreLoad 屏障,确保在写入 volatile 变量之后的所有普通读操作都能读取到最新的值。volatile变量时:LoadLoad 屏障,确保在读取 volatile 变量之前的所有普通读操作都已经完成。LoadStore 屏障,确保在读取 volatile 变量之后的所有普通写操作都能读取到最新的值。class Example {
private volatile boolean flag = false;
private int value = 0;
public void writer() {
value = 42; // 1. 普通写操作
flag = true; // 2. volatile 写操作
}
public void reader() {
if (flag) { // 3. volatile 读操作
int result = value; // 4. 普通读操作
}
}
}
volatile不保证原子性,也就是线程不安全。
public class MainTest {
public static void main(String[] args) {
A a = new A();
/**
* 创建20个线程 每个线程让 number++ 1000次;
* number 变量用 volatile 修饰
* 如果 volatile 保证变量的原子性,则最后结果为 20 * 1000,反之则不保证。
* 当然不排除偶然事件,建议反复多试几次。
*/
for (int i = 0; i < 20; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
a.addPlusplus();
}
}, String.valueOf(i)).start();
}
// 如果当前存活线程大于 2 个(包括main线程) 礼让线程继续执行上边的线程
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + " Thread is over\t" + a.number);
}
}
class A {
volatile int number = 0;
public void addPlusplus() {
this.number++;
}
}
不保证原子性的原因,由于各个线程之间都是复制主内存的数据到自己的工作空间里边修改数据,CPU的轮询反复切换线程,会导致数据丢失。 即某个线程修改了数据,准备回主内存,此时CPU切换到另一个线程修改了数据,并且写回到了主内存。其他的线程不知道主内存的数据已经被更改,还会执行将之前从主内存复制的数据修改后的,写到主内存,这就导致了数据被覆盖、丢失。
如果要解决原子性的问题,在Java中只能控制线程,在修改的时候不能被中断,即加锁。
public class MainTest {
public static void main(String[] args) {
A a = new A();
/**
* 创建20个线程 每个线程让 number++ 1000次;
* number 变量用 volatile 修饰
* 如果 volatile 保证变量的原子性,则最后结果为 20 * 1000,反之则不保证。
* 当然不排除偶然事件,建议反复多试几次。
*/
for (int i = 0; i < 20; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
a.addPlusplus();
}
}, String.valueOf(i)).start();
}
// 如果当前存活线程大于 2 个(包括main线程) 礼让线程继续执行上边的线程
while (Thread.activeCount() > 2) {
Thread.yield();
}
System.out.println(Thread.currentThread().getName() + " Thread is over\t" + a.number);
}
}
class A {
int number = 0;
/**
* 如果要解决原子性的问题可以用synchronized 关键字(这种太浪费性能)
* 可用JUC下的 AtomicInteger 来解决
**/
AtomicInteger atomicInteger = new AtomicInteger(number);
public void addPlusplus() {
number = atomicInteger.incrementAndGet();
}
}
对于AtomicInteger.incrementAndGet方法来说,原理就是volatile + do...while() + CAS;
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
//=========================
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
用volatile修饰该变量,保证该变量被某个线程修改时,保证其他线程中的这个变量的可见性。
在多线程环境下,CPU轮流切换线程执行,有可能某个线程修改了数据,准备回主内存,此时CPU切换到另一个线程修改了数据,并且写回到了主内存,此时就导致数据的不准确。
do...while() + CAS的作用就是,当某个线程工作内存中的值与主内存中的值,如果不相同就会一直while循环下去,之所以用do..while是考虑到做自增操作。
synchronized是Java提供的关键字译为同步,是Java中用于实现线程同步的一种机制。它可以确保在同一时间只有一个线程能够执行某段代码,从而避免线程安全问题。
当它修饰一个方法或者一个代码块的时候,同一时刻最多只有一个线程执行这段代码。synchronized关键字在需要原子性、可见性和有序性这三种特性的时候都可以作为其中一种解决方案,大部分并发控制操作都能使用synchronized来完成。
synchronized的作用:
synchronized 修饰的代码块或方法。synchronized 代码块时,它所做的所有修改对于进入 synchronized 代码块的其他线程是可见的。这是通过释放和获得监视器锁来实现的。| 修饰的对象 | 作用范围 | 作用对象 |
|---|---|---|
| 同步一个实例方法 | 整个实例方法 | 调用此方法的对象 |
| 同步一个静态方法 | 整个静态方法 | 此类的所有对象 |
| 同步代码块-对象 | 整个代码块 | 调用此代码块的对象 |
| 同步代码块-类 | 整个代码块 | 此类的所有对象 |
increment方法被声明为同步方法。当一个线程调用这个方法时,它会获得该实例的监视器锁,其他线程必须等待这个线程释放锁后才能调用这个方法。
public synchronized void increment() {
count++;
}
synchronized作用于静态方法时,其锁就是当前类的class对象锁。由于静态成员不专属于任何一个实例对象,而是类成员,因此通过class对象锁可以控制静态成员的并发操作。
public static synchronized void increment() {
count++;
}
public void increment() {
synchronized (this) {
count++;
}
}
synchronized(this)锁定,当然静态方法是没有this对象的,也可以使用class对象来做为锁。
public void increment() {
synchronized (MainTest.class) {
count++;
}
}
当如果没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的对象来充当锁。
private byte[] lock = new byte[0];
public void method(){
synchronized(lock) {
// .....
}
}
零长度的byte数组对象创建起来将比任何对象都经济。查看编译后的字节码,生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
byte[] emptyArray = new byte[0];
0: iconst_0 // 将常量0推送到栈顶
1: newarray byte // 创建一个新的byte类型数组
3: astore_1 // 将引用类型的数据存储到局部变量表中
Object lock = new Object();
0: new #2 // 创建一个新的对象
3: dup // 复制栈顶的操作数栈顶的值,并将复制值压入栈顶
4: invokespecial #1 // 调用实例初始化方法, 使用Object.<init>
7: astore_1 // 将引用类型的数据存储到局部变量表中
synchronized关键字在Java中通过进入和退出一个监视器来实现同步。监视器本质上是一种锁,它可以是类对象锁或实例对象锁。每个对象在JVM中都有一个与之关联的监视器。
当一个线程进入同步代码块或方法时,它会尝试获得对象的监视器。如果成功获得锁,线程就可以执行同步代码;否则它将被阻塞,直到获得锁为止。
在Java中synchronized锁对象时,其实就是改变对象中的对象头的markword的锁的标志位来实现的。用javap -v MainTest.class命令反编译下面代码。
public class MainTest {
synchronized void demo01() {
System.out.println("demo 01");
}
void demo02() {
synchronized (MainTest.class) {
System.out.println("demo 02");
}
}
}
synchronized void demo01();
descriptor: ()V
flags: ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String demo 01
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
// ...
void demo02();
descriptor: ()V
flags:
Code:
stack=2, locals=3, args_size=1
0: ldc #5 // class content/posts/rookie/MainTest
2: dup
3: astore_1
4: monitorenter
5: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
8: ldc #6 // String demo 02
10: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
13: aload_1
14: monitorexit
15: goto 23
18: astore_2
19: aload_1
20: monitorexit
21: aload_2
22: athrow
23: return
// ...
通过反编译后代码可以看出:
ACC_SYNCHRONIZED标记符来实现同步;monitorenter、monitorexit两个指令来实现同步;其中同步代码块,有两个monitorexit指令的原因是为了保证抛异常的情况下也能释放锁,所以javac为同步代码块添加了一个隐式的try-finally,在finally中会调用monitorexit命令释放锁。
官方文档中关于同步方法和同步代码块的实现原理描述:
方法级的同步是隐式的。同步方法的常量池中会有一个
ACC_SYNCHRONIZED标志。当某个线程要访问某个方法的时候,会检查是否有ACC_SYNCHRONIZED,如果有设置,则需要先获得监视器锁,然后开始执行方法,方法执行之后再释放监视器锁。这时如果其他线程来请求执行方法,会因为无法获得监视器锁而被阻断住。值得注意的是,如果在方法执行过程中,发生了异常,并且方法内部并没有处理该异常,那么在异常被抛到方法外面之前监视器锁会被自动释放。
同步代码块使用monitorenter和monitorexit两个指令实现。可以把执行monitorenter指令理解为加锁,执行monitorexit理解为释放锁。 每个对象维护着一个记录着被锁次数的计数器。未被锁定的对象的该计数器为0,当一个线程获得锁(执行monitorenter)后,该计数器自增变为 1 ,当同一个线程再次获得该对象的锁的时候,计数器再次自增。当同一个线程释放锁(执行monitorexit指令)的时候,计数器再自减。当计数器为0的时候。锁将被释放,其他线程便可以获得锁。
其实无论是ACC_SYNCHRONIZED还是monitorenter、monitorexit都是基于Monitor实现的,每一个锁都对应一个monitor对象。
在Java虚拟机(HotSpot)中,Monitor是基于C++实现的,由ObjectMonitor实现。在/hotspot/src/share/vm/runtime/objectMonitor.hpp中有ObjectMonitor的实现。
// initialize the monitor, exception the semaphore, all other fields
// are simple integers or pointers
ObjectMonitor() {
_header = NULL;
_count = 0; //记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
_owner:指向持有ObjectMonitor对象的线程;_WaitSet:存放处于wait状态的线程队列;_EntryList:存放处于等待锁block状态的线程队列;_recursions:锁的重入次数;_count:用来记录该线程获取锁的次数;当多个线程同时访问一段同步代码时,首先会进入_EntryList队列中,当某个线程获取到对象的monitor后进入_Owner区域,并把monitor中的_owner变量设置为当前线程,同时monitor中的计数器_count加1,即获得对象锁。
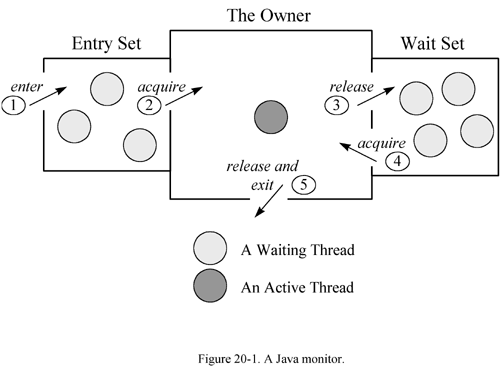
若此时持有monitor的线程调用wait()方法,将释放当前对象持有的monitor,_owner变量恢复为null,_count自减1,同时该线程进入_WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor并复位变量的值,以便其他线程进入获取monitor。
ObjectMonitor中其他方法:
bool try_enter (TRAPS) ;
void enter(TRAPS);
void exit(bool not_suspended, TRAPS);
void wait(jlong millis, bool interruptable, TRAPS);
void notify(TRAPS);
void notifyAll(TRAPS);
sychronized加锁的时候,会调用objectMonitor的enter方法,解锁的时候会调用exit方法。
在JDK1.6之前,synchronized的实现直接调用ObjectMonitor的enter和exit,这种锁被称之为重量级锁,这也是早期synchronized效率低的原因。
所以,在JDK1.6中出现对锁进行了很多的优化,进而出现轻量级锁,偏向锁,锁消除,适应性自旋锁,锁粗化。
早期的
synchronized效率低的原因: Java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统的帮忙,监视器锁monitor是依赖于底层的操作系统的Mutex Lock来实现的,而操作系统实现线程之间的切换时需要从用户态转换到核心态。因此状态转换需要花费很多的处理器时间。 对于代码简单的同步块(如被synchronized修饰的get、set方法)状态转换消耗的时间有可能比用户代码执行的时间还要长,所以说synchronized是Java语言中一个重量级的操作。也是为什么早期的synchronized效率低的原因。
在JDK1.6之前,使用synchronized被称作重量级锁,它的实现是基于底层操作系统的mutex互斥原语的,这个开销是很大的。所以在JDK1.6时JVM对synchronized做了优化。
synchronized锁对象时,其实就是改变对象中的对象头的markword的锁的标志位来实现的。对象头中markword锁状态的表示:
| 锁状态 | markword 锁标志位 |
|---|---|
| 无锁状态 | 01 |
| 偏向锁状态 | 01 |
| 轻量级锁状态 | 00 |
| 重量级锁状态 | 10 |
| 被垃圾回收器标记 | 11 |
对象的锁状态,可以分为4种,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。
其中这几个锁只有重量级锁是需要使用操作系统底层mutex互斥原语来实现,其他的锁都是使用对象头来实现的。
markword锁的标志位0,偏向锁的标志位为1;例如:刚被创建出来的对象。markword的结构变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,直接可以获取锁。
省去了大量有关锁申请的操作,从而也就提供程序的性能。MarkWord中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态,所以开销是很大。随着锁的竞争,锁从偏向锁升级到轻量级锁,再升级的重量级锁。锁升级过程:
ThreadID改成自己的ID,之后再次访问这个对象时,只需要对比ID,就不需要再使用CAS在进行操作。monitorexit指令释放锁。如果有其他线程在等待该锁,它们会被唤醒并竞争锁的所有权。在所有的锁都启用的情况下,线程进入临界区时会先获取偏向锁,如果已经存在偏向锁了,则会尝试获取轻量级锁,启用自旋锁。 如果自旋也没有获取到锁,则使用重量级锁,将没有获取到锁的线程阻塞挂起,直到持有锁的线程执行完同步块唤醒他们。
