访问量 次
访客数 人
Java语言提供了八种基本类型。六种数值类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型,俗称4类8种。
这里只介绍称4类8种,实际上,Java中还存在另外一种基本类型 void,它也有对应的包装类java.lang.Void,不过我们无法直接对它们进行操作。
| 类型 | 位数 | 范围 | 默认值 | 示例 | 备注 |
|---|---|---|---|---|---|
| byte | 8 | -128 ~ 127 | 0 | byte a = 100 byte b = -50 |
节省空间,常用于大型数组 |
| short | 16 | -2^15 ~ 2^15-1 | 0 | short s = 1000 short r = -20000 |
节省空间,int变量占用空间的一半 |
| int | 32 | -2^31 ~ 2^31-1 | 0 | int a = 100000 int b = -200000 |
默认的整型变量 |
| long | 64 | -2^63 ~ 2^63-1 | 0L | long a = 100000L long b = -200000L |
用于表示较大整数 |
| float | 32 | 1.4E-45 ~ 3.4028235E38 | 0.0f | float f = 234.5f |
单精度浮点数,节省内存,不能表示精确值 |
| double | 64 | 4.9E-324 ~ 1.7976931348623157E308 | 0.0d | double d = 123.4 |
双精度浮点数,默认的浮点数类型,不能表示精确值 |
| char | 16 | \u0000 (0) ~ \uffff (65,535) | \u0000 | char letter = 'A' |
存储单一的 Unicode 字符 |
| boolean | ~ | true, false | false | boolean one = true |
JVM 在编译时将 boolean 转换为 int,使用 1 表示 true,0 表示 false。 |
一个byte(字节)等于8个bit(位),bit是最小的单位,1b(字节)=8bit(位)。一般情况下,一个汉字是两个字节,英文与数字是一个字节。
Float和Double的最小值和最大值都是以科学记数法的形式输出的,结尾的"E+数字"表示E之前的数字要乘以10的多少次方,比如3.14E3就是3.14 × 10^3,3.14E-3 就是 3.14 x 10^-3。
boolean 只有两个值,true、false,可以使用 1 bit 来存储,但是具体大小没有明确规定。
JVM 会在编译时期将 boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。JVM 支持 boolean 数组,但是是通过读写 byte 数组来实现的。
在Java中,类型转换是将一种数据类型的值转换为另一种数据类型的过程。 整型、常量、字符型数据可以混合运算。运算前,不同类型的数据先转化为同一类型,然后进行运算。
基本类型的类型转换主要分为两类,隐式类型转换(自动类型转换)和显式类型转换(强制类型转换)。 这些类型转换是为了处理不同数据类型之间的转换需求和类型匹配问题。
基本数据类型转换时需注意:
(int)23.7 == 23;
(int)-45.89f == -45
// 因为 byte 类型是 8 位,最大值为127,所以当 int 强制转换为 byte 类型时,值 128 时候就会导致溢出
int i =128;
byte b = (byte)i;
显式类型转换也叫强制类型转换,显式类型转换在可能出现数据丢失或溢出的风险的情况下进行,需要使用强制类型转换运算符。 基本类型的显式转换顺序:
double -> float -> long -> int -> short -> byte
double -> float -> long -> int -> char
// double -> float -> long -> int -> short -> byte
double doubleValue = 100.04;
float floatValue = (float) doubleValue;
long longValue = (long) floatValue;
int intValue = (int) longValue;
short shortValue = (short) intValue;
byte byteValue = (byte) shortValue;
// double -> float -> long -> int -> char
double doubleVal = 97.04;
float floatVal = (float) doubleVal;
long longVal = (long) floatVal;
int intVal = (int) longVal;
char charValue = (char) intVal;
隐式类型转换是指编译器在编译时自动完成的类型转换,也称为自动类型转换。与显示类型转换相反,这种转换通常在没有数据丢失风险的情况下进行。 Java 会自动将较小的基本数据类型转换为较大的基本数据类型,以避免数据丢失。转换顺序如下:
byte -> short -> int -> long -> float -> double
char -> int -> long -> float -> double
// byte -> short -> int -> long -> float -> double
byte byteValue = 42;
short shortValue = byteValue;
int intValue = shortValue;
long longValue = intValue;
float floatValue = longValue;
double doubleValue = floatValue;
// char -> int -> long -> float -> double
char charValue = 'A';
int charToInt = charValue;
long charToLong = charToInt;
float charToFloat = charToLong;
double charToDouble = charToFloat;
隐式类型转换还有一种比较特殊的情况,对于 += 运算符来说,如果左右两边的操作数类型不同,编译器会自动将右边操作数的类型转换为左边操作数的类型,然后执行加法操作和赋值。
public class AdditionAssignment {
public static void main(String[] args) {
byte byteValue = 10;
byteValue += 5; // 等价于 byteValue = (byte)(byteValue + 5);
int intValue = 100;
long longValue = 200L;
intValue += longValue; // 等价于 intValue = (int)(intValue + longValue);
float floatValue = 10.5f;
double doubleValue = 20.5;
floatValue += doubleValue; // 等价于 floatValue = (float)(floatValue + doubleValue);
}
}
| 基本类型 | 包装类型 |
|---|---|
| byte | Byte |
| boolean | Boolean |
| short | Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
在这八个类名中,除了 Integer 和 Character 类以外,其它六个类的类名和基本数据类型一致,只是类名的第一个字母大写。
其中Integer、Long、Byte、Double、Float、Short都是抽象类Number的子类。
因为 Java 是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。
比如在集合类中,我们是无法将 int 、double 等类型放进去的,因为集合的容器要求元素是 Object 类型,所以才有了对应基本类型分包装类型。
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。以Integer转int 为例:
Integer x = 2; // 装箱 调用了 Integer.valueOf(2)
int y = x; // 拆箱 调用了 X.intValue()
Integer i = 10; //自动装箱
int b = i; //自动拆箱
为了探究自动拆箱、自动装箱的原理,将以下代码进行编译,查看class文件:
public static void main(String[]args){
Integer integer=1;
int i=integer;
}
反编译得到
public static void main(String[]args){
Integer integer=Integer.valueOf(1);
int i=integer.intValue();
}
int的自动装箱是通过Integer.valueOf()方法来实现的,Integer的自动拆箱都是通过 integer.intValue来实现的。
其实自动装箱和自动拆箱是Java中的语法糖,用于简化基本数据类型和其对应包装类型之间的转换操作。
当将基本数据类型赋值给对应的包装类型时,编译器会调用包装类型的valueOf()方法来创建一个包装对象,并将基本数据类型的值传递给这个方法。