偏向锁是在无锁争用的情况下使用的,也就是同步代码块在当前线程没有执行完之前,没有其它线程会执行该同步块。 一旦有了第二个线程的争用,偏向锁就会升级为轻量级锁,如果轻量级锁自旋到达阈值后,没有获取到锁,就会升级为重量级锁。
锁可以升级,但是不可以降级,有的观点认为不会进行锁降级。 实际上,锁降级确实是会发生的,当JVM进入安全点的时候,会检查是否有闲置的`Monitor,然后试图进行降级。 也就是说,仅仅是发生在STW的时候,只有垃圾回收线程能够观测到它,在我们正常使用的过程中是不会发生锁降级的,只有在GC的时候才会降级。
安全点:程序执行时并非在所有地方都能停顿下来开始GC,只有在特定的位置才能停顿下来开始GC,这些位置称为安全点。
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。 不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。所以就可能出现线程1改了某个变量的值,但是线程2不可见的情况。
被synchronized修饰的代码,在开始执行时会加锁,执行完成后会进行解锁。但是为了保证可见性,有一条规则是这样的,“对一个变量解锁之前,必须先把此变量同步回主存中”,这样解锁后,后续线程就可以访问到被修改后的值。
所以synchronized关键字锁住的对象,其值是具有可见性的。
public class VisibilityExample {
private boolean flag = false;
public synchronized void toggleFlag() {
// 修改共享变量并确保可见性
flag = !flag;
// 其他操作
}
public synchronized boolean isFlag() {
// 读取共享变量并确保可见性
return flag;
}
}
原子性是指一个操作是不可中断的,要全部执行完成,要不就都不执行。
线程是CPU调度的基本单位,CPU有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去CPU使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。
在Java中,为了保证原子性,提供了两个高级的字节码指令monitorenter和monitorexit,这两个字节码指令,在Java中对应的关键字就是synchronized。
通过monitorexit和monitorexit指令,可以保证被synchronized修饰的代码在同一时间只能被一个线程访问,在锁未释放之前,无法被其他线程访问到。
因此在Java中可以使用synchronized来保证方法和代码块内的操作是原子性的。
举个例子,线程1在执行monitorenter指令的时候,会对Monitor进行加锁,加锁后其他线程无法获得锁,除非线程1主动解锁。
即使在执行过程中,由于某种原因,比如CPU时间片用完,线程1放弃了CPU,但是它并没有进行解锁。
而由于synchronized的锁是可重入的,下一个时间片还是只能被他自己获取到,还是会继续执行代码,直到所有代码执行完,这就保证了原子性。
public class AtomicityExample {
private int count = 0;
public synchronized void increment() {
// 原子性的递增操作
count++;
}
public synchronized void decrement() {
// 原子性的递减操作
count--;
}
public synchronized int getCount() {
// 原子性的读取操作
return count;
}
public static void main(String[] args) {
AtomicityExample example = new AtomicityExample();
// 线程1:递增操作
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
example.increment();
}
});
// 线程2:递减操作
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
example.decrement();
}
});
// 启动线程
thread1.start();
thread2.start();
try {
// 等待两个线程执行完成
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 输出最终的计数结果
System.out.println("Final Count: " + example.getCount());
}
}
有序性即程序执行的顺序按照代码的先后顺序执行。
除了引入了时间片以外,由于处理器优化和指令重排等,CPU还可能对输入代码进行乱序执行,比如load->add->save有可能被优化成load->save->add这就是可能存在有序性问题。
这里需要注意的是,synchronized是无法禁止指令重排和处理器优化的,也就是说synchronized无法避免上述提到的问题。
那synchronized是如何保证有序性的?
synchronized通过两个主要机制来保证有序性。synchronized的主要特性是互斥性,意味着在同一时刻只有一个线程可以进入同步块,既然是单线程就需要遵守as-if-serial语义,那么就可以认为单线程程序是按照顺序执行的。
as-if-serial语义:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果都不能被改变。编译器和处理器无论如何优化,都必须遵守as-if-serial语义。
第二个保证就是内存屏障。编译器和CPU在执行代码时,可能会为了优化性能进行指令重排,但synchronized块内的指令不会被重排。
原因就是Java内存模型通过在进入和退出synchronized块时插入内存屏障,来保证这些操作在多线程环境下的顺序执行。
在进入synchronized块时,会插入一个LoadLoad屏障和一个LoadStore屏障,确保在锁被获取后,前面的所有读操作和写操作都已经完成。
在退出synchronized块时,会插入一个StoreStore屏障和一个StoreLoad屏障,确保在锁被释放前,所有的写操作都已经完成,并且这些写操作对其他线程可见。
CAS全称为Compare and Swap被译为比较并交换,是一种无锁算法。用于实现并发编程中的原子操作。CAS操作检查某个变量是否与预期的值相同,如果相同则将其更新为新值。
CAS操作是原子的,这意味着在多个线程同时执行CAS操作时,不会发生竞争条件。
java.util.concurrent.atomic并发包下的所有原子类都是基于CAS来实现的。
public class CASExample {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(0);
int expectedValue = 0;
int newValue = 1;
boolean result = atomicInteger.compareAndSet(expectedValue, newValue);
if (result) {
System.out.println("更新成功,当前值:" + atomicInteger.get());
} else {
System.out.println("更新失败,当前值:" + atomicInteger.get());
}
}
}
CAS一些常见使用场景:
private AtomicInteger counter = new AtomicInteger(0);
public int increment() {
int oldValue, newValue;
do {
oldValue = counter.get();
newValue = oldValue + 1;
} while (!counter.compareAndSet(oldValue, newValue));
return newValue;
}
public class CASQueue<E> {
private static class Node<E> {
final E item;
final AtomicReference<Node<E>> next = new AtomicReference<>(null);
Node(E item) { this.item = item; }
}
private final AtomicReference<Node<E>> head = new AtomicReference<>(null);
private final AtomicReference<Node<E>> tail = new AtomicReference<>(null);
public void enqueue(E item) {
Node<E> newNode = new Node<>(item);
while (true) {
Node<E> currentTail = tail.get();
if (currentTail == null) {
if (head.compareAndSet(null, newNode)) { tail.set(newNode); return; }
} else {
if (currentTail.next.compareAndSet(null, newNode)) { tail.compareAndSet(currentTail, newNode); return; }
else { tail.compareAndSet(currentTail, currentTail.next.get()); }
}
}
}
public E dequeue() {
while (true) {
Node<E> currentHead = head.get();
if (currentHead == null) { return null; }
Node<E> nextNode = currentHead.next.get();
if (head.compareAndSet(currentHead, nextNode)) { return currentHead.item; }
}
}
}
public class OptimisticLocking {
private AtomicInteger version = new AtomicInteger(0);
public boolean updateWithOptimisticLock(int expectedVersion, Runnable updateTask) {
int currentVersion = version.get();
if (currentVersion != expectedVersion) { return false; }
updateTask.run();
return version.compareAndSet(currentVersion, currentVersion + 1);
}
public int getVersion() { return version.get(); }
public static void main(String[] args) {
OptimisticLocking lock = new OptimisticLocking();
Runnable updateTask = () -> System.out.println("Performing update");
int version = lock.getVersion();
boolean success = lock.updateWithOptimisticLock(version, updateTask);
if (success) { System.out.println("Update successful."); } else { System.out.println("Update failed."); }
}
}
public class CASThreadPool {
private static class Node<E> {
final E item;
final AtomicReference<Node<E>> next = new AtomicReference<>(null);
Node(E item) { this.item = item; }
}
private final AtomicReference<Node<Runnable>> head = new AtomicReference<>(null);
private final AtomicReference<Node<Runnable>> tail = new AtomicReference<>(null);
public void submitTask(Runnable task) {
Node<Runnable> newNode = new Node<>(task);
while (true) {
Node<Runnable> currentTail = tail.get();
if (currentTail == null) {
if (head.compareAndSet(null, newNode)) { tail.set(newNode); return; }
} else {
if (currentTail.next.compareAndSet(null, newNode)) { tail.compareAndSet(currentTail, newNode); return; }
else { tail.compareAndSet(currentTail, currentTail.next.get()); }
}
}
}
public Runnable getTask() {
while (true) {
Node<Runnable> currentHead = head.get();
if (currentHead == null) { return null; }
Node<Runnable> nextNode = currentHead.next.get();
if (head.compareAndSet(currentHead, nextNode)) { return currentHead.item; }
}
}
}
Unsafe是CAS的核心类,Java无法直接访问底层操作系统,而是通过native方法来访问。不过尽管如此,JVM还是开了一个后门,JDK中有一个类Unsafe,它提供了硬件级别的原子操作。
Unsafe类位于sun.misc包中,它提供了访问底层操作系统的特定功能,如直接内存访问、CAS 操作等。
由于其提供了直接操作内存的能力,使用不当可能导致内存泄漏、数据损坏等问题,应谨慎使用。
Unsafe类包含了许多不安全的操作,所以它并不是Java标准的一部分,而且在Java9开始已经标记为受限制的API。
Java中CAS操作的执行依赖于Unsafe类的方法,Unsafe类中的所有方法都是native修饰的,也就是说Unsafe类中的方法都直接调用操作系统底层资源执行相应任务。
public class UnsafeExample {
private static final Unsafe unsafe;
private static final long valueOffset;
private volatile int value = 0;
static {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
unsafe = (Unsafe) field.get(null);
valueOffset = unsafe.objectFieldOffset(UnsafeExample.class.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
public void increment() {
int current;
do {
current = unsafe.getIntVolatile(this, valueOffset);
} while (!unsafe.compareAndSwapInt(this, valueOffset, current, current + 1));
}
}
以AtomicInteger原子整型类为例,来看一下CAS实现原理。
public class MainTest {
public static void main(String[] args) {
new AtomicInteger().compareAndSet(1,2);
}
}
调用栈如下:
compareAndSet
--> unsafe.compareAndSwapInt
---> unsafe.compareAndSwapInt
--> (C++) cmpxchg
AtomicInteger内部方法都是基于Unsafe类实现的。
Unsafe是CAS的核心类,Java无法直接访问底层操作系统,而是通过native方法来访问。不过尽管如此,JVM还是开了一个后门,JDK中有一个类Unsafe,它提供了硬件级别的原子操作。
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
private volatile int value;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
compareAndSwapInt方法参数:
this:Unsafe对象本身,需要通过这个类来获取 value 的内存偏移地址;valueOffset: valueOffset 表示的是变量值在内存中的偏移地址,因为 Unsafe 就是根据内存偏移地址获取数据的原值的。expect:当前预期的值;update:要设置的新值;继续向底层深入,就会看到Unsafe类中的一些其他方法:
public final class Unsafe {
// ...
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
// ...
}
对应查看openjdk的hotspot源码,src/share/vm/prims/unsafe.cpp。
#define FN_PTR(f) CAST_FROM_FN_PTR(void*, &f)
{CC"compareAndSwapObject", CC"("OBJ"J"OBJ""OBJ")Z", FN_PTR(Unsafe_CompareAndSwapObject)},
{CC"compareAndSwapInt", CC"("OBJ"J""I""I"")Z", FN_PTR(Unsafe_CompareAndSwapInt)},
{CC"compareAndSwapLong", CC"("OBJ"J""J""J"")Z", FN_PTR(Unsafe_CompareAndSwapLong)},
最终在hotspot源码实现/src/share/vm/runtime/Atomic.cpp中都会调用统一的cmpxchg函数。
jbyte Atomic::cmpxchg(jbyte exchange_value, volatile jbyte*dest, jbyte compare_value) {
assert (sizeof(jbyte) == 1,"assumption.");
uintptr_t dest_addr = (uintptr_t) dest;
uintptr_t offset = dest_addr % sizeof(jint);
volatile jint*dest_int = ( volatile jint*)(dest_addr - offset);
// 对象当前值
jint cur = *dest_int;
// 当前值cur的地址
jbyte * cur_as_bytes = (jbyte *) ( & cur);
// new_val地址
jint new_val = cur;
jbyte * new_val_as_bytes = (jbyte *) ( & new_val);
// new_val存exchange_value,后面修改则直接从new_val中取值
new_val_as_bytes[offset] = exchange_value;
// 比较当前值与期望值,如果相同则更新,不同则直接返回
while (cur_as_bytes[offset] == compare_value) {
// 调用汇编指令cmpxchg执行CAS操作,期望值为cur,更新值为new_val
jint res = cmpxchg(new_val, dest_int, cur);
if (res == cur) break;
cur = res;
new_val = cur;
new_val_as_bytes[offset] = exchange_value;
}
// 返回当前值
return cur_as_bytes[offset];
}
从上述源码可以看出CAS操作通过CPU提供的原子指令cmpxchg来实现无锁操作,这个指令会保证在多个处理器同时访问和修改数据时的正确性。
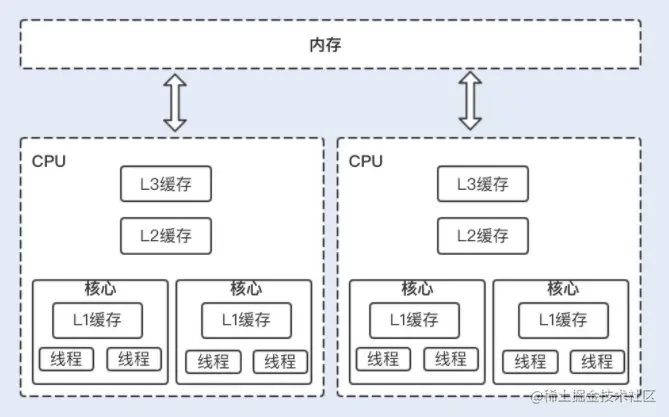
CPU处理器速度远远大于在主内存中的速度,为了加快访问速度,现代CPU引入了多级缓存,如L1、L2、L3 级别的缓存,这些缓存离CPU越近就越快。
这些缓存存储了频繁使用的数据,但在多处理器环境中,缓存的一致性成为了下一个问题。
当CPU中某个处理器对缓存中的共享变量进行了操作后,其他处理器会有个嗅探机制。即将其他处理器共享变量的缓存失效,当其他线程读取时会重新从主内存中读取最新的数据,这是基于MESI缓存一致性协议来实现的。
在多线程环境中,CAS就是比较当前线程工作内存中的值和主内存中的值,如果相同则执行规定操作,否则继续比较,直到主内存和当前线程工作内存中的值一致为止。
每个CPU核心都有自己的缓存,用于存储频繁访问的数据。当一个线程在某个CPU核心上修改了共享变量的值时,其他CPU核心上缓存中的该变量会被标记为无效,这样其他线程再访问该变量时就会重新从主内存中获取最新值,从而保证了数据的一致性。
CAS操作通过CPU提供的原子指令cmpxchg来比较和交换变量的值,它的原子性和线程安全性依赖于CPU的硬件支持和缓存一致性协议的保障。
所以当执行CAS方法时,读取变量当前的值,并与预期值进行比较。如果变量的当前值等于预期值,则将其更新为新值。如果变量的当前值不等于预期值,则不执行更新操作。 注意CAS操作是原子的,即整个过程不会被其他线程打断。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
getAndAddInt方法执行,如果CAS失败会一直会进行尝试,如果CAS长时间不成功,可能会给CPU带来很大的开销。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作。
public class AtomicReferenceSimpleExample {
static class DataObject {
private int var1;
private String var2;
public DataObject(int var1, String var2) {
this.var1 = var1;
this.var2 = var2;
}
}
public static void main(String[] args) {
// 创建一个 AtomicReference 实例,并初始化为一个 DataObject 对象
AtomicReference<DataObject> atomicRef = new AtomicReference<>(new DataObject(1, "Initial"));
// 执行 CAS 操作,修改 DataObject 对象的属性
atomicRef.updateAndGet(data -> {
data.setVar1(data.getVar1() + 10);
data.setVar2("Updated");
return data;
});
// 获取修改后的值
DataObject updatedObject = atomicRef.get();
System.out.println("Updated var1: " + updatedObject.getVar1());
System.out.println("Updated var2: " + updatedObject.getVar2());
}
}
public class ABASolutionWithVersion {
public static void main(String[] args) {
// 初始值为100,初始版本号为0
AtomicStampedReference<Integer> atomicRef = new AtomicStampedReference<>(100, 0);
int[] stampHolder = new int[1]; // 用于获取当前版本号
int expectedValue = 100; // 期望值
int newValue = 200; // 新值
// 模拟一个线程进行 ABA 操作
new Thread(() -> {
int stamp = atomicRef.getStamp(); // 获取当前版本号
atomicRef.compareAndSet(expectedValue, newValue, stamp, stamp + 1); // 修改值和版本号
atomicRef.compareAndSet(newValue, expectedValue, stamp + 1, stamp + 2); // 再次修改回原值和新版本号
}).start();
// 其他线程进行 CAS 操作
new Thread(() -> {
int stamp = atomicRef.getStamp(); // 获取当前版本号
boolean result = atomicRef.compareAndSet(expectedValue, newValue, stamp, stamp + 1);
System.out.println("CAS Result: " + result); // 输出CAS操作结果
}).start();
}
}
java.util.concurrent,简称 J.U.C.。是Java并发工具包,提供了在多线程编程中常用的工具类和框架,帮助开发者简化并发编程的复杂性,并提高程序的性能和可靠性。
java.util.concurrent.locks包下常用的类与接口是JDK1.5后新增的。lock的出现是为了弥补synchronized关键字解决不了的一些问题。
例如,当一个代码块被synchronized修饰了,一个线程获取了对应的锁,并执行该代码块时,其他线程只能一直等待,等待获取锁的线程释放锁。
如果这个线程因为某些原因被堵塞了,没有释放锁,那么其他线程只能一直等待下去,导致效率很低。
因此就需要有一种机制可以不让等待的线程一直无期限地等待下去,比如只等待一定的时间或者能够响应中断,通过Lock就可以办到。
java.util.concurrent包中的锁在locks包下:
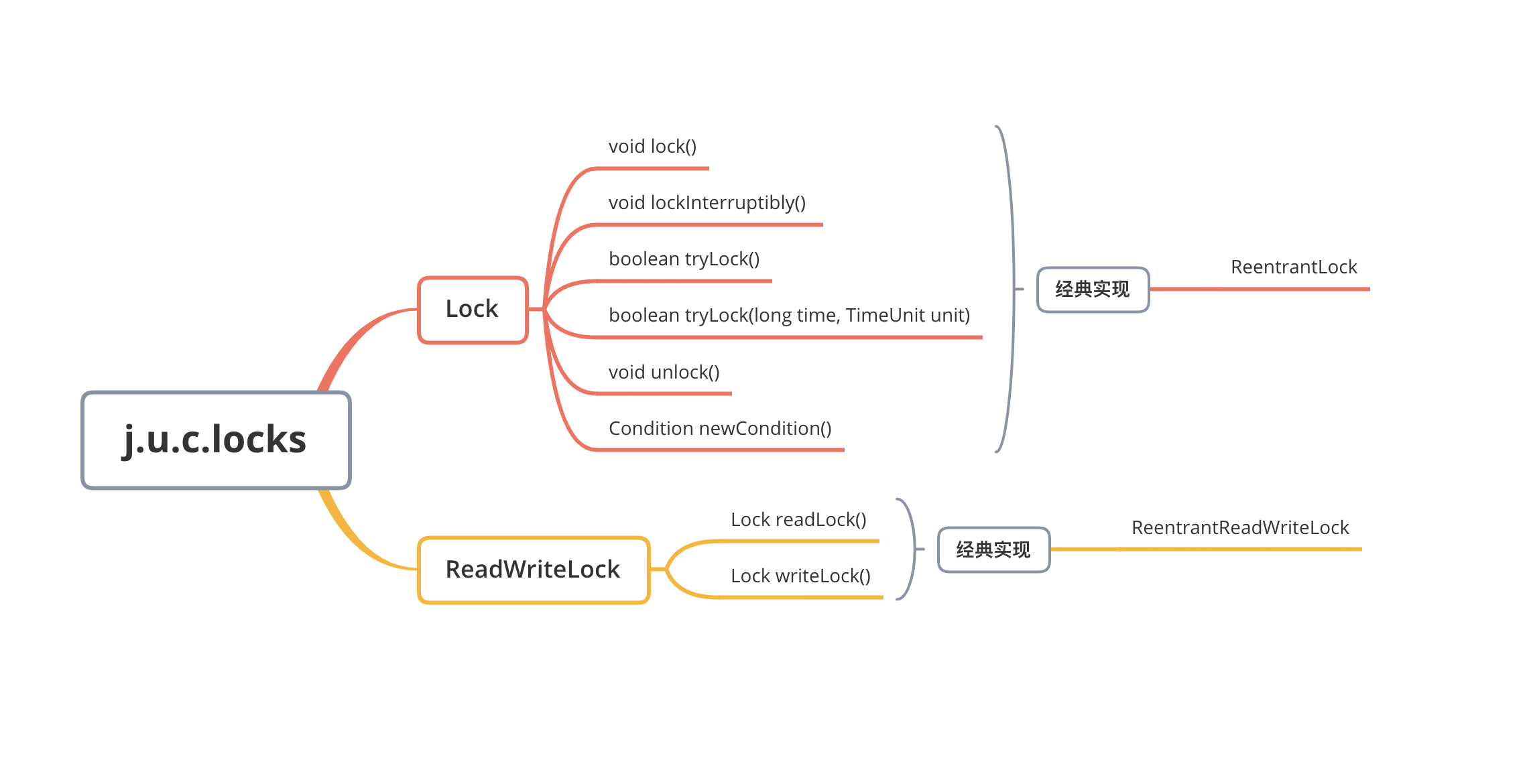
Lock和ReadWriteLock是两大锁的根接口,Lock代表实现类是ReentrantLock,ReadWriteLock的代表实现类是ReentrantReadWriteLock。
除了锁之外,java.util.concurrent包还提供了一些其他的工具类和框架,如Semaphore、CountDownLatch、CyclicBarrier等。
Lock接口在Java的java.util.concurrent.locks包中定义,用于实现更灵活的线程同步机制。与传统的 synchronized 关键字相比,Lock接口提供了更多的操作和更细粒度的控制。
在实际使用中,自然是能够替代synchronized关键字的。
Lock接口中的方法:
lock():lock()方法是平常使用得最多的一个方法,就是用来获取锁。如果锁已经被另一个线程持有,则当前线程将会被阻塞,直到锁被释放。
如果使用lock方法必须主动去释放锁,并且在发生异常时,不会自动释放锁。因此使用Lock必须在try-catch块中进行,并且将释放锁的操作放在finally块中进行,以保证锁一定被被释放,防止死锁的发生。
public void increment() {
lock.lock();
try {
counter++;
System.out.println(Thread.currentThread().getName() + ": " + counter);
} finally {
lock.unlock();
}
}
lockInterruptibly():获取锁,但与lock()方法不同,它允许线程在等待获取锁的过程中被中断。
例如,当两个线程同时通过lock.lockInterruptibly()想获取某个锁时,如果此时线程A获取到了锁,而线程B在等待,那么对线程B调用threadB.interrupt()能够中断线程B的等待过程。
当一个线程获取了锁之后,是不会被interrupt()方法中断的。因为interrupt()方法只能中断阻塞过程中的线程而不能中断正在运行过程中的线程。与 synchronized 相比,当一个线程处于等待某个锁的状态,是无法被中断的,只有一直等待下去。
public class LockInterruptiblyExample {
private final Lock lock = new ReentrantLock();
private int counter = 0;
public void increment() throws InterruptedException {