当需要使用包装类型对象中的值进行基本数据类型的操作时,编译器会自动调用包装类型对象的xxxValue()方法,将包装对象转换为对应的基本数据类型值。
自动装箱和拆箱虽然方便,但是在使用的时候也需要注意一些问题:
==,虽然 -128 到 127 之间的数字可以,但是这个范围之外还是需要使用 equals方法进行比较;null,那么在自动拆箱的时候的就会报NullPointerException,在使用时需要格外注意;在Java中,对于某些包装类型的对象,存在一个缓存池,这是一种优化机制,可以减少频繁创建对象的开销,提升性能。
基本类型对应的缓冲池如下:
Boolean类型的true和false值在静态初始化块中被缓存起来了;Byte类型在 -128 到 127 之间的值会被缓存;Character类型在 ‘\u0000’ 到 ‘\u007F’ 之间的值会被缓存;Short、Integer和Long类型在范围 -128 到 127 之间的值会被缓存;在使用这些基本类型对应的包装类型时,如果该数值范围在缓冲池范围内,就可以直接使用缓冲池中的对象。两种浮点数类型的包装类Float,Double并没有实现常量池技术。
在JDK 1.8所有的数值类缓冲池中,Integer的缓冲池IntegerCache很特殊,这个缓冲池的下界是-128,上界默认是127,但是这个上界是可调的,在启动JVM的时候,通过-XX:AutoBoxCacheMax=<size>来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为java.lang.IntegerCache.high系统属性,然后 IntegerCache初始化的时候就会读取该系统属性来决定上界。
使用Integer.valueOf()方法来创建Integer对象时,会优先从缓冲池中获取对象,如果缓冲池中不存在该值的对象,则会创建一个新的对象。
new Integer(123),这种方式会显式地创建一个新的Integer对象,每次调用new Integer(123)都会创建一个新的对象实例。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false 因为是两个不同的对象实例
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // true 因为返回的是同一个缓存池中的对象实例
Integer.valueOf()方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
在 Java 8 中,Integer缓存池的大小默认为 -128~127,在源码中也能看到具体的实现。
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
而编译器会在自动装箱过程会调用 valueOf()方法,因此多个值相同且值在缓存池范围内的Integer实例使用自动装箱来创建,那么就会引用相同的对象。
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
所以Integer、int 在 -127~128之间是不会创建新的对象的,即
Integer a = new Integer(12);
int b = 12;
System.out.println(a==b);//true
在Java中,引用类型是指除了基本数据类型之外的所有类型,它们都是通过指向一个对象(类似于C的指针)来访问和操作的,所以叫做引用类型。所有引用类型的默认值都是null。
引用类型主要包括:
class MyClass {
// 类
}
int[] arr = new int[10];
interface MyInterface {
// 接口
}
@interface MyAnnotation {
// 注解
}
enum Day {
// 枚举
}
与基本类型的区别:
null值:引用类型的变量可以赋予null值,表示它不引用任何对象。使用未初始化的引用类型变量或将其设置为null可以避免空指针异常;需要注意的是String类是引用类型,不是基本类型。
默认情况下,Java中的浮点数类型是double类型,如果你希望定义一个float类型的浮点数,需要在数值后面加上 F 或 f 后缀,例如float f = 1.23f。
Java 中的浮点数类型 (float和double)是用来表示近似值的,而不是精确的数值。
因此,在涉及到精确计算的场景中,尤其是涉及货币等需要精确表示的值时,应当使用BigDecimal类型来避免精度问题。
在Java中,引用类型的类型转换主要涉及向上转型和向下转型两种操作,引用类型的转换是基于继承关系和多态性,只有在存在父子类关系或者接口实现关系时才能进行。
向上转型是指将一个子类的对象引用转换为其父类类型或者更高层次的类型。 向上转型是安全的,这种转型是隐式的,编译器会自动进行处理,子类对象可以直接赋值给父类类型的引用变量。 这种转型通常发生在子类对象需要作为父类对象使用的场景中。
class Animal { }
class Dog extends Animal { }
public class Main {
public static void main(String[] args) {
Dog myDog = new Dog(); // 创建Dog对象
Animal myAnimal = myDog; // 向上转型为Animal类型,隐式转型
}
}
向下转型是指将一个父类类型或者更高层次的类型的对象引用转换为其子类类型。
向下转型是需要显式指定的,并且需要进行类型检查(instanceof)以及类型转换(cast)操作。如果实际对象不是目标类型,会抛出ClassCastException异常。
如果引用变量是null,无法进行任何类型转换操作。在转换之前,需要确保引用变量不为null,否则会导致NPE异常。
class Animal { }
class Dog extends Animal { }
public class Main {
public static void main(String[] args) {
Animal myAnimal = new Dog(); // 向上转型为Animal类型
if (myAnimal instanceof Dog) {
Dog myDog = (Dog) myAnimal; // 安全的向下转型
}
}
}
在Java中,引用类型的比较涉及到比较对象的引用值,而不是对象的内容。这是因为在Java中,每个对象变量存储的是对象的引用地址,而不是对象本身。
使用==操作符比较两个对象引用时,比较的是它们在内存中的地址是否相同,即是否引用同一个对象。
String str1 = new String("hello");
String str2 = new String("hello");
String str3 = str1;
System.out.println(str1 == str2); // false,str1和str2引用不同的对象实例
System.out.println(str1 == str3); // true,str1和str3引用同一个对象实例
在比较两个对象是否相等时,使用最多的是equals()方法,它通常在类中被重写以实现特定的比较逻辑。
默认情况下,equals()方法和==操作符行为一样,比较的是对象的引用,但是如果类中重写了equals()方法,那就不一定了。
String str1 = new String("hello");
String str2 = new String("hello");
System.out.println(str1.equals(str2)); // true,比较的是对象的内容
上面的例子中,str1.equals(str2)返回true,因为String类重写了equals()方法,用来比较字符串的内容而不是引用值。
// String类中的equals()方法
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
在Java中,常量指的是一种不可改变的量或者数值,其值在程序执行过程中不会发生变化。常量在Java中有两种主要的形式:
final修饰的变量:Java常量简单理解为final修饰的变量。Java常量就是在程序运行过程中一直不会改变的量的量,final修饰的变量必须在声明时初始化,一旦初始化后,其值就不能再被修改;常量和数据类型之间有密切的关系,常量可以是任何数据类型的值,包括基本数据类型和引用类型,如对象或数组。
常量的数据类型必须与其值的数据类型匹配,例如final int MAX_SIZE = 100中的常量MAX_SIZE是整数类型。
为防止混淆和更好理解,将常量,变量和字面量用代码举例:
int a = 10; // a为变量,10为字面量
final int b = 10; // b为常量,10为字面量
static c = "Hello World"; // c为变量,HelloWorld为字面量
int a = 10,这里的a是左值,10为右值;在 Java 中使用final关键字来修饰常量,声明方式和变量类似。
要声明一个常量,第一需要制定数据类型,第二需要通过final关键字进行限定格式:final 数据类型 常量名称[=值]。
final关键字表示最终的,它可以修改很多元素:
final修饰变量就变成了常量;final用于修饰方法时,表示该方法不能被子类重写;final用于修饰类时,表示该类不能被继承;常量因为被final修饰一旦初始化后,其值就不能再被修改,所以在定义常量时就需要对该常量进行初始化。
为了与变量区别,提高代码的可读性和可维护性,常量取名一般都用大写字符,单词之间使用下划线 _分隔,如:
final double PI = 3.1415927;