lock.lockInterruptibly();
try {
counter++;
System.out.println(Thread.currentThread().getName() + ": " + counter);
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
LockInterruptiblyExample example = new LockInterruptiblyExample();
Runnable task = () -> {
try {
example.increment();
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName() + " was interrupted.");
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
thread2.interrupt(); // Interrupt the second thread
}
}
trylock():该方法的作用是尝试获取锁,如果锁可用则返回true,不可用则返回false。
public class TryLockExample {
private final Lock lock = new ReentrantLock();
private int counter = 0;
public void increment() {
if (lock.tryLock()) {
try {
counter++;
System.out.println(Thread.currentThread().getName() + ": " + counter);
} finally {
lock.unlock();
}
} else {
System.out.println(Thread.currentThread().getName() + " could not acquire the lock.");
}
}
public static void main(String[] args) {
TryLockExample example = new TryLockExample();
Runnable task = example::increment;
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
}
}
newCondition:Lock接口提供了方法Condition newCondition();,返回的Condition类型也是一个接口,Condition提供了更细粒度的线程通信控制,用于实现复杂的线程间协作。
类似于Object类中的wait()、notify()和notifyAll()方法。
await():当前线程等待,直到被通知或被中断。signal():唤醒一个等待线程。如果所有线程都在等待,则任意选择一个线程唤醒。signalAll():唤醒所有等待线程。public class ConditionExample {
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
private int counter = 0;
public void increment() {
lock.lock();
try {
while (counter == 0) {
condition.await();
}
counter++;
System.out.println(Thread.currentThread().getName() + ": " + counter);
condition.signal();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
lock.unlock();
}
}
public void reset() {
lock.lock();
try {
counter = 0;
condition.signal();
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ConditionExample example = new ConditionExample();
Runnable incrementTask = example::increment;
Runnable resetTask = example::reset;
Thread thread1 = new Thread(incrementTask);
Thread thread2 = new Thread(resetTask);
thread1.start();
thread2.start();
}
}
ReadWriteLock接口提供了一种用于在某些情况下可以显著提升并发性能的锁定机制。
它允许多个读线程同时访问共享资源,但对写线程使用排他锁,这样读操作不会互相阻塞,而写操作会阻塞所有其他操作。
该接口有两个方法:
readLock():返回用于读取操作的锁。writeLock():返回用于写入操作的锁。ReadWriteLock管理一组锁,一个是只读的锁,一个是写锁。Java并发库中ReetrantReadWriteLock实现了ReadWriteLock接口并添加了可重入的特性。
对于ReetrantReadWriteLock其读锁是共享锁而写锁是独占锁,读锁的共享可保证并发读是非常高效的。需要注意的是,读写、写读、写写的过程是互斥的,只有读读不是互斥的。
public class ReadWriteLockExample {
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock readLock = readWriteLock.readLock();
private final Lock writeLock = readWriteLock.writeLock();
private int value = 0;
// 读操作
public int readValue() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + " Reading: " + value);
return value;
} finally {
readLock.unlock();
}
}
// 写操作
public void writeValue(int value) {
writeLock.lock();
try {
this.value = value;
System.out.println(Thread.currentThread().getName() + " Writing: " + value);
} finally {
writeLock.unlock();
}
}
public static void main(String[] args) {
ReadWriteLockExample example = new ReadWriteLockExample();
Runnable readTask = () -> {
for (int i = 0; i < 5; i++) {
example.readValue();
try {
Thread.sleep(100); // 模拟读取时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
};
Runnable writeTask = () -> {
for (int i = 0; i < 5; i++) {
example.writeValue(i);
try {
Thread.sleep(150); // 模拟写入时间
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
};
Thread thread1 = new Thread(readTask);
Thread thread2 = new Thread(readTask);
Thread thread3 = new Thread(writeTask);
thread1.start();
thread2.start();
thread3.start();
}
}
LockSupport是java.util.concurrent.locks包下的一个工具类。它提供了最基本的线程阻塞和解除阻塞的功能,通常用来构建更高级的同步机制。
其中有两个重要的方法,通过park()和unpark()方法来实现阻塞和唤醒线程的操作,可以理解为wait()和notify()的加强版。
park():阻塞当前线程,直到线程被其他线程中断或调用unpark()方法唤醒。unpark():唤醒指定线程。如果该线程尚未阻塞,则下一次调用park()方法时不会阻塞。传统等待唤醒机制是使用Object中的wait()方法让线程等待,使用Object中的notify()方法唤醒线程。
或者使用JUC包中Condition的await()方法让线程等待,使用signal()方法唤醒线程。
wait()和notify()/await()和signal()方法必须要在同步块或同步方法里且成对出现使用,如果没有在synchronized代码块使用则抛出java.lang.IllegalMonitorStateException。
必须先wait()/await()后notify()/signal(),如果先notify()后wait()会出现另一个线程一直处于等待状态。
LockSupport对比传统等待唤醒机制,能够解决传统等待唤醒问题。
LockSupport使用的是许可机制,而wait/notify使用的是监视器机制。每个线程最多只有一个许可,调用park()会消耗一个许可,如果有许可则会直接消耗这张许可然后退出,如果没有许可就堵塞等待许可可用。
调用unpark()则会增加一个许可,连续调用多次unpark()和调用一次一样,只会增加一个许可。而且LockSupport的park()和unpark()是可中断的,且无需在同步块中使用。
public class LockSupportProducerConsumer {
private static Object resource = null;
public static void main(String[] args) {
Thread consumer = new Thread(() -> {
System.out.println("Consumer waiting for resource");
while (resource == null) {
LockSupport.park();
}
System.out.println("Consumer consumed resource");
});
Thread producer = new Thread(() -> {
try {
Thread.sleep(2000); // Simulate some work with sleep
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
resource = new Object();
System.out.println("Producer produced resource");
LockSupport.unpark(consumer);
});
consumer.start();
producer.start();
}
}
LockSupport类使用了一种名为Permit的概念来做到阻塞和唤醒线程的功能,每个线程都有一个Permit,Permit只有两个值1和0,默认是0。
官网解释LockSupport是用来创建锁和同步其他类的基本线程的阻塞原语。LockSupport最终调用的Unsafe中的native方法。以unpark、park为例:
public static void unpark(Thread thread) {
if (thread != null)
UNSAFE.unpark(thread);
}
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(false, 0L);
setBlocker(t, null);
}
AQS是指java.util.concurrent.locks包下的一个抽象类AbstractQueuedSynchronizer译为,抽象的队列同步器。
同步器是在多线程编程中用于管理线程间协作和同步的机制。同步器通常用于协调线程的执行顺序、控制共享资源的访问以及管理线程的状态。常见的同步器包括:CountDownLatch、CyclicBarrier、Semaphore等。
在JUC包下,能够看到有许多类都继承了AQS,如ReentrantLock、CountDownLatch、ReentrantReadWriteLock、Semaphore。
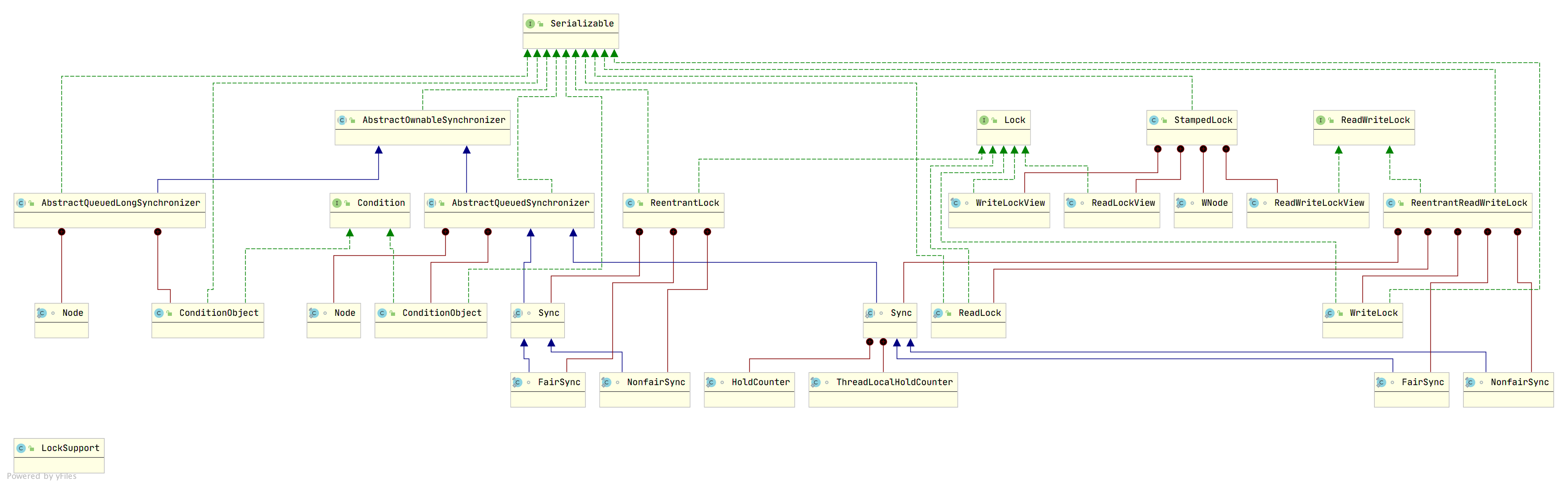
AQS是用来构建锁或其它同步器组件的重要基础框架,以及是整个JUC体系的基石,它用于实现依赖先进先出队列的阻塞锁和相关的同步器。 AQS提供了一个框架,用于创建在等待队列中具有独占或共享模式的同步器。
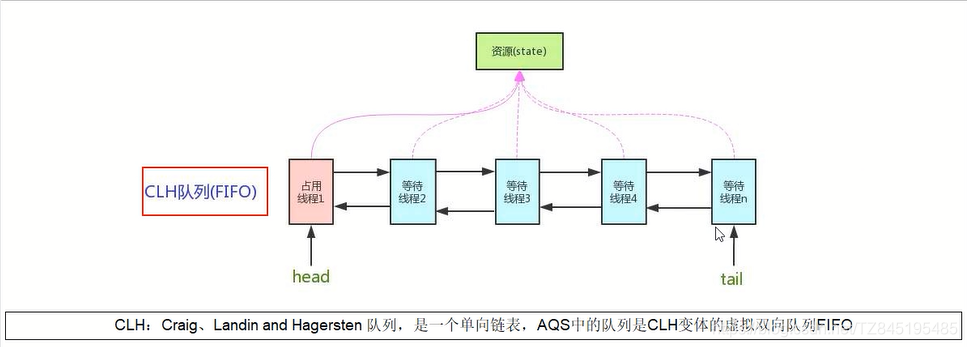
AQS可以理解为一个框架,因为它定义了一些JUC包下常用"锁"的标准。
AQS简单来说,包含一个status和一个队列。status保存线程持有锁的状态,用于判断该线程获没获取到锁,没获取到锁就去队列中排队。
AQS中的队列,是指CLH队列(Craig, Landin, and Hagerste[三个人名组成])锁队列的变体,是一个双向队列。
队列中的元素即Node结点,每个Node中包含:头结点、尾结点、等待状态、存放的线程等。Node遵循从尾部入队,从头部出队的规则,即先进先出原则。
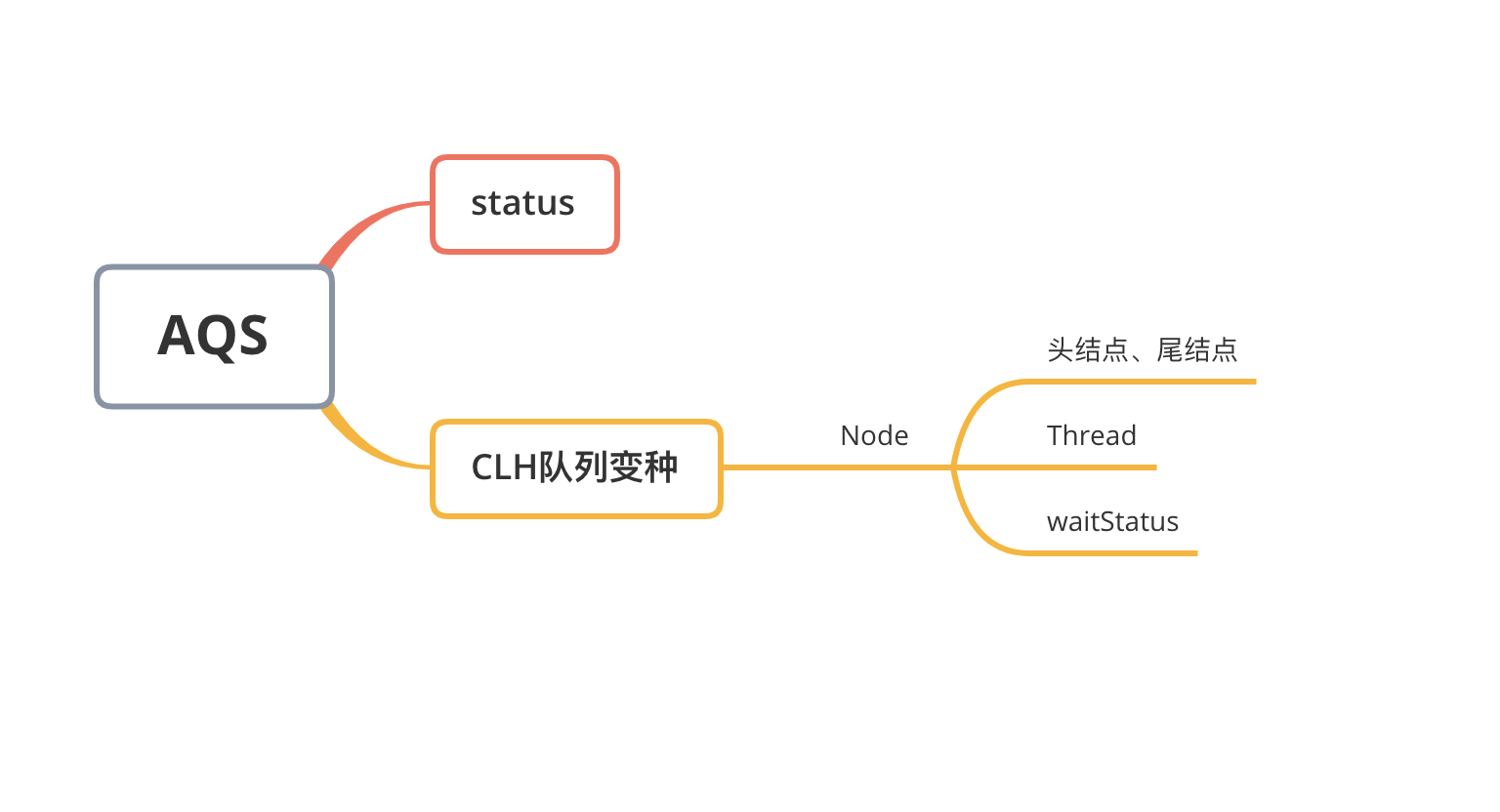
在多线程并发环境下,使用lock加锁,当处在加锁与解锁之间的代码,只能有一个线程来执行。这时候其他线程不能够获取锁,如果不处理线程就会造成了堵塞。
在AQS框架中,会将暂时获取不到锁的线程加入到队列里,这个队列就是AQS的抽象表现。它会将这些线程封装成队列的结点,通过CAS、自旋以及LockSupport.park()的方式,维护state变量的状态,使并发达到同步的效果。
ReentrantLock译为可重入锁,是一种锁的实现类,它提供了比synchronized关键字更广泛的锁定操作选项,提供了公平锁和非公平锁两种模式。
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
private int counter = 0;
public void increment() {
lock.lock();
try {
counter++;
System.out.println(Thread.currentThread().getName() + " incremented counter to " + counter);
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ReentrantLockExample example = new ReentrantLockExample();
Runnable task = () -> {
for (int i = 0; i < 5; i++) {
example.increment();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
}
}
Java提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是JVM实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
| 比较 | synchronized | ReentrantLock |
|---|---|---|
| 锁的实现 | JVM实现 | JDK实现 |
| 性能 | synchronized 与 ReentrantLock 大致相同 | synchronized 与 ReentrantLock 大致相同 |
| 等待可中断 | 不可中断 | 可中断 |
| 公平锁 | 非公平锁 | 默认非公平锁,也可以是公平锁 |
| 锁绑定多个条件 | 不能绑定 | 可以同时绑定多个Condition对象 |
| 可重入 | 可重入锁 | 可重入锁 |
| 释放锁 | 自动释放锁 | 调用 unlock() 释放锁 |
| 等待唤醒 | 搭配wait()、notify或notifyAll()使用 | 搭配await()/singal()使用 |
synchronized与ReentrantLock最直观的区别就是,在使用ReentrantLock的时候需要调用unlock方法释放锁,所以为了保证一定释放,通常都是和 try-finally 配合使用的。
在实际开发中除非需要使用ReentrantLock的高级功能,否则优先使用synchronized。
这是因为synchronized是JVM实现的一种锁机制,JVM原生地支持它,而ReentrantLock不是所有的JDK版本都支持。并且使用synchronized不用担心没有释放锁而导致死锁问题,因为JVM会确保锁的释放。
ReentrantLock原理用到了AQS,而AQS包括一个线程队列和一个state变量,state,它的值有3种状态:没占用是0,占用了是1,大于1是可重入锁。
所以ReentrantLock加锁过程,可以简单理解为state变量的变化。
在多线程并发环境下,某个线程持有锁,将state由0设置为1,如果有其他线程再次进入,线程则会经过一系列判断,然后构建Node结点,最终形成双向链表结构。
最后执行LockSupport.park()方法,将等待的线程挂起,如果当前持有锁的线程释放了锁,则将state变量设置为0,调用LockSpoort.unpark()方法指定唤醒等待队列中的某个线程。
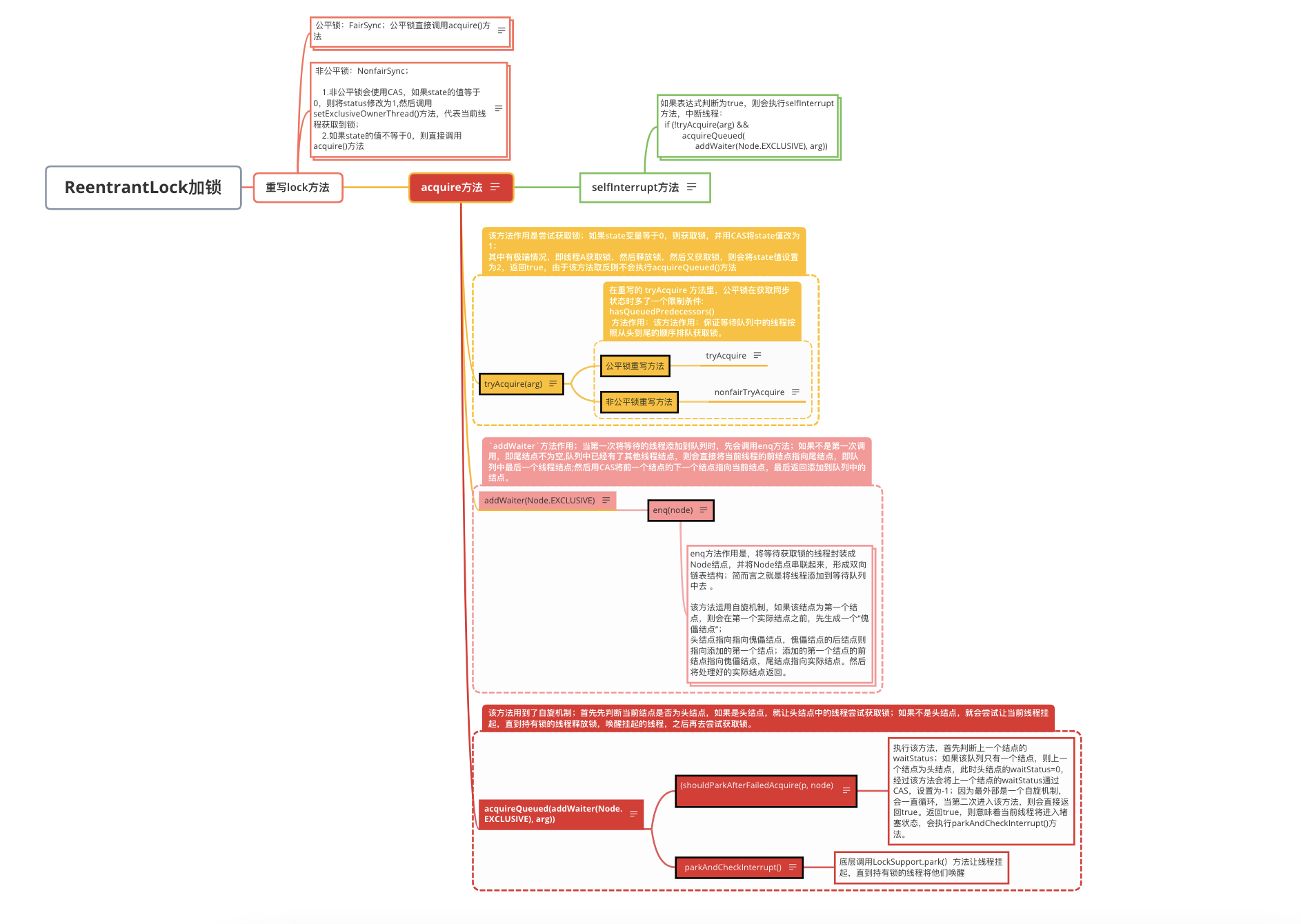
ReentrantLock加锁有两种形式,默认是非公平锁,但可以通过构造方法来指定为公平锁。
public static void main(String[] args) {
ReentrantLock reentrantLock = new ReentrantLock(true);
}
//⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
/**
* Creates an instance of {@code ReentrantLock} with the
* given fairness policy.
*
* @param fair {@code true} if this lock should use a fair ordering policy
*/
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
无论是公平锁还是非公平锁,由于用到了AQS框架,所以底层实现的逻辑大致是差不多的,ReentrantLock加锁核心方法调用栈:
lock()
--> acquire()
--> tryAcquire()
--> addWaiter()
--> acquireQueued()
--> selfInterrupt()
公平锁还是非公平锁虽然大致逻辑差不多,但是区别总是有的,总的来说非公平锁比非公平锁在代码里面多了几行判断。
// ===========重写 lock 方法对比===========
// 公平锁
final void lock() {
acquire(1);
}
// 非公平锁
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
// ===========重写 tryAcquire 方法对比===========
// 公平锁
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
// 非公平锁
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
在重写的tryAcquire方法里,公平锁在获取同步状态时多了一个限制条件即hasQueuedPredecessors()方法。该方法作用是保证等待队列中的线程按照从头到尾的顺序排队获取锁。
举个例子,目前队列中有两个线程A、B,线程A,在线程B的前面。在当前线程释放锁的时候,线程B获取到了锁,该方法会判断当前头结点的下一个结点中存放的线程跟当前线程是否相同。
在这个例子中头结点的下一个结点存放的线程是傀儡结点线程为null,而当前线程是线程B,所以返回true,回到上一个方法true取反就是false所以获取锁失败。
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
在执行完tryAcquire方法之后就会执行addWaiter方法。
addWaiter方法作用为,当第一次将等待的线程添加到队列时,先会调用enq方法。
如果不是第一次调用,即尾结点不为空,队列中已经有了其他线程结点,则会直接将当前线程的前结点指向尾结点,即队列中最后一个线程结点。
然后用CAS将前一个结点的下一个结点指向当前结点,形成链表结构,最后返回添加到队列中的结点。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
enq方法作用是将等待获取锁的线程封装成Node结点,并将Node结点串联起来,形成双向链表结构,简而言之就是将线程添加到等待队列中去。
该方法运用自旋机制,如果添加的结点为第一个结点,则会在第一个实际结点之前,生成一个“傀儡结点”。添加的第一个结点的前结点指向傀儡结点,尾结点指向实际结点。傀儡结点的后结点则指向添加的第一个结点。
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
之后执行acquireQueued方法,该方法用到了自旋机制。首先判断当前结点是否为头结点,如果是头结点,就让头结点中的线程尝试获取锁。
如果不是头结点,执行shouldParkAfterFailedAcquire方法尝试让当前线程挂起,直到持有锁的线程释放锁,唤醒等待的线程之后再去尝试获取锁。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
shouldParkAfterFailedAcquire方法,该方法首先判断上一个结点的waitStatus。
如果该队列只有一个结点,则上一个结点为头结点,此时头结点的waitStatus=0,经过该方法会将上一个结点的waitStatus通过CAS,设置为-1。
因为最外部是一个自旋机制,会一直循环,所以当第二次进入该方法,则会直接返回true。返回true意味着当前线程将进入堵塞状态,会执行parkAndCheckInterrupt()方法。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
return true;
if (ws > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
parkAndCheckInterrupt方法,底层是调用LockSupport.park()方法让线程挂起,直到持有锁的线程将它们唤醒。
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