public static final int MAX_VALUE = 100;
常量可以根据它们的作用范围和声明位置将其归类。常量的类型包括静态常量、成员常量和局部常量。
public class HelloWorld {
// 静态常量
public static final double PI = 3.14;
// 声明成员常量
final int y = 10;
public static void main(String[] args) {
// 声明局部常量
final double x = 3.3;
}
}
常量池是Java为了提高性能和减少内存开销而引入的一种机制,常量则是程序中不可改变的值,在程序中定义的不可变值,存储在栈、堆或常量池中。
常量池、可以看做是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等类型。 在Java中,大致上可以分为三种常量池,分别是字符串常量池、Class常量池(静态常量池)和运行时常量池。 我们常说的常量池,指的是方法区中的运行时常量池。
在Java中,每个编译后的.class文件中包含一个常量池,用于存储与类相关的各种常量,这个常量池被称为Class常量池,这些常量包括字面量和符号引用。
class文件,主要在平台无关性和网络移动性方面使Java更适合网络。
它在平台无关性方面的任务,是为Java程序提供独立于底层主机平台的二进制形式的服务。
二进制形式的服务会产生字节码,有了字节码,无论是哪种平台(如Windows、Linux等),只要安装了虚拟机,都可以直接运行字节码。
目前Java虚拟机已经可以支持很多除Java语言以外的语言了,如Groovy、JRuby、Jython、Scala等。之所以可以支持,就是因为这些语言也可以被编译成字节码。
而虚拟机并不关心字节码是有哪种语言编译而来的。
来看一下字节码文件,将下面代码通过javac命令编译:
public class HelloWorld {
public static void main(String[] args) {
String s = "123";
}
}
生成.class文件.vi命令查看:
Êþº¾^@^@^@4^@^Q
^@^D^@^M^H^@^N^G^@^O^G^@^P^A^@^F<init>^A^@^C()V^A^@^DCode^A^@^OLineNumberTable^A^@^Dmain^A^@^V([Ljava/lang/String;)V^A^@
SourceFile^A^@^OHelloWorld.java^L^@^E^@^F^A^@^C123^A^@7com/example/springboot/example/security/util/HelloWorld^A^@^Pjava/lang/Object^@!^@^C^@^D^@^@^@^@^@^B^@^A^@^E^@^F^@^A^@^G^@^@^@^]^@^A^@^A^@^@^@^E*·^@^A±^@^@^@^A^@^H^@^@^@^F^@^A^@^@^@^C^@ ^@ ^@
^@^A^@^G^@^@^@ ^@^A^@^B^@^@^@^D^R^BL±^@^@^@^A^@^H^@^@^@
^@^B^@^@^@^E^@^C^@^F^@^A^@^K^@^@^@^B^@^L
使用16进制打开class文件,即使用vim xxx.class ,然后在交互模式下,输入%!xxd ,即可得到:
00000000: cafe babe 0000 0034 0011 0a00 0400 0d08 .......4........
00000010: 000e 0700 0f07 0010 0100 063c 696e 6974 ...........<init
00000020: 3e01 0003 2829 5601 0004 436f 6465 0100 >...()V...Code..
00000030: 0f4c 696e 654e 756d 6265 7254 6162 6c65 .LineNumberTable
00000040: 0100 046d 6169 6e01 0016 285b 4c6a 6176 ...main...([Ljav
00000050: 612f 6c61 6e67 2f53 7472 696e 673b 2956 a/lang/String;)V
00000060: 0100 0a53 6f75 7263 6546 696c 6501 000f ...SourceFile...
00000070: 4865 6c6c 6f57 6f72 6c64 2e6a 6176 610c HelloWorld.java.
00000080: 0005 0006 0100 0331 3233 0100 3763 6f6d .......123..7com
00000090: 2f65 7861 6d70 6c65 2f73 7072 696e 6762 /example/springb
000000a0: 6f6f 742f 6578 616d 706c 652f 7365 6375 oot/example/secu
000000b0: 7269 7479 2f75 7469 6c2f 4865 6c6c 6f57 rity/util/HelloW
000000c0: 6f72 6c64 0100 106a 6176 612f 6c61 6e67 orld...java/lang
HelloWorld.class文件中的前八个字母是cafe babe,这就是class文件的魔数。
cafe babe 0000 0034 0011 0a00 0400 0d08
魔数 此版本号 主版本号 常量池计数器 常量池计数区
我们需要知道的是,每个class文件的前四个字节表示魔数,他的唯一作用是确定这个文件是否是一个能被虚拟机接受的class文件,紧接着魔数的4个字节后,第5个和第6个表示次版本号,第7、8表示主版本号。
我生成的class文件的版本号是16进制0034,转化为10进制是52,这是Java8对应的版本。也就是说,这个版本的字节码,在JDK 1.8以下的版本中无法运行,在版本号后面的,就是Class常量池入口了。
Class常量池中主要存放两大类常量,字面量和符号引用。
int a = 10,这里的a是左值,10为右值;在编译的时候每个java类都会被编译成一个class文件,但在编译的时候虚拟机并不知道所引用类的地址,所以就用符号引用来代替,
而在解析阶段就是为了把符号引用转化成为真正的地址的过程。
解析阶段: Java类从加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载、 验证、 准备、 解析、 初始化、 卸载,总共七个阶段。其中验证、准备、解析统称为连接。 而在解析阶段会有一步将常量池当中二进制数据(符号引用)转化为直接引用的过程。
在Java编译阶段,由.java文件会生成.class文件。
class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,用于存放编译器生成的各种字面量和符号引用。
由于不同的class文件中包含的常量的个数是不固定的,所以在class文件的常量池入口处设置两个字节的常量池容量计数器,记录了常量池中常量的个数。
Class常量池可以理解为是Class文件中的资源仓库。
Class常量池中保存了各种常量,而这些常量都是开发者定义出来,需要在程序的运行期使用的。
Java代码在进行javac编译的时候,在class文件中不会保存各个方法、字段的最终内存布局信息,因此这些字段、方法的符号引用不经过运行期转换的话无法得到真正的内存入口地址,也就无法直接被虚拟机使用。
当虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析、翻译到具体的内存地址之中。
Class常量池是用来保存常量的一个媒介场所,并且是一个中间场所。在JVM真的运行时,需要把常量池中的常量加载到内存中。
运行时常量池是每一个类或接口的常量池的运行时表示形式。
每一个运行时常量池都分配在Java虚拟机的方法区之中,在类和接口被加载到虚拟机后,对应的运行时常量池就被创建出来。
当创建类或接口的运行时常量池时,如果构造运行时常量池所需的内存空间,超过了方法区所能提供的最大值,则JVM会抛OutOfMemoryError异常。
简单说来就是JVM在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
根据JVM规范,JVM内存共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈五个部分,运行时常量池存放在JVM内存模型中的方法区中。
在不同版本的JDK中,运行时常量池所处的位置也不一样。以HotSpot为例,JDK1.7之前方法区位于永久代,由于一些原因在JDK1.8时彻底祛除了永久代,用元空间代替。
运行时常量池内容包含了Class常量池中的常量和字符串常量池中的内容。 它包含多种不同的常量,也包括编译期就已经明确的数值字面量、到运行期解析后才能够获得的方法或者字段引用。 它扮演了类似传统语言中符号表的角色,不过它存储数据范围比通常意义上的符号表要更为广泛。
保存在JVM方法区中的叫运行时常量池,在 class/字节码 文件中的叫Class常量池(静态常量池)。 与类文件中的Class常量池不同的是,运行时常量池是在类加载到内存后动态生成的,相对于Class文件常量池的另一重要特征是具备动态性。 运行时常量池的动态性体现在它不仅仅是简单地静态存储常量值,而是支持了Java程序在运行时动态加载类、操作字符串、实现动态代理和利用反射等高级特性。 例如,反射机制可以通过运行时常量池中的符号引用动态加载类、获取和调用方法等。