ReentrantLock其加锁核心方法为acquire方法。最终执行完毕,下面的if表达式返回true,则执行selfInterrupt方法中断线程。
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
ReentrantLock在采用非公平锁构造时,首先检查锁状态,如果锁可用,直接通过CAS设置成持有状态,且把当前线程设置为锁的拥有者。
如果当前锁已经被持有,那么接下来进行可重入检查,如果可重入,需要为锁状态加上请求数。如果不属于上面两种情况,那么说明锁是被其他线程持有,当前线程应该放入等待队列。
在放入等待队列的过程中,首先要检查队列是否为空队列,如果为空队列,需要创建虚拟的头节点,然后把对当前线程封装的节点加入到队列尾部。
由于设置尾部节点采用了CAS,为了保证尾节点能够设置成功,ReentrantLock采用了无限循环的方式,直到设置成功为止。
在完成放入等待队列任务后,则需要维护节点的状态,以及及时清除处于Cancel状态的节点,来帮助垃圾收集器及时回收。
如果当前节点之前的节点的等待状态小于1,说明当前节点之前的线程处于等待状态,那么当前节点的线程也应处于等待状态。通过LockSupport类实现等待挂起的功能。
当等待的线程被唤起后,检查中断状态,如果处于中断状态,那么需要中断当前线程。
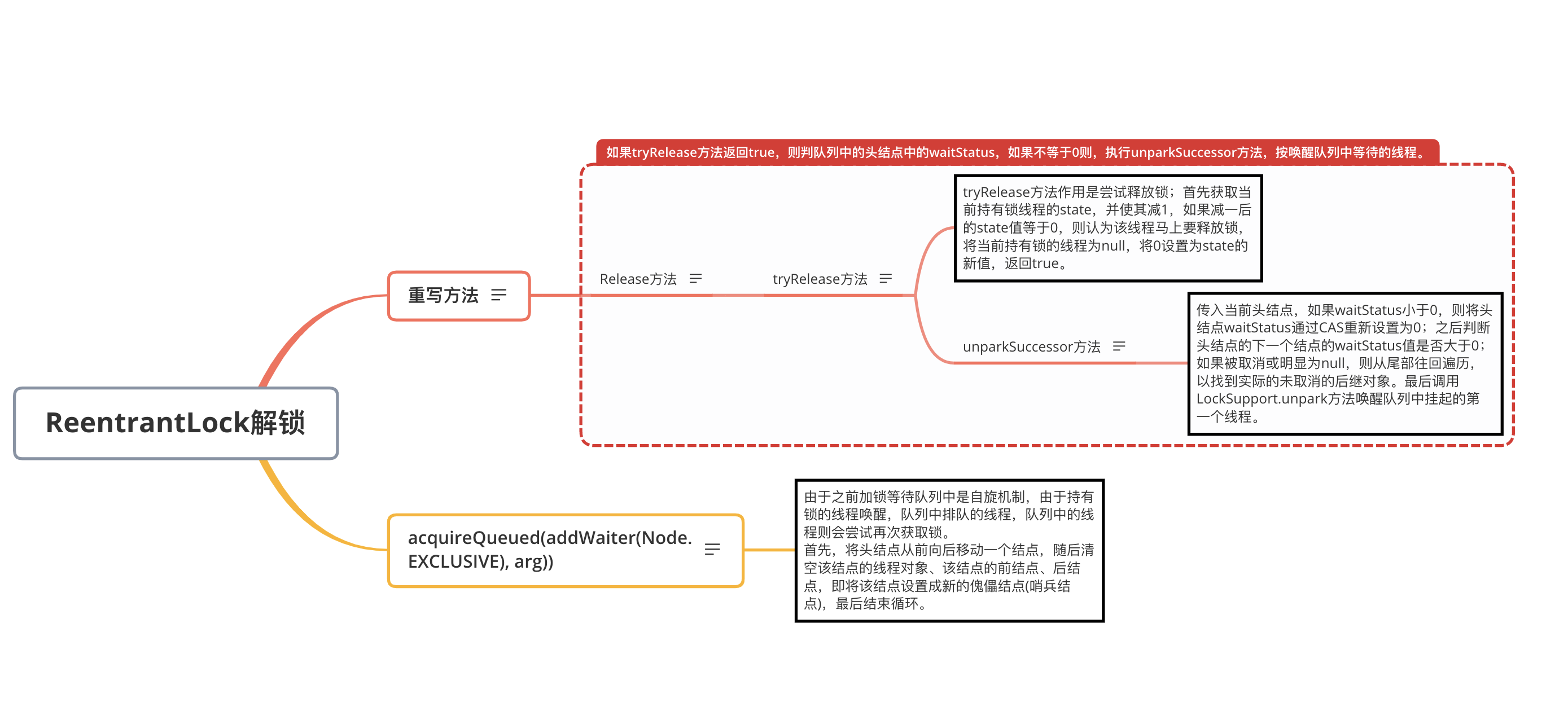
ReentrantLock释放锁调用栈:
unlock()
--> release()
--> tryRelease()
--> unparkSuccessor()
在release方法中如果tryRelease方法返回true,则判断队列头结点中的waitStatus,如果不等于0则执行unparkSuccessor方法,按顺序唤醒队列中等待的线程。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
tryRelease方法作用是尝试释放锁,首先获取当前持有锁线程的state变量并使其减1。
如果减1后的state值等于0,则认为该线程马上要释放锁,将当前持有锁的线程设置为null,将0设置为state的新值并返回true。
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
unparkSuccessor方法用于唤醒等待队列中的后继节点。首先判断当前节点的等待状态如果小于0,将其设置为0。
然后从尾部开始向前查找,直到找到一个有效的后继节点,如果找到一个有效的后继节点,唤醒其线程。
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
count down latch直译为倒计时门闩,也可以叫做闭锁。
门闩,汉语词汇。拼音:mén shuān 释义:指门关上后,插在门内使门推不开的滑动插销。
CountDownLatchJDK文档注释:
A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.
文档大意:一种同步辅助工具,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。
CountDownLatch是Java中的一个同步工具类,用于使一个或多个线程等待其他线程完成一组操作。CountDownLatch通过一个计数器实现,该计数器的初始值由构造方法指定,底层还是AQS。
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
每调用一次countDown()方法,计数器减一,当计数器到达零时,所有因调用await()方法而等待的线程都将被唤醒。
举个例子,晚上教室关门,要等同学都离开之后,再关门:
public class MainTest {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(7);
for (int i = 0; i < 7; i++){
new Thread(() -> {
System.out.println("同学"+Thread.currentThread().getName() + "\t 离开");
countDownLatch.countDown();
},String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println("关门...");
}
}
Cyclic Barrier直译为循环屏障,是Java中关于线程的计数器,也可以叫它栅栏。
CyclicBarrierJDK文档注释:
A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point. CyclicBarriers are useful in programs involving a fixed sized party of threads that must occasionally wait for each other. The barrier is called cyclic because it can be re-used after the waiting threads are released.
文档大意:一种同步辅助工具,允许一组线程相互等待到达一个共同的障碍点。cyclicbarrier在包含固定大小的线程组的程序中非常有用,这些线程必须偶尔相互等待。
这个屏障被称为cyclic,因为它可以在等待的线程被释放后被重用。
它与CountDownLatch的作用是相反的,CountDownLatch是定义一个次数,然后减直到减到0,再去执行一些任务。
而CyclicBarrier是定义一个上限次数,从零开始加,直到加到定义的上限次数,再去执行一些任务。
CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以使用reset()方法重置,可以使用多次,所以CyclicBarrier能够处理更为复杂的场景。
例如,凑齐七颗龙珠召唤神龙:
public class MainTest {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(7,() -> {
System.out.println("凑齐七颗龙珠,召唤神龙!");
});
for (int i = 1; i <= 7;i++){
new Thread(() -> {
System.out.println("拿到"+Thread.currentThread().getName() + "星龙珠");
try {
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
},String.valueOf(i)).start();
}
}
}
CyclicBarrier要做的事情是,让一组线程达到一个屏障时被阻塞,直到最后一个线程达到屏障时,所有被屏障拦截的线程才会继续干活,线程进入屏障通过CyclicBarrier.await()方法。

CyclicBarrier是基于ReentrantLock实现的,其底层也是基于AQS。
CyclicBarrier通过一个内部的计数器和一个锁来实现线程间的协调。当所有线程都调用await方法时,计数器递减,当计数器为零时,所有等待的线程将被唤醒,并重置计数器,以便下一次使用。
Semaphore译为信号量,有时被称为信号灯。可以用来控制同时访问特定资源的线程数量,通过协调各个线程,保证合理的使用资源。
信号量主要用于两个目的,一个是用于多个共享资源的互斥使用,另一个用于并发线程数量的控制。
SemaphoreJDK文档注释:
A counting semaphore. Conceptually, a semaphore maintains a set of permits. Each {@link #acquire} blocks if necessary until a permit is available, and then takes it. Each {@link #release} adds a permit, potentially releasing a blocking acquirer.
文档大意:Semaphore是一个计数信号量。从概念上讲,信号量维护一组许可。如果需要,每个acquire方法调用会阻塞,直到有一个许可可用,然后获取许可。
每个release方法调用会添加一个许可,可能会释放一个阻塞的线程。实际上,Semaphore并没有维护实际的许可对象,只是维护一个可用许可的计数,并根据计数执行相应的操作。
举个例子,九辆车抢三个车位,车位满了之后只有等里面的车离开停车场外面的车才可以进入。
public class MainTest {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
for (int i = 1; i <= 9; i++) {
new Thread(() -> {
try {
semaphore.acquire();
System.out.println("第" + Thread.currentThread().getName() + "辆车,抢到车位");
Thread.sleep(2000);
System.out.println("停车结束.");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();
}
}, String.valueOf(i)).start();
}
}
}
Semaphore通过一个计数器和一个队列来管理许可和等待线程。它依赖于AQS来实现同步逻辑。
Semaphore是用来保护一个或者多个共享资源的访问,Semaphore内部维护了一个计数器,其值为可以访问的共享资源的个数。
一个线程要访问共享资源,先获得信号量,如果信号量的计数器值大于1,意味着有共享资源可以访问,则使其计数器值减去1,再访问共享资源。
如果计数器值为0,线程进入休眠。当某个线程使用完共享资源后,释放信号量,并将信号量内部的计数器加1,之前进入休眠的线程将被唤醒并再次试图获得信号量。
Semaphore的核心方法为:
acquire():获取一个许可,如果没有可用的许可,当前线程将被阻塞,直到有许可可用。
当调用semaphore.acquire()方法时,当前线程会尝试去同步队列获取一个令牌,获取令牌的过程也就是使用原子操作去修改同步队列的state,获取一个令牌则修改为state=state-1。
当计算出来的state<0,则代表令牌数量不足,此时会创建一个Node节点加入阻塞队列,挂起当前线程。当计算出来的state>=0,则代表获取令牌成功。release():释放一个许可,将其返回到Semaphore。
当调用semaphore.release()方法时,线程会尝试释放一个令牌,释放令牌的过程也就是把同步队列的state修改为state=state+1的过程。
释放令牌成功之后,同时会唤醒同步队列中的一个线程。被唤醒的节点会重新尝试去修改state=state-1的操作,如果state>=0则获取令牌成功,否则重新进入阻塞队列,挂起线程。ThreadLocal文档注释:
This class provides thread-local variables.
These variables differ from their normal counterparts in that each thread that accesses one (via its {@code get} or {@code set} method) has its own,
independently initialized copy of the variable.