一个Java源文件中的类、接口,编译后产生一个字节码文件。 而Java中的字节码需要数据支持,通常这种数据会很大以至于不能直接存到字节码里,换另一种方式,可以存到常量池,这个字节码包含了指向常量池的引用,在动态链接的时候会用到运行时常量池。
比如:如下的代码:
public class SimpleClass {
public void sayHello() {
System.out.println("hello");
}
}
虽然上述代码生成的class文件只有194字节,但是里面却使用了String、System、PrintStream及Object等结构。
这里的代码量其实很少了,如果代码多的话,引用的结构将会更多,这样就体现出常量池的作用了。
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享,避免了相同内容的字符串的创建,节省了内存,省去了创建相同字符串的时间,同时提升了性能。
在Java编程中,字符串类型是一个极其基础和重要的类,字符串属于对象,并且由专门的String类来创建和管理,它被广泛用于表示和操作文本数据。
由于 String被声明为 final,它是不可变的,即一旦创建,其值无法更改。这种设计不仅确保了字符串的安全性和稳定性,还优化了内存使用。
String类还实现了Serializable接口,这意味着字符串可以被序列化,以便在不同的Java虚拟机之间传输。
此外,String实现了Comparable接口,使得字符串对象可以进行自然排序。
在Java8中,String内部使用char数组存储数据。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
在Java9之后,String类的实现改用byte数组存储字符串,同时使用 oder来标识使用了哪种编码。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}
那么为什么要改变存储结构呢? 官方的解释:
The current implementation of the String class stores characters in a char array, using two bytes (sixteen bits) for each character. Data gathered from many different applications indicates that strings are a major component of heap usage and, moreover, that most String objects contain only Latin-1 characters. Such characters require only one byte of storage, hence half of the space in the internal char arrays of such String objects is going unused.
We propose to change the internal representation of the String class from a UTF-16 char array to a byte array plus an encoding-flag field. The new String class will store characters encoded either as ISO-8859-1/Latin-1 (one byte per character), or as UTF-16 (two bytes per character), based upon the contents of the string. The encoding flag will indicate which encoding is used.
文档大意:String类的当前实现将字符存储在char数组中,每个字符使用两个字节(16位)。
从许多不同的应用程序收集的数据表明,字符串是堆使用的主要组成部分,而且大多数字符串对象只包含拉丁字符。
这些字符只需要一个字节的存储空间,因此这些字符串对象的内部char数组中有一半的空间将不会使用。
我们建议将String类的内部表示从UTF-16字符数组更改为一个字节数组加上一个编码标志字段。
新的String类将根据字符串的内容存储编码为ISO-8859-1/Latin-1(每个字符一个字节)或UTF-16(每个字符两个字节)的字符。
编码标志将指示所使用的编码。
简单说来就是用char数组存,有些数据占不了两个字节,所以为了节约资源改成byte数组存放。
如果存放的不是拉丁文则需要占两个字节,所以还需要加上编码标记。
基于String的数据结构,StringBuffer和StringBuilder也同样做了修改。
String类型具有不可变性,因为底层存储的value数组被声明为final,这意味着value数组初始化之后就不能再引用其它数组。
String是Java中一个不可变的类,所以一旦一个string对象在内存中被创建出来,他就无法被修改。
下面代码说明String是不可变的:
public class MainTest {
String str = new String("good");
char [] ch = {'t','e','s','t'};
public void change(String str, char ch []) {
str = "test ok";
System.out.println( "chanage方法里str=" + str); // chanage方法里str=test ok
ch[0] = 'b';
}
public static void main(String[] args) {
MainTest ex = new MainTest();
ex.change(ex.str, ex.ch);
System.out.println(ex.str); // good
System.out.println(ex.ch);// best
}
}
String类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象,那么为什么要把String类设计成不可变的呢?
String经常作为参数,String不可变性可以保证参数不可变。
实际项目中会用到,比如数据库连接串、账号、密码等字符串,只有不可变的连接串、用户名和密码才能保证安全性。String对象一旦创建就不能被修改,因此多个线程可以安全地共享相同的String实例,而不需要担心数据被修改。String常量池的需要。字符串常量池的基础就是字符串的不可变性,如果字符串是可变的,那想一想,常量池就没必要存在了。
如果一个String 对象已经被创建过了,那么就会从String常量池中取得引用。只有String是不可变的,才可能使用 字符串常量池。hash值。因为String的hash值经常被使用,像Set、Map结构中的key值也需要用到HashCode来保证唯一性和一致性,因此不可变的HashCode才是安全可靠的。new String("abc")会创建几个对象? 这是面试中经常问的一个问题,先说答案两个字符串对象,前提是String常量池中还没有 “abc” 字符串对象。
第一个对象是"abc",它属于字符串字面量,因此编译时期会在字符串常量池中创建一个字符串对象,指向这个 “abc” 字符串字面量,而使用new的方式会在堆中创建一个字符串对象。
来证明一下,到底是不是创建了两个对象,先看一下JDK8 中new String()源代码:
/**
* Initializes a newly created {@code String} object so that it represents
* the same sequence of characters as the argument; in other words, the
* newly created string is a copy of the argument string. Unless an
* explicit copy of {@code original} is needed, use of this constructor is
* unnecessary since Strings are immutable.
*
*/
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
文档注释大意:初始化新创建的String对象,使其表示与实参相同的字符序列,换句话说,新创建的字符串是实参字符串的副本。
除非需要显式复制形参的值,否则没有必要使用这个构造函数,因为字符串是不可变的。
用字节码看一下,创建一个测试类,其main方法中使用这种方式来创建字符串对象。
public class MainTest {
public static void main(String[] args) {
String s = new String("abc");
}
}
使用javap -verbose命令进行反编译,得到以下内容:
// ...
Constant pool:
// ...
#2 = Class #18 // java/lang/String
#3 = String #19 // abc
// ...
#18 = Utf8 java/lang/String
#19 = Utf8 abc
// ...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=2, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String abc
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
// ...
在Constant Pool中,#19存储这字符串字面量"abc",#3是String Pool的字符串对象,它指向#19这个字符串字面量。
在main方法中,0:行使用new #2在堆中创建一个字符串对象,并且使用ldc #3将String Pool中的字符串对象作为String构造函数的参数。
所以能看到使用new String()的方式创建字符串是创建两个对象。
那么使用new String("a") + new String("b")会创建几个对象?会创建6个对象:
new StringBuilder()对象;new String("a")会从堆空间创建一个对象;new String("b")会从堆空间创建一个对象;new StringBuilder().append()添加完字符串后,会通过StringBuilder.toString()中会创建一个 new String("ab"),但是调用toString()方法,不会在常量池中生成ab字符串;在JVM中,为了减少相同的字符串的重复创建,为了达到节省内存的目的,会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。 字符串常量池保存着所有字符串字面量,这些字面量在编译时期就被确定。
字符串常量池不同版本JDK中位置是不一样的,Java6及以前,字符串常量池存放在永久代,Java7将字符串常量池的位置调整到Java堆内。 那么字符串常量池为什么要调整位置?
是为了优化内存管理和避免特定情况下的内存溢出问题。
在早期的Java版本(如JDK 6及之前),字符串常量池通常是存放在永久代,GC对永久代的回收效率很低,只有在Full GC的时候才会触发,这就导致字符串常量池回收效率不高。
而我们开发过程中,使用频率比较高,会有大量的字符串被创建,如果无法及时回收,容易导致永久代内存不足。所以JDK7之后将字符串常量池放到堆里,能及时回收内存,避免出现OOM错误。
如何证明Java8中的字符串常量池方到了堆中?代码演示:
public class MainTest {
// 虚拟机参数: -Xmx6m -Xms6m -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m
public static void main(String[] args) {
HashSet<String> hashSet = new HashSet<>();
short i = 0;
while (true) {
hashSet.add(String.valueOf(i++).intern());
}
}
}
抛出异常证明Java8中的字符串常量池方到了堆中。
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
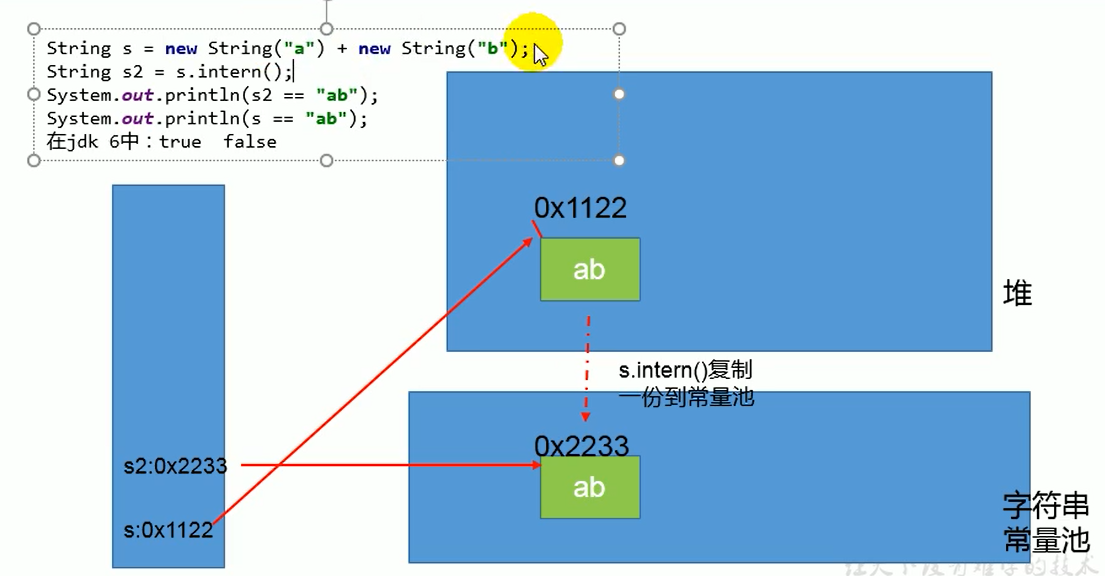
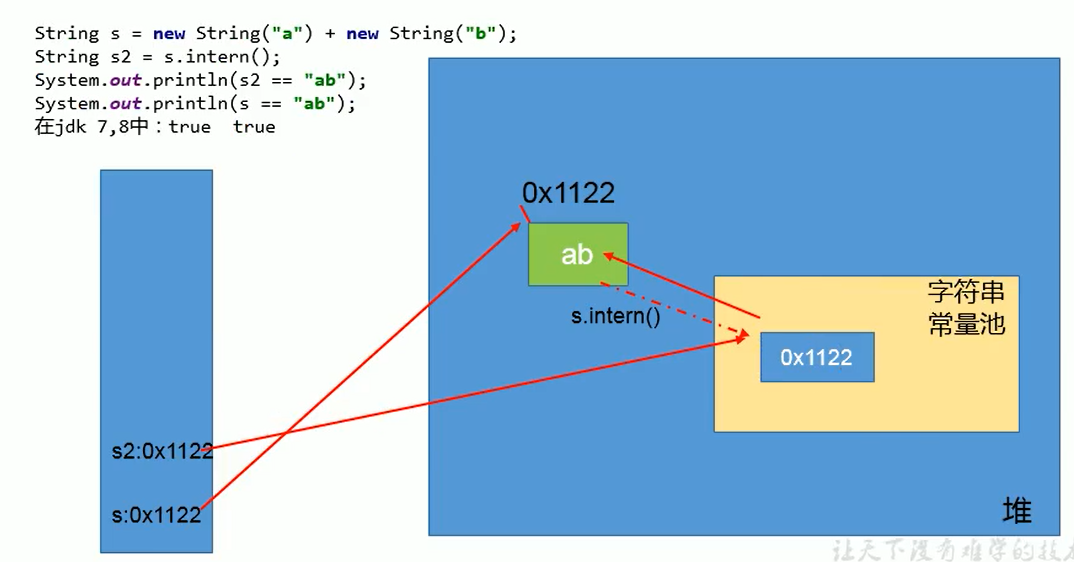
关于JDK1.6、JDK1.7字符串常量池,有一道相关的面试题。下列代码在JDK1.6、JDK1.7中执行结果不同:
public class MainTest {
public static void main(String[] args) {
String s3 = new String("1") + new String("1"); // ==> new String("11"); 并不会在字符串常量池创建 "11"
// 在JDK7及之后,JVM为了节省空间进行优化,在字符串常量池中的对象只保存了堆中对象的地址,而并不是创建了一个真正的对象;
// "11"不在字符串常量池中 ,把"11"放入字符串常量池中 因为堆中已经存在对象,JDK6在字符串池中保存的是一个真正的对象 JDK7保存的是一个引用地址
s3.intern();
// 获取字符串常量池的引用
String s4 = "11";
System.out.println(s3 == s4); // JDK1.6: false JDK1.7: true
}
}
在JDK1.7及之后,new String("1")会在堆中创建一个对象并且会在字符串常量池中创建一个对象。
因为在堆中已经创建了对象,JVM为了节省空间,在字符串常量池中的对象只保留了引用堆中对象的地址,而并不是创建了一个真正的对象,所以就会出现true的情况。
JDK1.6创建对象被放在了永久区中的字符串常量池,而并非堆中,JVM无法对其进行优化,所以是false。
JDK1.6中,将这个字符串对象尝试放入字符串常量池:
JDK1.7起,将这个字符串对象尝试放入字符串常量池:
在Java中,字符串常量池是由JVM自动管理的,开发者通常不需要显式地将字符串加入到字符串常量池中。 Java中的字符串常量池有以下几种方式来存储字符串:
String str1 = "hello"; // "hello"会被加入字符串常量池
String str3 = "hel" + "lo"; // 编译器会将"hel" + "lo"优化为"hello",并将"hello"放入字符串常量池
intern()方法:调用这个方法可以将字符串添加到字符串常量池中,并返回常量池中字符串的引用。
如果字符串常量池中已经存在相同内容的字符串,则返回常量池中字符串的引用。
String str2 = new String("hello").intern(); // 将字符串"hello"添加到字符串常量池,并返回常量池中的引用
关于intern是一个native方法,调用的是底层C的方法:
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*/