文档大意:这个类提供线程局部变量。这些变量与普通变量的不同之处在于,每个访问它们的线程(通过其get方法或set方法)都有自己的独立初始化的变量副本。
如文档注释所说,ThraedLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
每个访问ThreadLocal变量的线程都有自己的隔离副本,这样防止了线程之间的干扰,消除了同步的需要。
从线程的角度看,目标变量就象是线程的本地变量,这也是类名中“Local”所要表达的意思。说白了ThreadLocal就是存放线程的局部变量的。
ThreadLocal是修饰变量的,重点是在控制变量的作用域,初衷不是为了解决线程并发和线程冲突的,而是为了让变量的种类变的更多更丰富,方便使用。很多开发语言在语言级别都提供这种作用域的变量类型。
其实要保证线程安全,并不一定就是要进行同步,两者没有因果关系。同步只是保证共享数据竞争时的手段。如果一个方法本来就不涉及共享数据,那它自然就无需任何同步措施去保证正确性。
线程安全,并不一定就是要进行同步,ThreadLocal目的是线程安全,但不是同步手段。
ThreadLocal和线程同步机制都可以解决多线程中共享变量的访问冲突问题。
在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。使用同步机制要求程序谨慎地分析什么时候对变量进行读写,什么时候需要锁定某个对象,什么时候释放对象锁等繁杂的问题,程序设计和编写难度相对较大。
而ThreadLocal 则从另一个角度来解决多线程的并发访问。ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。
ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
虽然ThreadLocal能够保证多线程访问数据安全,但是由于在每个线程中都创建了副本,所以要考虑它对资源的消耗,比如内存的占用会比不使用ThreadLocal要大。
对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
在JDK5.0中,ThreadLocal已经支持泛型,该类的类名已经变为ThreadLocal<T>。API方法也相应进行了调整,新版本的API方法分别是void set(T value)、T get()。
ThreadLocal中主要有三个方法:
set():设置当前线程的线程局部变量的值。get():该方法返回当前线程所对应的线程局部变量。remove():删除当前线程的线程局部变量,目的是为了减少内存的占用。public class ThreadLocalExample {
// 创建一个 ThreadLocal 变量,用于存储每个线程独立的值
private static final ThreadLocal<String> threadLocalValue = new ThreadLocal<>();
public static void main(String[] args) {
Runnable task1 = () -> {
// 设置线程局部变量的值
threadLocalValue.set("Thread-1's Value");
// 获取并打印线程局部变量的值
System.out.println(Thread.currentThread().getName() + ": " + threadLocalValue.get());
// 删除线程局部变量的值
threadLocalValue.remove();
System.out.println(Thread.currentThread().getName() + " after remove: " + threadLocalValue.get());
};
Runnable task2 = () -> {
// 设置线程局部变量的值
threadLocalValue.set("Thread-2's Value");
// 获取并打印线程局部变量的值
System.out.println(Thread.currentThread().getName() + ": " + threadLocalValue.get());
// 删除线程局部变量的值
threadLocalValue.remove();
System.out.println(Thread.currentThread().getName() + " after remove: " + threadLocalValue.get());
};
Thread thread1 = new Thread(task1);
Thread thread2 = new Thread(task2);
thread1.start();
thread2.start();
}
}
除此之外,ThreadLocal提供了一个withInitial()方法统一初始化所有线程的ThreadLocal的值。
public class ThreadLocalWithInitialExample {
// 使用 withInitial 方法提供初始值
private static final ThreadLocal<SimpleDateFormat> dateFormat = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd"));
public static void main(String[] args) {
Runnable task1 = () -> {
// 获取并打印线程局部变量的值
SimpleDateFormat df = dateFormat.get();
String formattedDate = df.format(new Date());
System.out.println(Thread.currentThread().getName() + ": " + formattedDate);
// 删除线程局部变量的值
dateFormat.remove();
};
Runnable task2 = () -> {
// 获取并打印线程局部变量的值
SimpleDateFormat df = dateFormat.get();
String formattedDate = df.format(new Date());
System.out.println(Thread.currentThread().getName() + ": " + formattedDate);
// 删除线程局部变量的值
dateFormat.remove();
};
Thread thread1 = new Thread(task1);
Thread thread2 = new Thread(task2);
thread1.start();
thread2.start();
}
}
ThreadLocal是一种强大的工具,适用于需要线程隔离的场景,如用户会话、数据库连接和格式化对象等。
使用ThreadLocal可以有效地管理线程本地的数据,避免多线程环境下的竞争和数据一致性问题。
但是由于ThreadLocal的生命周期与线程相关,如果在线程池中使用ThreadLocal,需要注意及时调用remove()方法清理线程局部变量,来防止内存泄漏。
ThreadLocal类本身并不存储线程本地变量的值,而是通过ThreadLocalMap来实现。
每个线程内部都有一个ThreadLocalMap实例,ThreadLocal变量作为ThreadLocalMap的键,存储的值是该线程对应的变量值。
set方法首先获取当前线程 Thread 对象,然后获取该线程的 ThreadLocalMap 实例。如果存在,则将值存储在 ThreadLocalMap 中;否则,创建一个新的 ThreadLocalMap。
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 每个线程 都有一个自己的ThreadLocalMap
// ThreadLocalMap 里就保存着所有的ThreadLocal变量
ThreadLocalMap map = getMap(t);
if (map != null)
// 向map里添加值
map.set(this, value);
else
// map为null,创建一个 ThreadLocalMap
createMap(t, value);
}
// 全局定义的localMap
ThreadLocal.ThreadLocalMap threadLocals = null;
// 获取当前线程所持有的localMap
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// 创建,初始化 localMap
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
get方法同样先获取当前线程 Thread 对象,然后获取该线程的 ThreadLocalMap 实例。再通过 ThreadLocal 对象作为键从 ThreadLocalMap 中获取值。如果键不存在,则调用 setInitialValue 方法初始化变量。
public T get() {
// 获取当前线程
Thread t = Thread.currentThread();
// 每个线程 都有一个自己的ThreadLocalMap,
// ThreadLocalMap里就保存着所有的ThreadLocal变量
ThreadLocalMap map = getMap(t);
if (map != null) {
//ThreadLocalMap的key就是当前ThreadLocal对象实例,
//多个ThreadLocal变量都是放在这个map中的
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
//从map里取出来的值就是我们需要的这个ThreadLocal变量
T result = (T)e.value;
return result;
}
}
// 如果map没有初始化,那么在这里初始化一下
return setInitialValue();
}
// 全局定义的localMap
ThreadLocal.ThreadLocalMap threadLocals = null;
// 获取当前线程所持有的localMap
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
setInitialValue 方法通过 initialValue 方法获取初始值,并存储在 ThreadLocalMap 中。如果 initialValue 方法未被重写,默认返回 null。
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
protected T initialValue() {
return null;
}
ThreadLocalMap是一个自定义的哈希表,其中每个元素是一个Entry对象。
ThreadLocalMap是一个比较特殊的Map,它的每个Entry的key都是一个弱引用。
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
//key就是一个弱引用
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
这样设计的好处是,如果这个变量不再被其他对象使用时,可以自动回收这个ThreadLocal对象,避免可能的内存泄露。
虽然ThreadLocalMap中的key是弱引用,当不存在外部强引用的时候,就会自动被回收。但是Entry中的value依然是强引用,value的引用链条如下:
Thread --> ThreadLocalMap --> Entry --> value
只有当Thread被回收时,这个value才有被回收的机会,否则只要线程不退出,value总是会存在一个强引用。
但是要求每个Thread都会退出,是一个极其苛刻的要求,对于线程池来说,大部分线程会一直存在在系统的整个生命周期内,那样的话就会造成value对象出现泄漏的可能。
如果get()方法总是访问固定几个一直存在的ThreadLocal,那么清理动作就不会执行,如果你没有机会调用set()和remove(),那么这个内存泄漏依然会发生。
所以当你不需要这个ThreadLocal变量时,主动调用remove(),这样是能够避免内存泄漏的。可以将ThreadLocal的使用和清理放在try-finally块中,确保remove()方法总是会被调用。
ThreadLocal<MyClass> threadLocal = new ThreadLocal<>();
try {
threadLocal.set(new MyClass());
// 使用线程局部变量
} finally {
threadLocal.remove();
}
除此之外,应尽量避免将ThreadLocal对象声明为静态变量,特别是在应用服务器或类似环境中,因为它们的生命周期通常较长,会增加内存泄漏的风险。
在多线程环境中,数据的一致性和线程的安全性是至关重要的。传统的集合类,如ArrayList、HashMap和HashSet,在并发访问时并不安全,可能会导致数据不一致和其他并发问题。
为了在并发编程中高效且安全地操作数据,Java提供了一系列线程安全的集合类来替代这些传统集合。
| 线程不安全 | 线程安全替代 |
|---|---|
| ArrayList | CopyOnWriteArrayList |
| HashSet | CopyOnWriteArraySet |
| HashMap | HashTable、ConcurrentHashMap |
CopyOnWriteArrayList是Java中的一种线程安全的List实现,适用于读操作远多于写操作的场景,该集合在线程不安全的情况下可替代ArrayList。
public class MainTest {
public static void main(String[] args) {
CopyOnWriteArrayList<String> arrayList = new CopyOnWriteArrayList<>();
for(int i=0; i< 10; i++) {
new Thread(() -> {
arrayList.add(UUID.randomUUID().toString());
System.out.println(arrayList);
},String.valueOf(i)).start();
}
}
}
CopyWriteArrayList字面意思就是在写的时候复制,思想就是读写分离的思想。它的基本原理是每次修改操作都会创建该列表的一个新副本,因此读操作不需要加锁,可以并发执行。
以下是CopyOnWriteArrayList的add()方法源码:
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true}
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
CopyWriteArrayList之所以线程安全的原因是在源码里面使用ReentrantLock保证了某个线程在写的时候不会被打断。
可以看到源码开始先是复制了一份数组,同一时刻只有一个线程写,其余的线程会读。在复制的数组上边进行写操作,写好以后在返回true。
这样就把读写进行了分离,写好以后因为array加了volatile修饰,所以该数组是对于其他的线程是可见的,就会读取到最新的值。