public native String intern();
intern方法文档注释大意是:字符串池最初是空的,由String类私有地维护。
在调用intern方法时,如果池中已经包含了由equals(object)方法确定的与该字符串对象相等的字符串,则返回池中的字符串。
否则,该字符串对象将被添加到池中,并返回对该字符串对象的引用。
下面示例中s1和s2采用new String()的方式新建了两个不同字符串,而s3和s4是通过s1.intern()方法取得一个字符串引用。
intern()首先把s1引用的字符串放到String Pool中,然后返回这个字符串引用,因此s3和s4引用的是同一个字符串。
public class MainTest {
public static void main(String[] args) {
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true
}
}
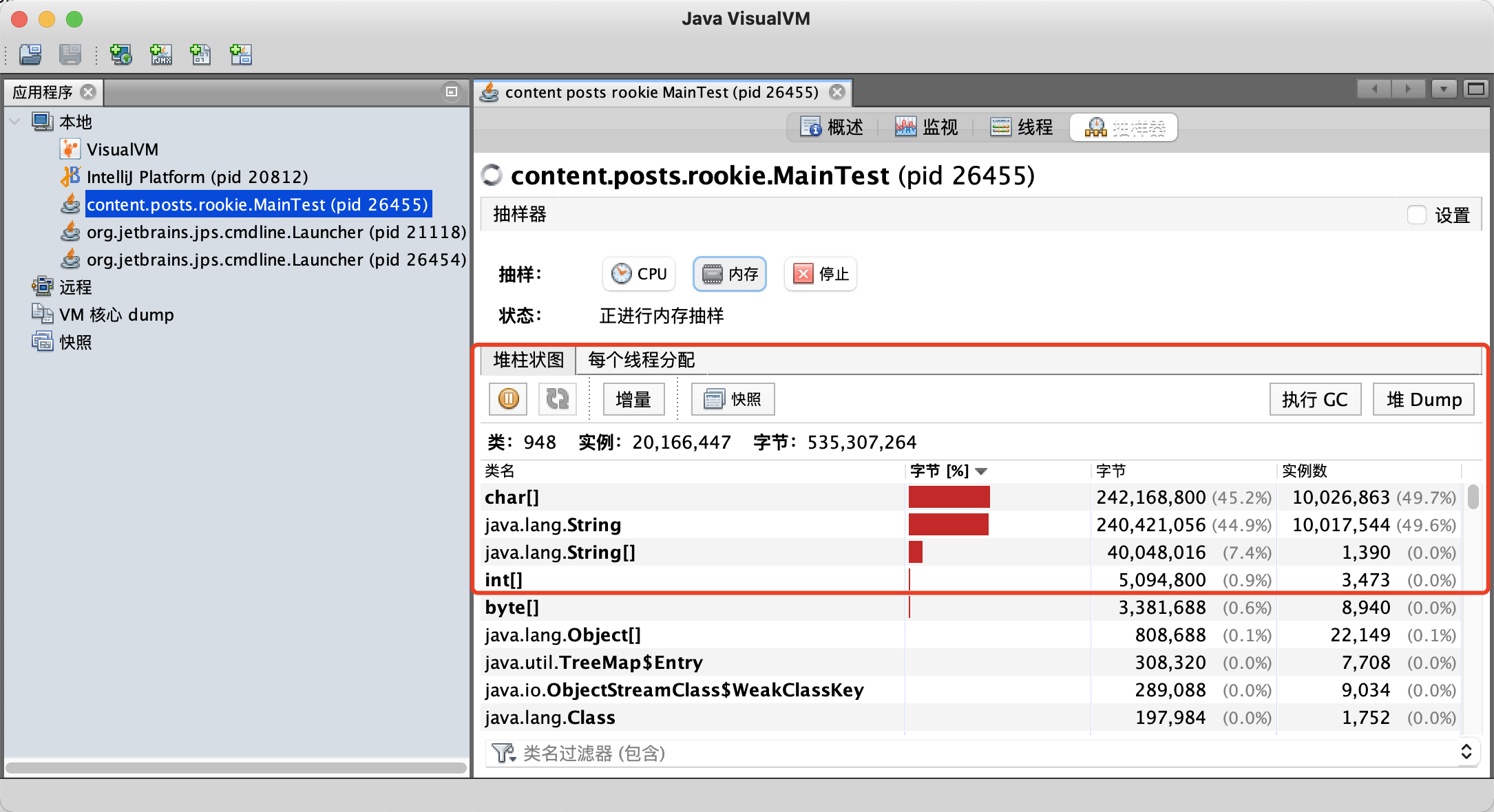
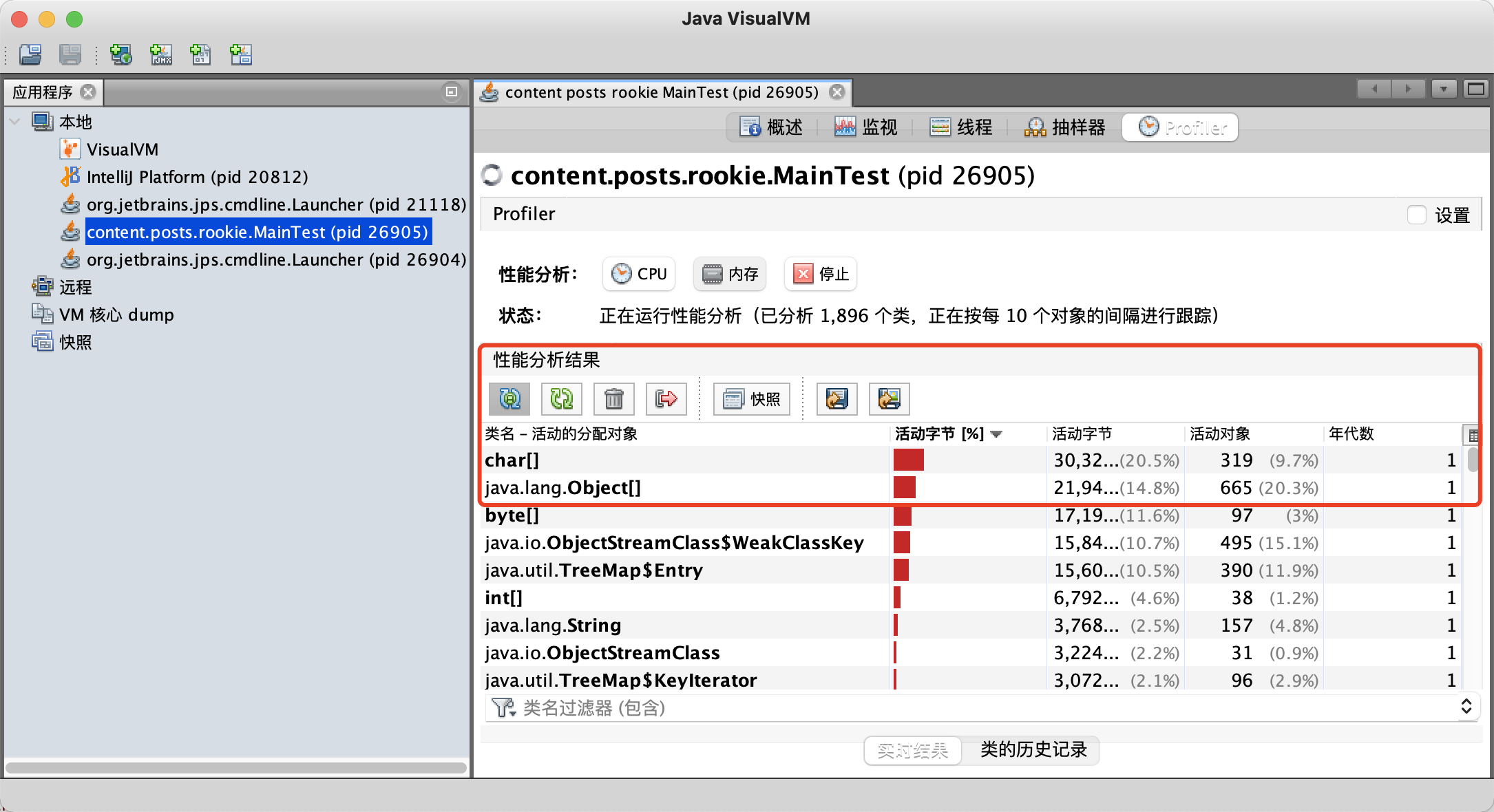
对于程序中大量使用存在的字符串时,尤其存在很多已经重复的字符串时,使用intern()方法能够节省内存空间。
public class MainTest {
static final int MAX_COUNT = 1000 * 10000;
static final String[] arr = new String[MAX_COUNT];
public static void main(String[] args) {
Integer [] data = new Integer[]{1,2,3,4,5,6,7,8,9,10};
long start = System.currentTimeMillis();
for (int i = 0; i < MAX_COUNT; i++) {
// arr[i] = new String(String.valueOf(data[i%data.length])); // 花费的时间为:3074
arr[i] = new String(String.valueOf(data[i%data.length])).intern(); // 花费的时间为:1196
}
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));
try {
Thread.sleep(1000000);
} catch (Exception e) {
e.getStackTrace();
}
System.gc();
}
}
不使用intern方法
使用intern方法后
字符串常量池是不会存储相同内容的字符串的,字符串常量池其实是一个固定大小的Hashtable。
如果放进字符串常量池的字符串非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern()时性能会大幅下降。
使用参数-XX:StringTablesize可设置字符串常量池的的长度,可以配置不同版本的Java,运行下列代码,使用命令进行查看stringTableSize大小:
jsp(获取程序进程ID) -> jinfo -flag StringTableSize 进程ID
public class MainTest {
public static void main(String[] args) {
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
不同JDK版本字符串常量池的的长度:
stringTable是固定的,为1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。-XX:StringTablesize设置没有要求,可随意设置;stringTable的长度默认值是60013,-XX:StringTablesize设置没有要求,可随意设置;stringTable的长度默认为 60013,但不能低于 1009。创建字符串,常见的大概有这么几种方式:
String直接创建
String str1 = "123";
String对象创建
String str2 = new String("123");
String引用创建
String str3 = str1;
String str = String.format("浮点型变量: %f, 整型变量: %d, 字符串变量: %s", 1.0f, 1, "1");
System.out.println(str);
所有String对象都是不可变的,一旦创建,其内容不能改变,这使得字符串在多线程环境中是安全的。
通过字面量的方式创建给一个字符串赋值,存储在字符串常量池中,而new创建的字符串对象在堆上。
因为String类是不可变的,所以所谓字符串拼接,都是重新生成了一个新的字符串。
以下是字符串的几种拼接的方式:
concat方法连接字符串
String str2 = "123".concat("456");
System.out.println(str2);
// 在编译时会编译成 String str4 = "123456";
String str3 = "123" + "456";
// 会调用StringBuilder.append方法
String str4 = str3 + "789";
System.out.println(str3);
System.out.println(str4);
Stringbuilder, StringBuffer
StringBuilder builder = new StringBuilder();
StringBuffer buffer = new StringBuffer();
String str5 = builder.append(str).append("456").toString();
String str6 = buffer.append(str).append("456").toString();
System.out.println(str5);
System.out.println(str6);
String.join方法连接字符串
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
String str7 = String.join("-", list);
String str8 = String.join("~", new String[]{"1","2","3"});
System.out.println(str7);
System.out.println(str8);
apache.commons
// Java8提供的String.join方法和`apache.commons`方法相似.
// 主要作用是将数组或集合以某拼接符拼接到一起形成新的字符串
String str9 = StringUtils.join(new String[]{str, "456", "789"});
如果在处理大量字符串的时候就需要注意性能和耗时,以下是耗时比较(短->长):StringBuilder<StringBuffer<concat<+<StringUtils.join 。
拼接字符串最简单的方式就是直接使用符号”+“来拼接,其实“+”是Java提供的一个语法糖。 语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。 语法糖让程序更加简洁,有更高的可读性。
为了探究“+”拼接的原理,用javap -verbose命令进行反编译看一下:
public static void main(String[] args) {
String str1 = "123";
String str2 = "456";
String str3 = str1 + str2;
System.out.println(str3);
}
// ...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: ldc #2 // String 123
2: astore_1
3: ldc #3 // String 456
5: astore_2
6: new #4 // class java/lang/StringBuilder
9: dup
10: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V
13: aload_1
14: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
17: aload_2
18: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
21: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
24: astore_3
25: getstatic #8 // Field java/lang/System.out:Ljava/io/PrintStream;
28: aload_3
29: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
32: return
// ...
可以看到在字符串拼接过程中,是将String转成了StringBuilder后,使用append方法进行拼接字符串处理的,最后在去调用StringBuilder的toString方法进行返回。
在JDK5之后,使用的是StringBuilder,在JDK5之前使用的是StringBuffer。
知道了“+”底层之后,如果在循环中,使用“+”拼接字符串,会创建大量的StringBuilder对象,造成内存的浪费。
所以对于大量字符串拼接操作,推荐使用StringBuilder或StringBuffer以提高性能。
// 不推荐
public class StringConcatExample {
public static void main(String[] args) {
String result = "";
for (int i = 0; i < 10000; i++) {
result += i;
}
System.out.println(result.length());
}
}
// 推荐
public class StringBuilderExample {
public static void main(String[] args) {
StringBuilder result = new StringBuilder();
for (int i = 0; i < 10000; i++) {
result.append(i);
}
System.out.println(result.length());
}
}
Stringbuilder和StringBuffer是字符串拼接的两种实现类,它们有相同的父类:
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
// ...