由于每次写操作都会创建一个数组的新副本,所以写操作的开销较大。但是读取操作非常高效且不需要加锁,因此适用于读操作远多于写操作的场景,例如缓存、白名单等。
不适合写操作频繁的场景,在这种情况下,ConcurrentLinkedQueue或ConcurrentHashMap等其他线程安全集合可能更合适。
CopyOnWriteArraySet是Java中一种线程安全的Set实现,内部使用了CopyOnWriteArrayList来存储元素。
private final CopyOnWriteArrayList<E> al;
/**
* Creates an empty set.
*/
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
这种集合在读操作远多于写操作的场景中非常有用,因为它通过每次修改创建集合的副本来实现线程安全。
因为底层用CopyOnWriteArrayList存储,所以写操作开销大,每次修改都会创建数组副本,适用场景有限。不适用于写操作频繁的场景,否则会导致高昂的内存和时间开销。
与CopyOnWriteArrayList不同的是,CopyOnWriteArraySet不允许包含重复元素。如果尝试添加一个已经存在的元素,集合将保持不变,所以该集合在线程不安全的情况下可替代HashSet。
CopyOnWriteArraySet适用于需要唯一性且不关心元素顺序的场景,例如维护一组独特的订阅者或监听器。
public class CopyOnWriteArraySetExample {
public static void main(String[] args) {
// 创建一个 CopyOnWriteArraySet
Set<String> cowSet = new CopyOnWriteArraySet<>();
// 添加元素
cowSet.add("Apple");
cowSet.add("Banana");
cowSet.add("Apple"); // 不允许重复元素
// 读取元素
System.out.println("Set: " + cowSet);
// 迭代元素
for (String fruit : cowSet) {
System.out.println(fruit);
}
// 添加新元素
cowSet.add("Grapes");
System.out.println("After adding Grapes: " + cowSet);
// 删除元素
cowSet.remove("Banana");
System.out.println("After removing Banana: " + cowSet);
}
}
HashTable的出现是为了解决HashMap线程不安全的问题,但因为性能的原因,在多线程环境下很少使用,一般都会使用ConcurrentHashMap。HashTable性能低的原因,就是直接加了synchronized修饰。
HashMap中的方法大多没有同步,这意味着如果一个线程在遍历HashMap的同时,另一个线程修改了HashMap,例如添加或删除元素,可能会导致ConcurrentModificationException。
当遍历HashTable中的元素时,此时另一个线程来修改数据,这个时候加锁是没问题的。但是在没有另一个线程该数据的时候,HashTable还是加锁,这时性能就不太好了。可理解为HashTable性能不好的原因就是锁的粒度太粗了。
Hashtable的线程安全通过在方法级别使用synchronized关键字来实现,这确保了每次只有一个线程能够执行任何给定的方法。这种方法级别的锁定提供了基本的线程安全,但在高并发环境下会导致性能瓶颈。
public class HashtableExample {
public static void main(String[] args) {
// 创建一个 Hashtable
Hashtable<Integer, String> hashtable = new Hashtable<>();
// 添加元素
hashtable.put(1, "One");
hashtable.put(2, "Two");
hashtable.put(3, "Three");
// 读取元素
System.out.println("Value for key 1: " + hashtable.get(1));
System.out.println("Value for key 2: " + hashtable.get(2));
// 删除元素
hashtable.remove(2);
// 迭代元素
for (Integer key : hashtable.keySet()) {
System.out.println("Key: " + key + ", Value: " + hashtable.get(key));
}
}
}
ConcurrentHashMap是Java中的一种线程安全的哈希表实现,用来替代传统的HashMap,来解决在多线程环境中并发修改带来的问题。
与Hashtable不同,ConcurrentHashMap不对整个表进行全局加锁。相反它只对具体操作涉及的部分进行加锁,减少了线程之间的竞争。
因为HashMap在JDK1.7与JDK1.8做了调整,所以ConcurrentHashMap在JDK1.7与JDK1.8实现也有所不同。
JDK1.7ConcurrentHashMap采用segment的分段锁机制实现线程安全,其中segment类继承自ReentrantLock。用ReentrantLock、CAS来保证线程安全。
每个分段相当于一个独立的哈希表,并且分别加锁。
需要注意的是JDK1.7中的ConcurrentHashMap,分段数量是固定。在创建ConcurrentHashMap实例时,必须指定初始的分段数量。
这个初始的分段数量在实例创建后是不可动态修改的,也就是说一旦创建了ConcurrentHashMap,其分段数量就固定不变了。数组的长度就是concurrencyLevel指定的分段数量。
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel){}
相比之下,JDK1.8中的ConcurrentHashMap改进了这一点,不再使用固定的分段数量,而是根据当前的容量动态调整分段的数量,从而更好地适应不同的并发场景,提升了并发性能和灵活性。
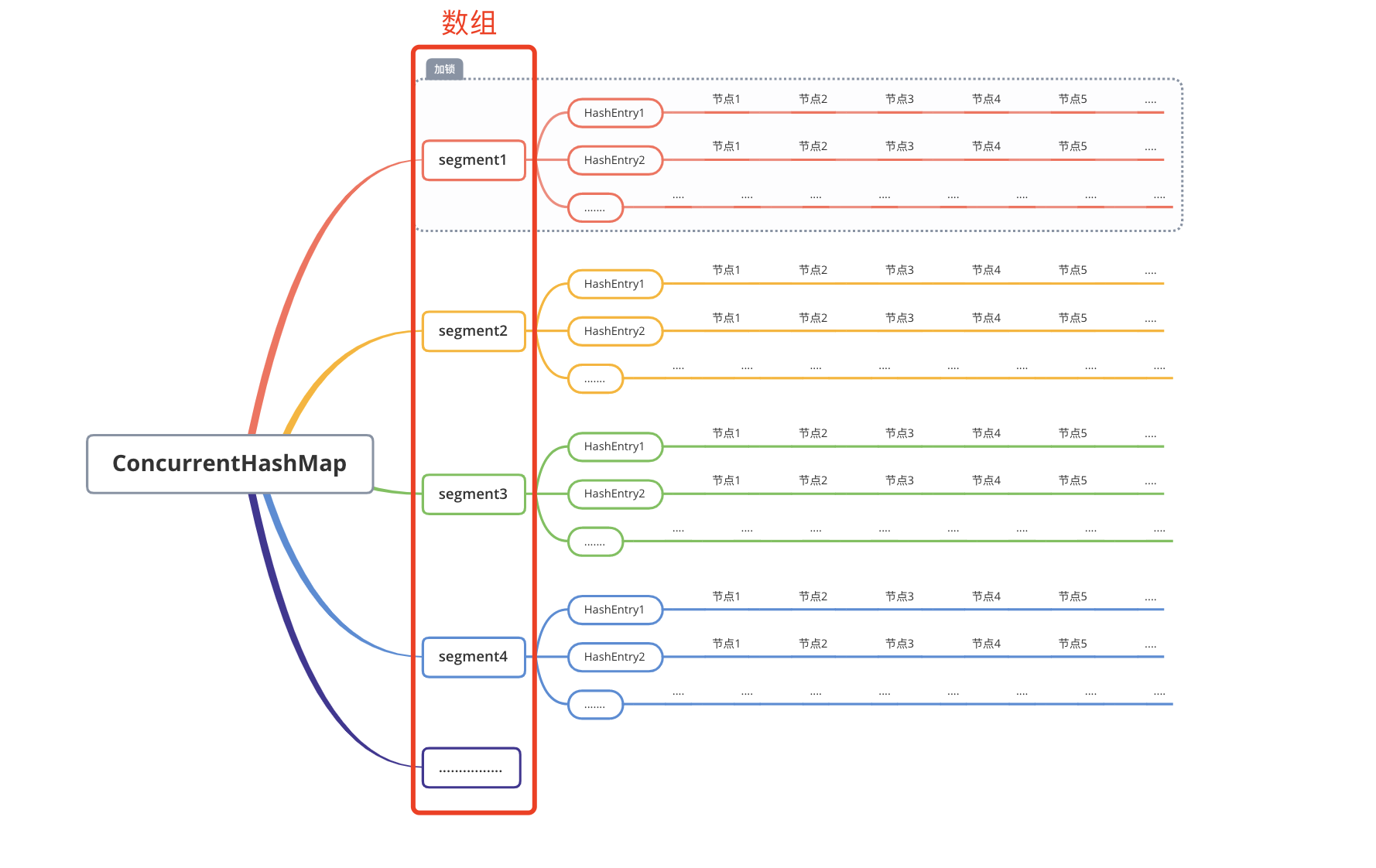
整个ConcurrentHashMap被划分为多个分段,每个分段都是一个独立的哈希表。每个分段独立加锁,细化了锁的粒度,同时允许多个线程同时操作不同的分段,从而提高并发性能。
使用ReentrantLock锁定分段,在执行插入、删除或更新操作时,只有操作涉及的分段会被锁定,其他分段不受影响。
在进行插入操作时,先根据键的哈希值确定应该操作哪个分段,然后锁定该分段并进行操作。这种方法可以减少锁争用,提高并发性能。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
首先判空,然后计算哈希值。计算put进来的元素分配到哪个segment数组上,判断当前segments数组上的元素是否为空,如果分段为空就会使用ensureSegment方法创建segment对象;
最后调用Segment.put方法存放到对应的节点中。
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
ensureSegment方法作用是返回指定索引的分段对象,通过CAS判断,如果还没有分段则创建它并记录在分段表中。
当多个线程同时执行该方法,同时通过ensureSegment方法创建segment对象时,只有一个线程能够创建成功。
其中创建的新segment对象中的加载因子、存放位置、扩容阈值与segment[0]元素保持一致,这样性能更高,因为不用在计算了。
为了保证线程安全,在ensureSegment方法中用Unsafe类中的一些方法做了三次判断,其中最后一次也就是该方法保证线程安全的关键,用到了CAS操作。确保只有一个线程能够成功创建分段。
当多个线程并发执行下面的代码,先执行CAS的线程,判断segment数组中某个位置是空的,然后就把这个线程自己创建的segment数组赋值给seg,即seg = s然后break跳出循环。
后执行的线程会再次判断seg是否为空,因先执行的线程已经seg = s不为空了,所以循环条件不成立,也就不再执行了。
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
Segment.put为了保证线程安全,执行put方法时需要加锁,如果未能获取锁,会执行scanAndLockForPut方法,确保最终能获取到锁。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
// ... 插入节点操作 最后释放锁
}
scanAndLockForPut方法的主要作用就是加锁,如果没有获取锁,就会一致遍历segment数组,直到遍历到最后一个元素。
每次遍历完都会尝试获取锁,如果还是获取不到锁,就会重试,最大次数为MAX_SCAN_RETRIES在CPU多核下为64次,如果大于64次就会强制加锁。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
在JDK1.8中,ConcurrentHashMap进行了重大改进,弃用了分段锁机制,转而采用更细粒度的并发控制机制。
直接用Node数组+链表/红黑树的数据结构来实现,并发控制使用 synchronized 和CAS来操作,整体看起来就像是优化过且线程安全的HashMap。
虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了其属性,这样做只是为了兼容旧版本。
JDK1.8中彻底放弃了Segment转而采用的是Node,其设计思想也不再是JDK1.7中的分段锁思想。
ConcurrentHashMap在JDK1.8中不再使用分段锁,而是使用与HashMap类似的数组+链表/红黑树的数据结构。
数组中的每个桶是一个链表或红黑树的头节点。HashMap不同的是ConcurrentHashMap只是增加了同步操作来控制并发。
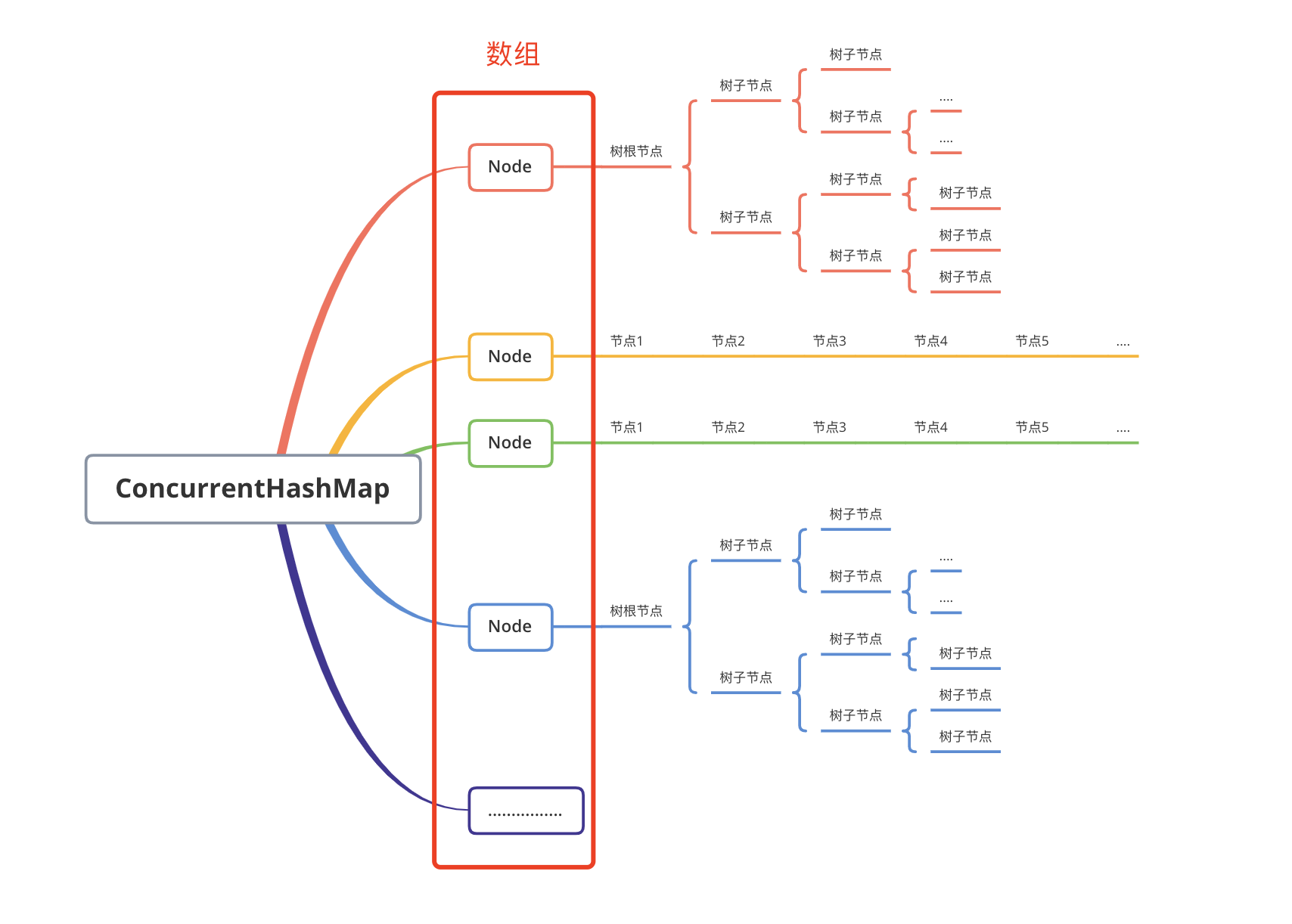
插入操作首先根据键的哈希值定位到具体的桶。如果该桶为空,则使用CAS操作插入新的节点。如果该桶非空,则使用synchronized锁定该桶,并进行链表或红黑树的插入操作。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null)
throw new NullPointerException();
// 计算键的哈希值,并将其扩散
int hash = spread(key.hashCode());
// 记录桶中元素个数
int binCount = 0;
// 循环查找或插入元素
for (Node<K,V>[] tab = table;;) {
Node<K,V> f;
int n, i, fh;
// 如果表为空或长度为0,则进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 计算存储位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果位置为空,则尝试使用 CAS 插入新节点
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // 插入成功,退出循环
}
// 如果位置非空,处理链表或红黑树结构
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f); // 如果处于扩容状态,则帮助进行扩容
else {
V oldVal = null;
// 使用 synchronized 锁定桶
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
// 处理链表结构
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
} else if (f instanceof TreeBin) {
// 处理红黑树结构
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 根据操作结果进行进一步处理
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) // 如果链表长度达到阈值,则转为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal; // 返回旧值
break; // 插入完成,退出循环
}
}
}
// 更新计数器
addCount(1L, binCount);
return null;
}
如果table为空或长度为0,则调用initTable()方法进行初始化。
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
根据键的哈希值hash计算存储在table中的位置。如果该位置为空,则使用casTabAt()方法尝试通过CAS操作插入新的Node节点。
int hash = spread(key.hashCode());
// hash算法,计算存放在map中的位置;要保证尽可能的均匀分散,避免hash冲突
static final int HASH_BITS = 0x7fffffff;
static final int spread(int h) {
// 等同于: key.hashCode() ^ (key.hashCode() >>> 16) & 0x7fffffff
return (h ^ (h >>> 16)) & HASH_BITS;
}
如果位置非空,首先判断是否处于扩容状态MOVED,如果是,则调用helpTransfer()方法协助进行扩容操作。
// MOVED = -1
if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
如果位置上是链表结构(fh >= 0),则遍历链表,根据键查找或插入节点。如果位置上是红黑树结构(f instanceof TreeBin),则调用putTreeVal()方法在红黑树中插入节点。
然后使用synchronized (f)锁定桶,确保在链表或红黑树操作期间其他线程不能修改桶的结构。根据链表长度binCount >= TREEIFY_THRESHOLD(默认是8),则把链表转化为红黑树结构的情况,如果插入操作修改了已有节点的值,则返回旧值。
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
最后调用addCount()方法更新元素计数器,表示成功插入了一个节点。
// 相当于size++
addCount(1L, binCount);
其中addCount()方法中也包含了扩容操作。
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
节点从table移动到nextTable,大体思想是遍历、复制的过程。
通过Unsafe.compareAndSwapInt修改sizeCtl值,保证只有一个线程能够初始化nextTable,扩容后的数组长度为原来的两倍,但是容量是原来的1.5。