}
StringBuffer和StringBuilder是 Java 提供的用于处理字符串的类,二者的主要区别在于线程安全性和性能方面。拿append方法举例:
StringBuilder.append方法
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
}
StringBuffer.append方法
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
由此可以看出StringBuilder和StringBuffer原理是相似的,最大的区别就是StringBuffer是线程安全的,原因是用了synchronized修饰。
StringBuffer是线程安全的,因为它的方法都是同步的,这意味着它是安全的,可以在多线程环境中使用。
由于其线程安全性,每个方法调用都有同步开销,所以StringBuffer的性能比StringBuilder稍慢。
与String类不同的是,StringBuffer和StringBuilder类的对象能够被多次的修改,并且不产生新的未使用对象。
如果你需要一个可修改的字符串,应该使用StringBuffer或者StringBuilder,但是会有大量时间浪费在垃圾回收上,因为每次试图修改都有新的String对象被创建出来。
通过StringBuilder的append()方式添加字符串的效率,要远远高于String的字符串拼接方法。
在实际开发中还可以进行优化,StringBuilder的空参构造器,默认的字符串容量是16,如果需要存放的数据过多,容量就会进行扩容,我们可以设置默认初始化更大的长度,来减少扩容的次数。
如果我们能够确定,前前后后需要添加的字符串不高于某个限定值,那么建议使用构造器创建一个阈值的长度。
基于Java8整理,如果查看其他方法请参照Java8API官方文档。
substring对字符串进行截取.返回一个新的字符串,它是此字符串的一个子字符串;
public static void main(String[] args) {
String str = "123456";
String substring = str.substring(2);
// 3456
System.out.println(substring);
// 索引从1开始截取字符串
String substring2 = str.substring(2,4);
// 34
System.out.println(substring2);
}
replace替换字符串.返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的;
public static void main(String[] args) {
String str = "123456";
// 223456
System.out.println(str.replace('1', '2'));
}
replaceAll使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串;
public static void main(String[] args) {
String str = "111111";
// 222222
System.out.println(str.replaceAll("1", "2"));
}
valueOf该方法作用是将对象转成String类型;
public static void main(String[] args) {
Integer integer = 11111;
String str = String.valueOf(integer);
// 11111
System.out.println(str);
}
Java中的String内部是用一个字符数组char[]存储字符数据的,数组的最大长度限制由Java虚拟机规范决定。
所以理论上,Java数组的最大长度是Integer.MAX_VALUE(2^31 - 1),即2147483647,这也是String的长度限制,但在实际操作中,能分配的最大数组长度受可用内存限制。
但是并不是这样,字符串字面量的长度不能超过65535字符,如果字符串字面量长度超过这个限制,编译器会抛出错误。
private void checkStringConstant(DiagnosticPosition var1, Object var2) {
if (this.nerrs == 0 && var2 != null && var2 instanceof String && ((String)var2).length() >= 65535) {
this.log.error(var1, "limit.string", new Object[0]);
++this.nerrs;
}
}
还有一点,Stirng长度之所以会受限制,是因JVM规范对常量池有所限制。
CONSTANT_Utf8_info是一个CONSTANT_Utf8类型的常量池数据项,它存储的是一个常量字符串。
常量池中的所有字面量几乎都是通过CONSTANT_Utf8_info描述的,CONSTANT_Utf8_info的定义如下:
ONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
tag:CONSTANT_Utf8_info结构的标记项值为CONSTANT_Utf8(1);length:length项的值表示字节数组中的字节数,而不是结果字符串的长度,其类型为u2;bytes[]:字节数组包含字符串的字节数;到了这里长度终于出来了,那就是length。通过查阅《JVM规范》发现u2表示两个字节的无符号数,那么1个字节有8位,2个字节就有16位。
16位无符号数可表示的最大值位2^16 - 1 = 65535。也就是说,Class文件中常量池的格式规定了,每个字符串常量的最大长度为65535字节。
所以对String的长度限制主要有两点:
Class文件中常量池的格式规定了,每个字符串常量的最大长度为65535字节;checkStringConstant方法,规定字符串字面量的长度不能超过65535字符,即最大65534个字符;所以一个字符串字面量最多可以包含65534个字符,但它的存储空间(字节数)并不会超过65535字节。
那么String类长度限制是多少?
String对象的长度理论上可以达到Integer.MAX_VALUE (2^31 - 1)个字符,即 2,147,483,647 个字符,大概4G。
在实际应用中,字符串的最大长度受限于可用内存和JVM配置;在程序开发中,如果用String变量接收Base64图片或音频视频,需要注意不要超过程序运行时字符串的最大阈值。
Java中的String类是基于Unicode字符集设计的,它可以存储任意Unicode字符。
Unicode为世界上几乎所有的字符集提供了唯一的标识码,因此Java的String类可以处理多语言字符和符号。
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。
它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
Unicode伴随着通用字符集的标准而发展,同时也以书本的形式对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。
目前最新的版本为2018年6月5日公布的11.0.0,已经收录超过13万个字符(第十万个字符在2005年获采纳)。
Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。
Unicode是一种编码规范,是为解决全球字符通用编码而设计的,而UTF-8、UTF-16等是这种规范的一种实现,Unicode是字符集而UTF-8是编码规则。
在Java虚拟机内部,String对象的存储是以UTF-16编码形式进行的。UTF-16编码是一种Unicode字符集的编码方式,它采用16位(即2个字节)编码单元来表示大部分字符,辅助字符则需要使用4个字节来表示。
不管程序过程中用到了GBK还是ISO8859-1等格式,在存储与传递的过程中实际传递的都是Unicode编码的数据,要想接收到的值不出现乱码,就要保证传过去的时候用的是X编码,接收的时候也用X编码来转换接收。
字符串的编码和解码在Java中是非常常见和重要的操作,特别是在处理文件、网络通信或与外部系统交互时。
字符串的编码和解码代码演示:
public class StringEncodingExample {
public static void main(String[] args) {
String originalString = "Hello, 你好";
String charsetName = "UTF-8";
// 编码:String -> byte[]
try {
byte[] utf8Bytes = originalString.getBytes(charsetName);
System.out.println("Encoded UTF-8 bytes: " + bytesToHex(utf8Bytes));
// 解码:byte[] -> String
String decodedString = new String(utf8Bytes, charsetName);
System.out.println("Decoded String: " + decodedString);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
// 辅助方法:将字节数组转换为十六进制字符串表示
private static String bytesToHex(byte[] bytes) {
StringBuilder sb = new StringBuilder();
for (byte b : bytes) {
sb.append(String.format("%02X ", b));
}
return sb.toString().trim();
}
}
在解码时,可能会出现乱码,原因是编码时格式和解码时格式不一致导致。 即在编码时,是用一种编码,而在解码时,用的是另一种编码,所以导致乱码问题。所以想要避免乱码问题最简单的办法就是从始至终,都用同一种字符格式。